
























Sequential Pattern Mining and GSP
- 1. Sequential Pattern Mining University of Kashan Fall 2017 Hamidreza Mahdavipanah Pegah Hajian Narges Heydarzadeh Professor: Dr. S. M. Vahidipour
- 2. Outlines ● Introduction ● Definitions ● GSP ● Constraints that GSP supports
- 3. Introduction
- 4. Studies on Sequential Pattern Mining ● First introduced by Agrawal and Srikant in 1995 ○ They presented three algorithms ■ AprioriAll ■ AprioriSome ■ DynamicSome ● Then in 1996 they presented GSP algorithm which was much faster than former algorithms and it also was generalized for more real life problems ● Pattern-growth methods: FreeSpan and PrefixSpan ● Mining closed sequential patterns: CloSpan ● ...
- 5. Applications ● Customer shopping sequences ○ First buy computer, then CD-ROM, and then digital camera, within 3 month. ● Medical treatments ● Natural disasters (e.g., earthquakes) ● Stocks and markets ● DNA sequences and gene structures
- 6. Problem Statement We are given a database D of customer transactions. Each transaction consists of the following fields: We want to find all large sequences that have a certain user-specified minimum support. It is similar to the frequent itemsets mining, but with consideration of ordering. customer-id transaction-time items
- 7. Example of a database Customer Id Transaction Time Items Bought 1 June 25 ‘93 30 1 June 30 ‘93 90 2 June 10 ‘93 10, 20 2 June 15 ‘93 30 2 June 20 ‘93 40, 60, 70 3 June 25 ‘93 30, 50, 70 4 June 25 ‘93 30 4 June 30 ‘93 40, 70 4 June 25 ‘93 90 5 June 12 ‘93 90
- 8. We convert DB to this form Customer Id Customer Sequence 1 <(30)(90)> 2 <(10 20) (30) (40 60 70)> 3 <(30 50 70)> 4 <(30) (40 70) (90)> 5 <(90)>
- 9. Definitions
- 10. Itemset and Sequence An itemset is a non-empty set of items. - We denote an itemset i by (i1 i2 … im ) A Sequence is an ordered list of items. - We denote a sequence s by <s1 s2 … sn >
- 11. Subsequence and supersequence Given two sequences α = <a1 a2 … an > and β = <b1 b2 … bm >: ● α is called a subsequence of β, if there exists integers 1 ≤ j1 < j2 < … < jn ≤ m such that a1 ⊆ b1 , a2 ⊆ b2 , …, an ⊆ bjn ● β is called a supersequence of α Example: α=<(a b) d> and β=<(a b c) (d e)>
- 12. Apriori Property of Sequential Patterns If a sequence S is not frequent, then none of the super-sequences of S is frequent. Example: <h b> is infrequent -> so do <h a b> and <(a h) b>
- 13. GSP
- 14. Outline of the GSP Method ● Initially, every item in DB is a candidate of length-1 ● For each level (i.e., sequences of length-k) do ○ Scan database to collect support count for each candidate sequence ○ Generate candidate length(k + 1) sequences from length-k frequent sequences using Apriori ○ Repeat until no frequent sequence or no candidate can be found
- 15. Major strength of GSP is its candidate pruning by Apriori property
- 16. Finding Length-1 Sequential Patterns ● Initial candidates: ○ <a>, <b>, <c>, <d>, <e>, <f>, <g>, <h> ● Scan database once, count support for candidates
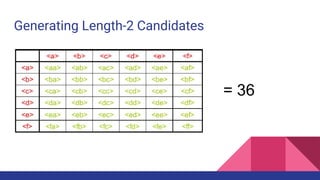
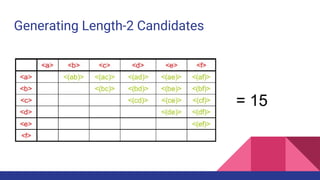
- 19. Generating Length-2 Candidates Using Apriori : 36 + 15 = 51 length-2 candidates Without Apriori : (8 * 8) + (8 * 7) / 2 = 92 length- candidates Apriori prunes 44.57% candidates
- 20. Finding Length-2 Sequential Patterns ● Scan database one more time, collect support count for each length-2 candidate ● There are 19 length-2 candidates which pass the minimum support threshold ○ They are length-2 sequential patterns
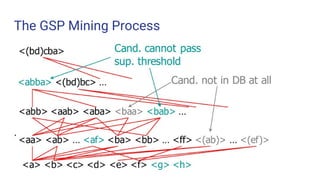
- 21. The GSP Mining Process
- 22. The GSP Algorithm ● Take sequences in form of <x> as length-1 candidates ● Scan database once, find F1 , the set of length-1 sequential patterns ● Let k = 1; while Fk is not empty do ○ Form Ck + 1 the set of length-(k + 1) candidates from Fk ○ If Ck + 1 is not empty, scan database once, find Fk + 1 , the set of length(k + 1) sequential patterns ○ Let k = k + 1
- 23. The Good, the Bad, and the Ugly ● The Good: benefits from the Apriori pruning which reduces search space ● The Bad: Scans the database multiple times ● The Ugly: Generates a huge set of candidates sequences
- 24. Why GSP is called Generalized Sequential Pattern Mining? For practical use of SPM, in 1996 Agrawal and Srikant introduced three type of constraints that makes SPM problem more general and practical and since GSP support these constraints it is called Generalized sequential pattern mining.
- 25. Constraints that GSP Supports
- 26. Time Constraint An ability for users to specify maximum and/or minimum time gaps between adjacent elements of the sequential pattern.
- 27. Sliding Window That is, each element of the pattern can be contained in the union of the items bought in a set of transactions, as long as the difference between the maximum and minimum transaction-times is less than the size of a sliding time window.
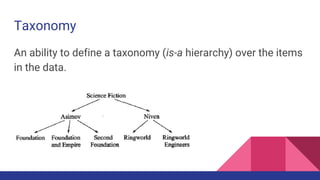
- 28. Taxonomy An ability to define a taxonomy (is-a hierarchy) over the items in the data.
- 29. References ● R. Agrawal and R. Srikant. Mining Sequential Patterns.1995 ● R. Srikant and R. Agrawal. Mining Sequential Patterns.1996 ● Jian Pei, Jiawei Han, Behzad Mortazavi-Asl, Helen Pinto, PrefixSpan: Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth. 2001