クラシックゲームを用いたディープラーニングの近年の発展
•
4 likes•1,386 views

クラシックゲームを用いたディープラーニングの近年の発展 第55回 Machine Learning 15minutes!(2021/5/29) https://machine-learning15minutes.connpass.com/event/211609/ における講演資料です。




































































































クラシックゲームを用いたディープラーニングの近年の発展
- 1. クラシックゲームを用いた ディープラーニングの近年の発展 三宅陽一郎 @miyayou (立教大学大学院 人工知能科学研究科) 2021.5.29 @Machine Learning 15min. https://www.facebook.com/youichiro.miyake http://www.slideshare.net/youichiromiyake y.m.4160@gmail.com miyayou.com
- 2. My Works (2004-2020) AI for Game Titles Books
- 3. はじめに
- 4. ゲームとディープラーニング 現状 • この3年間で、ゲーム産業以外で、ゲームを用いたディープ ラーニングの研究が増加している。 • 当のゲーム産業では、それ程多くない。 理由 • 強化学習(DQNなど)を研究するには、結局ルールを持つシ ミュレーション空間を使う必要がある。 • データがないところでディープラーニングを活用したい • 現実空間で応用する前に箱庭で成長させたい • ほとんどすべて研究環境がオープンソースになっている。
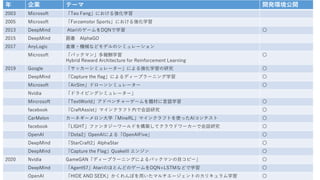
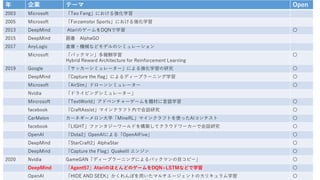
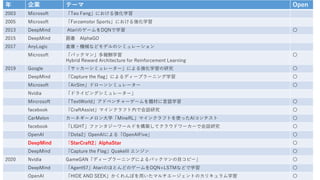
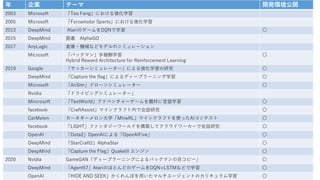
- 5. 年 企業 テーマ 開発環境公開 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
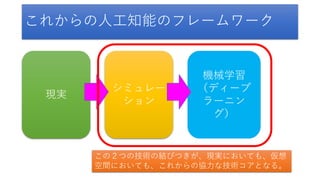
- 6. シミュレー ション これからの人工知能のフレームワーク 現実 機械学習 (ディープ ラーニン グ) この2つの技術の結びつきが、現実においても、仮想 空間においても、これからの協力な技術コアとなる。
- 7. ビックデータ x ディープラーニング から シミュレーション x ディープラーニング へ
- 13. パックマンによる研究
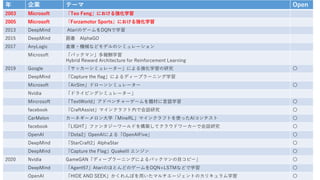
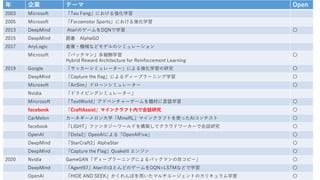
- 14. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind A tariのゲームをDQNで学習 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
- 15. ディープラーニングによるパックマンの目コピー (Nvidia, 2020) Learning to Simulate Dynamic Environments with GameGAN https://nv-tlabs.github.io/gameGAN/
- 16. Learning to Simulate Dynamic Environments with GameGAN https://nv-tlabs.github.io/gameGAN/ ディープラーニングによるパックマンの目コピー (Nvidia, 2020)
- 17. 面白い点 • 外側からだけでゲームをコピーする 問題点 • 音などはどうするのか 実用面 • クオリティ的には厳しい ディープラーニングによるパックマンの目コピー (Nvidia, 2020) Harm van Seijen, Mehdi Fatemi, Joshua Romoff, Romain Laroche, Tavian Barnes, Jeffrey Tsang “Hybrid Reward Architecture for Reinforcement Learning” https://arxiv.org/abs/1706.04208
- 18. Hybrid Reward Architecture for Reinforcement Learning (Microsoft, 2017) • 複数の報酬系を一つのニューラ ルネットワークに盛り込む。 Harm van Seijen, Mehdi Fatemi, Joshua Romoff, Romain Laroche, Tavian Barnes, Jeffrey Tsang “Hybrid Reward Architecture for Reinforcement Learning” https://arxiv.org/abs/1706.04208
- 20. 強化学習ふりかえり
