Spark + Flashblade: Spark Summit East talk by Brian Gold

Modern infrastructure and applications generate extraordinary volumes of log and telemetry data. At Pure Storage, we know this first hand: we have over 5PB of log data from production customers running our all-flash storage systems, from our engineering testbeds, and from test stations at manufacturing partners. Every part of our company — from engineering to sales — now depends on the insights we gather from this data. Given the diversity of our end users, it’s no surprise that our analysis tools comprise a broad mix of reporting queries, stream-processing operations, ad-hoc analyses, and deeper machine-learning algorithms. In this session, we will cover lessons learned from scaling our data warehouse and how we are leveraging Apache Spark’s capabilities as a central hub to meet our analytics demands.















Spark + Flashblade: Spark Summit East talk by Brian Gold
- 1. SPARK + FLASHBLADE DELIVERING INSIGHTS FROM 5PB OF PRODUCT LOGS AT PURE STORAGE Brian Gold Pure Storage
- 2. © 2017 PURE STORAGE INC. 2 ALL-FLASH STORAGE FOR DATA-INTENSIVE COMPUTING
- 3. © 2017 PURE STORAGE INC. 3 DATA POTENTIAL IS GROWING EXPONENTIALLY BIG DATA FAST DATA X
- 4. © 2017 PURE STORAGE INC. 4 DATA POTENTIAL IS GROWING EXPONENTIALLY BIG DATA FAST DATA AGILE DATA X X = DATA ADVANTAGE
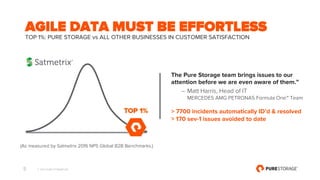
- 5. © 2017 PURE STORAGE INC. 5 AGILE DATA MUST BE EFFORTLESS TOP 1%: PURE STORAGE vs ALL OTHER BUSINESSES IN CUSTOMER SATISFACTION The Pure Storage team brings issues to our attention before we are even aware of them.” – Matt Harris, Head of IT MERCEDES AMG PETRONAS Formula One™ Team > 7700 incidents automatically ID’d & resolved > 170 sev-1 issues avoided to date (As measured by Satmetrix 2016 NPS Global B2B Benchmarks.)
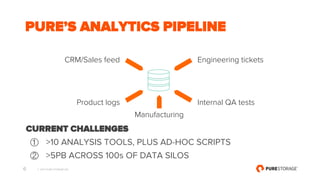
- 6. © 2017 PURE STORAGE INC. 6 PURE’S ANALYTICS PIPELINE CURRENT CHALLENGES ① >10 ANALYSIS TOOLS, PLUS AD-HOC SCRIPTS ② >5PB ACROSS 100s OF DATA SILOS Engineering tickets Internal QA tests Product logs CRM/Sales feed Manufacturing
- 7. © 2017 PURE STORAGE INC. 7 LOG ANALYSIS TODAY Raw logs (grep, awk, etc.) AD-HOC OR ENSEMBLE ANALYSIS IS TOO SLOW (OR IMPOSSIBLE) Extract & Aggregate
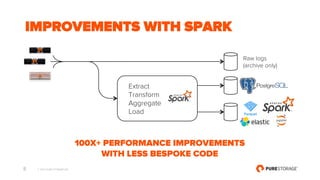
- 8. © 2017 PURE STORAGE INC. 8 IMPROVEMENTS WITH SPARK 100X+ PERFORMANCE IMPROVEMENTS WITH LESS BESPOKE CODE Raw logs (archive only) Extract Transform Aggregate Load
- 9. © 2017 PURE STORAGE INC. 9 TOOL CONSOLIDATION SPARK ENABLES WORKFLOW CONSOLIDATION • Fewer compute resources • More code reuse CHALLENGES FOR SPARK & ECOSYSTEM • Increase performance visibility for tuning partitioning and ingest flows • Improve indexing options integrated in Spark for real-time queries • Eliminating OOMs and spurious exceptions
- 10. © 2017 PURE STORAGE INC. 10 PURE’S ANALYTICS PIPELINE CURRENT CHALLENGES ① >10 ANALYSIS TOOLS, PLUS AD-HOC SCRIPTS ② >5PB ACROSS 100s OF DATA SILOS Engineering tickets Internal QA tests Product logs CRM/Sales feed Manufacturing
- 11. © 2017 PURE STORAGE INC. 11 INFRASTRUCTURE SILOS HDFS POSTGRES ELASTIC KAFKA
- 12. © 2017 PURE STORAGE INC. 12 INFRASTRUCTURE SILOS SPREAD OVER 100+ DATABASES HDFS POSTGRES ELASTIC KAFKA HDFS POSTGRES MYSQL HDFS ELASTIC POSTGRES
- 13. © 2017 PURE STORAGE INC. 13 INFRASTRUCTURE SILOS SPREAD OVER 100+ DATABASES HDFS POSTGRES ELASTIC KAFKA HDFS POSTGRES MYSQL HDFS ELASTIC POSTGRES RACKS OF EQUIPMENT, OFTEN AT LOW AVERAGE UTILIZATION
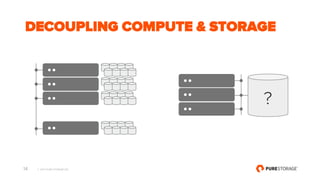
- 14. © 2017 PURE STORAGE INC. 14 DECOUPLING COMPUTE & STORAGE ?
- 15. © 2017 PURE STORAGE INC. 15 INTRODUCING FLASHBLADE ALL-FLASH FILE AND OBJECT STORAGE BIG, FAST, SIMPLE All-flash HW & SW Up to 1.6PBs, 1M NFS OPS, and 16 GB/s in each 4U chassis Designed to scale to 100s of blades FILE + OBJECT Access via multiple protocols Ideal for consolidation of applications and access patterns BLADE ELASTICITY ELASTIC FABRIC
- 16. © 2017 PURE STORAGE INC. 16 INFRASTRUCTURE CONSOLIDATION CLOUD-SCALE EFFICIENCY AND AGILITY rsyslog 1000-CORE SPARK CLUSTER ON 250TB FLASHBLADE
- 17. © 2017 PURE STORAGE INC. 17 INFRASTRUCTURE CONSOLIDATION CLOUD-SCALE EFFICIENCY AND AGILITY rsyslog 1000-CORE SPARK CLUSTER ON 250TB FLASHBLADE DENSITY: SHRINK 5 RACKS TO 1 (HDFS VS FLASHBLADE) FLEXIBILITY: SCALE COMPUTE AND STORAGE INDEPENDENTLY EFFICIENCY: CONSOLIDATE APPLICATIONS & CLUSTERS, SHARE DATA
- 18. © 2017 PURE STORAGE INC. 18 THIS IS JUST THE BEGINNING… THE FUTURE IS BRIGHT FOR SPARK + FLASHBLADE • Spark is a fast, flexible, swiss-army knife for consolidating analytics workflows • Running Spark on FlashBlade enables infrastructure consolidation and drives flexibility and efficiency for data science and supporting teams COME VISIT US AT BOOTH 208 IN THE EXPO HALL! BIG FAST SIMPLE