- 21. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
- 22. 2000年に発行(昔はこの本しかなかった。 今はたくさんある) • Sutton先生の、森北出版「強化学習」 https://www.morikita.co.jp/books/book/1990 • は、2000年の翻訳のままで、 • 2018年に新版 • https://www.andrew.cmu.edu/course/10- 703/textbook/BartoSutton.pdf
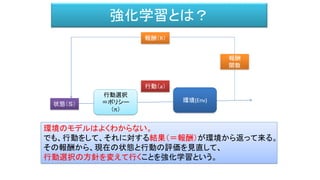
- 23. 強化学習とは • とりあえず行動してみる(ランダムでもいい) • 行動から得られるリターンによって行動の方針を変えること 自分で例を考えてみましょう。 • 初めてのコミュニティーに入る時 • 研究とか • 初めてさわるゲーム • サッカーわかんないけどとりあえず蹴ってみる • 部屋の片付け
- 25. 強化学習とは • とりあえず行動してみる(ランダムでもいい) • 行動から得られるリターンによって行動の方針を変えること • とりあえず行動してみる(ランダムでもいい) • 行動から報酬が得られる(低かろうと高かろうと) • そこから行動に対して期待される報酬の指標を設定できる A Q R
- 26. Q-Learning とは • π:Q = 各アクションで期待される報酬の指標 (意思決定:Qが一番大きいアクションを選択する) • S = State • A = Action • R = Reward • Q (s,a) という関数を決める方法
- 30. 強化学習 (例)格闘ゲーム キック パン チ 波動 R : 報酬=ダメージ http://piposozai.blog76.fc2.com/ http://dear-croa.d.dooo.jp/download/illust.html A : アクション ℚ値=0.4 ℚ値=0.5 ℚ値=0.1 ℚ : 期待される報酬
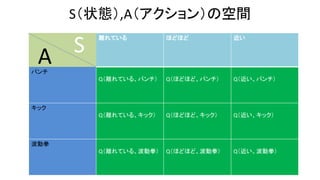
- 31. S(状態),A(アクション)の空間 離れている ほどほど 近い パンチ Q(離れている、パンチ) Q(ほどほど、パンチ) Q(近い、パンチ) キック Q(離れている、キック) Q(ほどほど、キック) Q(近い、キック) 波動拳 Q(離れている、波動拳) Q(ほどほど、波動拳) Q(近い、波動拳) A S
- 32. S(状態),A(アクション)の空間 離れている ほどほど 近い パンチ 0.7 0.6 0.9 キック 0.2 2.7 1.9 波動拳 0.1 3.5 1.1 A S
- 34. LEARNING TO FIGHT T. Graepel, R. Herbrich, Julian Gold Published 2004 Computer Science https://www.microsoft.com/en-us/research/wp-content/uploads/2004/01/graehergol04.pdf
- 35. 3 ft Q-Table THROW KICK STAND 1ft / GROUND 2ft / GROUND 3ft / GROUND 4ft / GROUND 5ft / GROUND 6ft / GROUND 1ft / KNOCKED 2ft / KNOCKED 3ft / KNOCKED 4ft / KNOCKED 5ft / KNOCKED 6ft / KNOCKED actions game states 13.2 10.2 -1.3 3.2 6.0 4.0 +10.0 Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx
- 36. Early in the learning process … … after 15 minutes of learning Reward for decrease in Wulong Goth’s health Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx
- 37. Early in the learning process … … after 15 minutes of learning Punishment for decrease in either player’s health Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx
- 39. Ralf Herbrich,Thore Graepel Applied Games Group Microsoft Research Cambridge Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" https://www.slideserve.com/liam/forza-halo-xbox-live-the-magic-of- research-in-microsoft-products
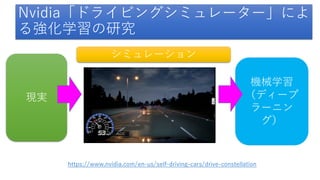
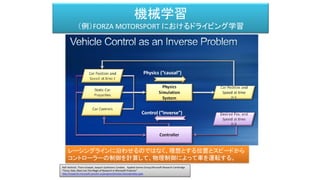
- 40. Real time racing simulation. Goal: as fast lap times as possible.
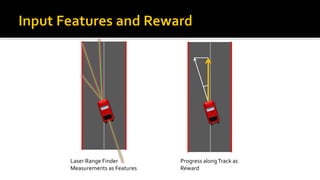
- 41. Laser Range Finder Measurements as Features Progress alongTrack as Reward
- 42. 機械学習 (例)FORZA MOTORSPORT におけるドライビング学習 Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx
- 43. 機械学習 (例)FORZA MOTORSPORT におけるドライビング学習 Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx
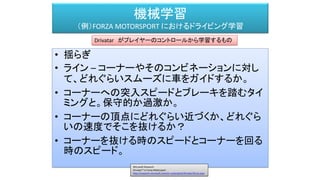
- 44. 機械学習 (例)FORZA MOTORSPORT におけるドライビング学習 • 揺らぎ • ライン – コーナーやそのコンビネーションに対し て、どれぐらいスムーズに車をガイドするか。 • コーナーへの突入スピードとブレーキを踏むタイ ミングと。保守的か過激か。 • コーナーの頂点にどれぐらい近づくか、どれぐら いの速度でそこを抜けるか? • コーナーを抜ける時のスピードとコーナーを回る 時のスピード。 Drivatar がプレイヤーのコントロールから学習するもの Microsoft Research Drivatar™ in Forza Motorsport http://research.microsoft.com/en-us/projects/drivatar/forza.aspx
- 45. 機械学習 (例)FORZA MOTORSPORT におけるドライビング学習 Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx プレイヤーの特性を解析する 特徴となる数値をドライブモデルに渡す
- 46. 機械学習 (例)FORZA MOTORSPORT におけるドライビング学習 Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx レーシングラインを事前に構築する。生成というよりテーブルから組み合わせる。
- 47. 機械学習 (例)FORZA MOTORSPORT におけるドライビング学習 Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx レーシングラインを事前に構築する。生成というよりテーブルから組み合わせる。
- 48. 機械学習 (例)FORZA MOTORSPORT におけるドライビング学習 Ralf Herbrich, Thore Graepel, Joaquin Quiñonero Candela Applied Games Group,Microsoft Research Cambridge "Forza, Halo, Xbox Live The Magic of Research in Microsoft Products" http://research.microsoft.com/en-us/projects/drivatar/ukstudentday.pptx レーシングラインに沿わせるのではなく、理想とする位置とスピードから コントローラーの制御を計算して、物理制御によって車を運転する。
- 49. Forza motorsports (EA) Jeffrey Schlimmer, "Drivatar and Machine Learning Racing Skills in the Forza Series" http://archives.nucl.ai/recording/drivatar-and-machine-learning-racing-skills-in-the-forza-series/
- 51. 年 企業 テーマ 開発環境公開 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
- 52. DQN (Deep Q network)とは
- 53. Deep Q Learning (深層強化学習) Q-Learning × Deep Learning
- 54. Q-Learning とは • Q = 期待される報酬 (意思決定関数) • S = State (座標、速度、現在の姿勢) • A = Action (キック、パンチ、波動拳) • R = 報酬 • Q (s,a ) という関数を決める方法
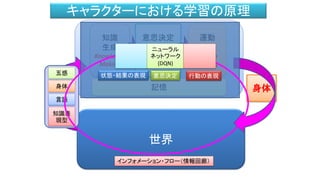
- 56. Deep Q Network (DQN)とは • Q = 予想される報酬 (意思決定関数) • S = State (座標、速度、現在の姿勢) • A = Action (キック、パンチ、波動拳) • R = 報酬 • Q (s,a ) という関数を決める方法 深層ニューラルネットワーク Deep Q Network
- 58. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
- 59. Deep Q-Learning (2013) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller (DeepMind Technologies) Playing Atari with Deep Reinforcement Learning http://www.cs.toronto.edu/~vmnih/docs/dqn.pdf 画面を入力 操作はあらかじめ教える スコアによる強化学習
- 60. 学習過程解析 Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller (DeepMind Technologies) Playing Atari with Deep Reinforcement Learning http://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
- 61. AlphaGO 膨大な棋譜のデータ (人間では多過ぎて 読めない) この棋譜を そっくり打てる ように学習する 自己対戦して 棋譜を貯める この棋譜を そっくり打てる ように学習する AlphaGO
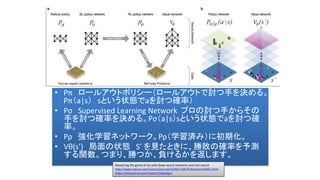
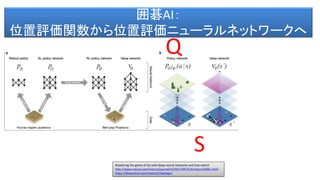
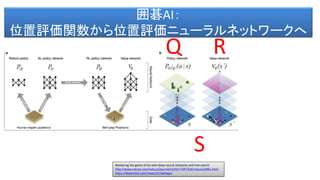
- 62. • Pπ ロールアウトポリシー(ロールアウトで討つ手を決める。 Pπ(a|s) sという状態でaを討つ確率) • Pσ Supervised Learning Network プロの討つ手からその 手を討つ確率を決める。Pσ(a|s)sという状態でaを討つ確 率。 • Pρ 強化学習ネットワーク。Pρ(学習済み)に初期化。 • Vθ(s’) 局面の状態 S’ を見たときに、勝敗の確率を予測 する関数。つまり、勝つか、負けるかを返します。 Mastering the game of Go with deep neural networks and tree search http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html https://deepmind.com/research/alphago/
- 63. 囲碁AI: 位置評価関数から位置評価ニューラルネットワークへ Mastering the game of Go with deep neural networks and tree search http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html https://deepmind.com/research/alphago/ S Q
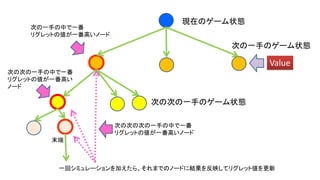
- 65. 現在の盤面の状態 負 勝率 : 4/5 勝率 : 2/5 勝率 : 3/5 基本、 乱数による プレイアウト 勝 候補となる手
- 66. W_1(=80) W_2(=70) W_3(=120) 試行回数 報酬合計 3回 2回 4回 全試行回数 9回 20ドル/回 マシン1 マシン2 マシン3 120 80 + 2 ∗ 9 80 70 40 + 2 ∗ 9 40 80 60 + 2 ∗ 9 60 UCB1 掛け金総額 60ドル 40ドル 80ドル プレイヤー
- 69. アクション・バケット 末端のノード 選択された アクション・バケット 現在のゲーム状態 Combat := if prev( wait ) then Artillery AttackOrder SpecialOrder UseGate Openings := if root then WaitUntilContact WaitUntilAmbush PuckStealth
- 70. 囲碁AI: 位置評価関数から位置評価ニューラルネットワークへ Mastering the game of Go with deep neural networks and tree search http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html https://deepmind.com/research/alphago/ S Q R
- 71. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
- 72. Deep Mind社 「Agent 57」 • Atariの古典的なゲーム57個を人間よりうまくプレイできるよう になった Deep Mind社のAI • https://deepmind.com/blog/article/Agent57-Outperforming- the-human-Atari-benchmark
- 73. DQNのさらなる発展 • 最後までスコアに苦しんだゲーム • Montezuma’s Revenge • Pitfall • Solaris • Skiing Agent57: Outperforming the human Atari benchmark (DeepMind) https://deepmind.com/blog/article/Agent57-Outperforming-the-human-Atari-benchmark
- 75. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
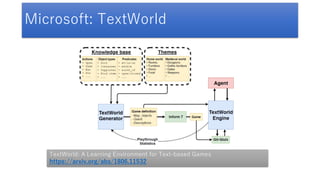
- 76. TextWorld • マイクロソフトが構築したテキストアドベンチャーの学習環境 • 50ほどのテキストアドベンチャーを内包している • TextWorld: A Learning Environment for Text-based Games • https://arxiv.org/abs/1806.11532 • • TextWorld: A learning environment for training reinforcement learning agents, inspired by text-based games • https://www.microsoft.com/en-us/research/blog/textworld-a-learning- environment-for-training-reinforcement-learning-agents-inspired-by-text- based-games/ • • Getting Started with TextWorld • https://www.youtube.com/watch?v=WVIIigrPUJs https://www.microsoft.com/en-us/research/project/textworld/
- 78. Microsoft: TextWorld TextWorld: A Learning Environment for Text-based Games https://arxiv.org/abs/1806.11532
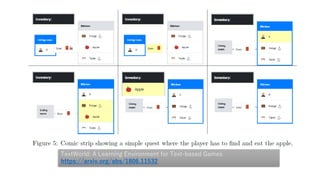
- 79. TextWorld: A Learning Environment for Text-based Games https://arxiv.org/abs/1806.11532
- 81. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
- 82. Microsoft:Malmo • エージェントを学習させる環境を提供 • https://www.microsoft.com/en-us/research/project/project-malmo/ • https://blogs.microsoft.com/ai/project-malmo-using-minecraft-build- intelligent-technology/ • チュートリアル • https://techcommunity.microsoft.com/t5/azure-ai/introducing- reinforcement-learning-on-azure-machine-learning/ba-p/1403028
- 83. facebook:「CraftAssist」(2019) • マインクラフトでプレイヤーと共同作 業可能なAIを実装するためのオープン ソースプラットフォーム https://gigazine.net/news/20190719-craftassist- collaborative-ai-minecraft/ • テキスト会話によって、エージェント (キャラクター)に意味を解釈させる。 「青い家を建てろ」など。 CraftAssist: A Framework for Dialogue-enabled Interactive Agents - Facebook Research https://research.fb.com/publications/craftassist-a-framework-for-dialogue-enabled-interactive-agents/ Open-sourcing CraftAssist, a platform for studying collaborative AI bots in Minecraft https://ai.facebook.com/blog/craftassist-platform-for-collaborative-minecraft-bots/
- 84. カーネギーメロン大学「MineRL」 • カーネギーメロン大学が NeurIPSで主催するマインクラフトを題材にした 強化学習コンテストのフレームワーク • https://ai-scholar.tech/articles/treatise/minerl-ai-353 • https://minerl.io/competition/ • https://www.aicrowd.com/challenges/neurips-2020-minerl-competition 論文 • https://arxiv.org/pdf/1907.13440.pdf • https://arxiv.org/abs/1904.10079 • https://www.microsoft.com/en-us/research/project/project-malmo/ • https://minerl.io/docs/ • https://slideslive.at/38922880/the-minerl-competition?ref=search
- 85. MineRL: A Large-Scale Dataset of Minecraft Demonstrations https://arxiv.org/pdf/1907.13440.pdf
- 87. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
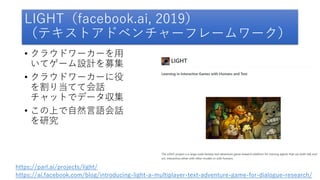
- 88. LIGHT(facebook.ai, 2019) (テキストアドベンチャーフレームワーク) • クラウドワーカーを用 いてゲーム設計を募集 • クラウドワーカーに役 を割り当てて会話 チャットでデータ収集 • この上で自然言語会話 を研究 https://parl.ai/projects/light/ https://ai.facebook.com/blog/introducing-light-a-multiplayer-text-adventure-game-for-dialogue-research/
- 89. (faceboo ai) Prithviraj Ammanabrolu, Jack Urbanek, Margaret Li, Arthur Szlam, Tim Rocktäschel, Jason Weston How to Motivate Your Dragon: Teaching Goal-Driven Agents to Speak and Act in Fantasy Worlds https://arxiv.org/abs/2010.00685
- 92. (faceboo ai) Prithviraj Ammanabrolu, Jack Urbanek, Margaret Li, Arthur Szlam, Tim Rocktäschel, Jason Weston How to Motivate Your Dragon: Teaching Goal-Driven Agents to Speak and Act in Fantasy Worlds https://arxiv.org/abs/2010.00685
- 93. (faceboo ai) Prithviraj Ammanabrolu, Jack Urbanek, Margaret Li, Arthur Szlam, Tim Rocktäschel, Jason Weston How to Motivate Your Dragon: Teaching Goal-Driven Agents to Speak and Act in Fantasy Worlds https://arxiv.org/abs/2010.00685
- 94. (faceboo ai) Prithviraj Ammanabrolu, Jack Urbanek, Margaret Li, Arthur Szlam, Tim Rocktäschel, Jason Weston How to Motivate Your Dragon: Teaching Goal-Driven Agents to Speak and Act in Fantasy Worlds https://arxiv.org/abs/2010.00685
- 96. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
- 97. 日本におけるゲームセンターの対戦文化の流れ(1980年代~) アメリカを中心とするFPS対戦の流れ(2000年前後~) 韓国におけるeスポーツ文化の流れ(1997年~) 世界的なMOBAスタイルの チーム対戦の流れ(2010年~) 1985 1990 1995 2007 ⅬAN ゲームセンターの 対戦台 インターネット 高速インターネット・動画配信 実際の現場でギャラリー観戦 テレビなどで観戦 インターネットで観戦 ゲーム聴衆 の誕生
- 98. Dota2 eSportsで大人気 OpenAI Five: Dota Gameplay https://www.youtube.com/watch?v=UZHTNBMAfAA 解説:『Dota 2』における人間側のチャンピオンチームとAIチームの戦い https://alienwarezone.jp/post/2316
- 99. OpenAI Five https://openai.com/projects/five/ Christopher Berner, et al.,“Dota 2 with Large Scale Deep Reinforcement Learning” https://arxiv.org/abs/1912.06680
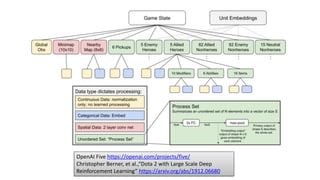
- 100. HERO ベクター 認識過程 認識情報 ベクター HERO ベクター HERO ベクター HERO ベクター 各HERO 埋め込み バリュー・ ファンクション LSTM アクション Tied Weight OpenAI Five https://openai.com/projects/five/ Christopher Berner, et al.,“Dota 2 with Large Scale Deep Reinforcement Learning” https://arxiv.org/abs/1912.06680
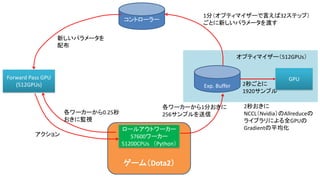
- 101. ゲーム(Dota2) コントローラー Forward Pass GPU (512GPUs) 新しいパラメータを 配布 ロールアウトワーカー 57600ワーカー 51200CPUs (Python) アクション 各ワーカーから0.25秒 おきに監視 Exp. Buffer 各ワーカーから1分おきに 256サンプルを送信 GPU 1分(オプティマイザーで言えば32ステップ) ごとに新しいパラメータを渡す 2秒ごとに 1920サンプル オプティマイザー(512GPUs) 2秒おきに NCCL(Nvidia)のAllreduceの ライブラリによる全GPUの Gradientの平均化
- 104. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
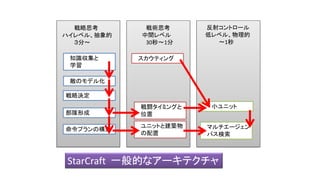
- 105. StarCraftのAI • Santiago Ontañon, Gabriel Synnaeve, Alberto Uriarte, Florian Richoux, David Churchill, et al.. • “A Survey of Real-Time Strategy Game AI Research and Competition in StarCraft”. IEEE Transactions on Computational Intelligence and AI in games, IEEE Computational Intelligence Society, 2013, 5(4), pp.1-19. hal- 00871001 • https://hal.archives-ouvertes.fr/hal-00871001
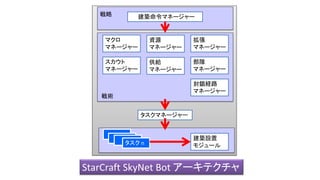
- 109. 知能 建築命令マネージャー スカウト マネージャー 資源 マネージャー マクロ マネージャー 拡張 マネージャー 供給 マネージャー 部隊 マネージャー 封鎖経路 マネージャー 戦略 戦術 タスクマネージャー 建築設置 モジュール タスク n StarCraft SkyNet Bot アーキテクチャ
- 111. StarCraft~StarCraft2における 人工知能 (DeepMind, 2019) Oriol Vinyals, et al., “StarCraft II: A New Challenge for Reinforcement Learning”, https://arxiv.org/abs/1708.04782 PySC2 - StarCraft II Learning Environment https://github.com/deepmind/pysc2
- 112. StarCraft II API StarCraft II バイナリー PySC2 エージェント アクション select_rect(p1, p2) or build_supply(p3) or … 観察 資源 可能なアクション 建築命令 スクリーン (ゲーム情報) ミニマップ (特定の情報) 報酬 -1/0/+1 SC2LE
- 113. 評価値 Value Network Baseline features アクション・タイプ ディレイ ユニット選択 命令発行 ターゲット選択 Residual MLP MLP MLP Pointer Network Attention D 分散表現 MLP 分散表現 MLP 分散表現 MLP Embedding MLP コア Deep LSTM スカラー エンコーダー MLP エンティティ エンコーダー トランス フォーマー 空間 エンコーダー ResNet ゲーム パラメーター群 エンティティ ミニマップ
- 114. Oriol Vinyals, et al., “StarCraft II: A New Challenge for Reinforcement Learning”, https://arxiv.org/abs/1708.04782 PySC2 - StarCraft II Learning Environment https://github.com/deepmind/pysc2
- 115. Oriol Vinyals, et al., “StarCraft II: A New Challenge for Reinforcement Learning”, https://arxiv.org/abs/1708.04782 PySC2 - StarCraft II Learning Environment https://github.com/deepmind/pysc2
- 117. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
- 118. シミュレーション 現実 機械学習 (ディープ ラーニン グ) https://deepmind.com/blog/article/capture-the-flag-science Human-level performance in 3D multiplayer games with population-based reinforcement learning Max Jaderberg et al. Science 31 May 2019: Vol. 364, Issue 6443, pp. 859-865 DOI: 10.1126/science.aau6249
- 119. Human-level performance in 3D multiplayer games with population-based reinforcement learning Max Jaderberg et al. Science 31 May 2019: Vol. 364, Issue 6443, pp. 859-865 DOI: 10.1126/science.aau6249
- 120. π ゲーム画像 ゲーム画像 ゲーム画像 ゲーム画像 ゲーム画像 サンプルされた 潜在変数 アクション 内部報酬 w 勝敗判定 方針 ゲーム ポイント ゆっくりとしたRNN 高速なRNN Xt 𝑄𝑡 𝑄𝑡+1 Human-level performance in 3D multiplayer games with population-based reinforcement learning Max Jaderberg et al. Science 31 May 2019: Vol. 364, Issue 6443, pp. 859-865 DOI: 10.1126/science.aau6249
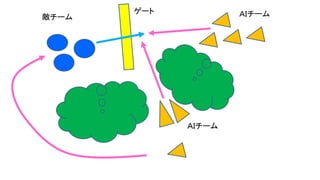
- 121. 赤チーム陣地 青チーム陣地 赤フラグを青チーム陣地に 持ち帰る青エージェント 赤フラグが赤チーム陣地に 再び自動返却されるタイミング を待つ青エージェント 赤エージェント Human-level performance in 3D multiplayer games with population-based reinforcement learning Max Jaderberg et al. Science 31 May 2019: Vol. 364, Issue 6443, pp. 859-865 DOI: 10.1126/science.aau6249
- 122. OpenAI「HIDE AND SEEK」 による学習 (2019年)
- 123. 年 企業 テーマ Open 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇
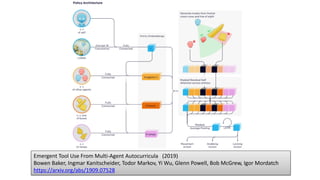
- 124. 「かくれんぼ」によってマルチエージェ ントを学習させる • オブジェクトがあって、動かしたり固 定したりできる。 • オブジェクトは直方体、傾斜台、長い 板がある。 • 一度固定したオブジェトは動かせない • エージェントは次第にオブジェクトを 利用してかくれんぼをするようになる • 6種類の戦術を順番に発見・学習して いく https://openai.com/blog/emergent-tool-use/ Emergent Tool Use From Multi-Agent Autocurricula (2019) Bowen Baker, Ingmar Kanitscheider, Todor Markov, Yi Wu, Glenn Powell, Bob McGrew, Igor Mordatch https://arxiv.org/abs/1909.07528
- 126. Emergent Tool Use From Multi-Agent Autocurricula (2019) Bowen Baker, Ingmar Kanitscheider, Todor Markov, Yi Wu, Glenn Powell, Bob McGrew, Igor Mordatch https://arxiv.org/abs/1909.07528
- 128. Project PAIDIA • マイクロソフトは、「ゲームインテリジェンスグループ」 • https://www.microsoft.com/en-us/research/theme/game-intelligence/ • を設置して30人程の研究者でゲームAIの研究をしています。 • https://www.microsoft.com/en-us/research/project/project-paidia/#!people • これまでは、チェスや囲碁、そして最近ではマインクラフトを題材にしてエージェン トの知能を作る「Project Malmo」などを推進してきましたが、 • GDC2020で「プロジェクト PAIDIA」を発表しました。 • https://innovation.microsoft.com/en-us/exploring-project-paidia • これは、Ninja Theory 社と一緒にアクションゲームでプレイヤーと強調するキャラ クターの知能を作るプロジェクトです。
- 129. • 3つの研究を柱として(かなり専門的ですが)推進しています。 • https://www.microsoft.com/en-us/research/blog/three-new-reinforcement- learning-methods-aim-to-improve-ai-in-gaming-and-beyond/ 不確定な状況下での意思決定 • https://www.microsoft.com/en-us/research/publication/conservative- uncertainty-estimation-by-fitting-prior-networks/ リアルタイムで蓄積される記憶の整備 • https://www.microsoft.com/en-us/research/publication/amrl-aggregated- memory-for-reinforcement-learning/ 不確定な状況下での強化学習 • https://www.microsoft.com/en-us/research/publication/varibad-a-very- good-method-for-bayes-adaptive-deep-rl-via-meta-learning/ Project PAIDIA
- 130. 年 企業 テーマ 開発環境公開 2003 Microsoft 「Teo Feng」における強化学習 2005 Microsoft 「Forzamotor Sports」における強化学習 2013 DeepMind AtariのゲームをDQNで学習 〇 2015 DeepMind 囲碁 AlphaGO 2017 AnyLogic 倉庫・機械などモデルのシミュレーション Microsoft 「パックマン」多報酬学習 Hybrid Reward Architecture for Reinforcement Learning 〇 2019 Google 「サッカーシミュレーター」による強化学習の研究 〇 DeepMind 「Capture the flag」によるディープラーニング学習 〇 Microsoft 「AirSim」ドローンシミュレーター 〇 Nvidia 「ドライビングシミュレーター」 Mircrosoft 「TextWorld」アドベンチャーゲームを題材に言語学習 〇 facebook 「CraftAssist」マインクラフト内で会話研究 〇 CarMelon カーネギーメロン大学「MineRL」マインクラフトを使ったAIコンテスト 〇 facebook 「LIGHT」ファンタジーワールドを構築してクラウドワーカーで会話研究 〇 OpenAI 「Dota2」OpenAIによる「OpenAIFive」 〇 DeepMind 「StarCraft2」AlphaStar 〇 DeepMind 「Capture the Flag」QuakeIII エンジン 〇 2020 Nvidia GameGAN「ディープラーニングによるパックマンの目コピー」 〇 DeepMind 「Agent57」AtariのほとんどのゲームをDQN+LSTMなどで学習 〇 OpenAI 「HIDE AND SEEK」かくれんぼを用いたマルチエージェントのカリキュラム学習 〇