Strata parallel m-ml-ops_sept_2017

Machine Learning in Production The era of big data generation is upon us. Devices ranging from sensors to robots and sophisticated applications are generating increasing amounts of rich data (time series, text, images, sound, video, etc.). For such data to benefit a business’s bottom line, insights must be extracted, a process that increasingly requires machine learning (ML) and deep learning (DL) approaches deployed in production applications use cases. Production ML is complicated by several challenges, including the need for two very distinct skill sets (operations and data science) to collaborate, the inherent complexity and uniqueness of ML itself, when compared to other apps, and the varied array of analytic engines that need to be combined for a practical deployment, often across physically distributed infrastructure. Nisha Talagala shares solutions and techniques for effectively managing machine learning and deep learning in production with popular analytic engines such as Apache Spark, TensorFlow, and Apache Flink.



















Strata parallel m-ml-ops_sept_2017
- 1. ParallelM , Strata Data 2017 The Unspoken Truths of Deploying and Scaling ML in Production Nisha Talagala CTO, ParallelM
- 2. 2Confidential Growth of Machine Learning and Deep Learning • Data growth • Easy access to scalable compute • Open source algorithms, engines and tools
- 3. 3Confidential The ML Development and Deployment Cycle • Bulk of effort today is in the left side of this process (development) • Many tools, libraries, etc. • Democratization of Data Science • Auto-ML
- 4. 4Confidential • Challenges of Production ML (and DL) • Our approach and solution • Demo • Reference designs and more info In this talk
- 5. 5Confidential • ML ‘black box’ into which many inputs (algorithmic, human, dataset etc.) go to provide output. • Difficult to have reproducible, deterministically ‘correct’ result as input data changes • ML in production may behave differently than in developer sandbox because live data ≠ training data What makes ML uniquely challenging in production? Part I : Dataset dependency
- 6. 6Confidential • Public dataset for SLA Violation detection (https://arxiv.org/pdf/1509.01386.pdf) Example Load Scenario LibSVM Accuracy Pegasos SVM Accuracy flashcrowd_load 0.843 0.915 periodic_load 0.788 0.867 constant_load 0.999 0.999 poisson_load 0.963 0.963 Load (shift) scenario LibSVM Accuracy Pegasos SVM Accuracy Flashcrowd to Periodic ACC1 0.356 0.356 ACC2 0.47 0.47 Periodic to Flashcrowd ACC1 0.826 0.558 ACC2 0.766 0.805 When trained to right dataset, both algorithms do well. When dataset switches, accuracy suffers in (algorithm specific) ways • ACC1- load 2 load only • ACC2 – both loads
- 7. 7Confidential • Retraining required to keep up with changing data - manage training & inference pipelines in parallel • Feature engineering pipelines must match for Training and Inference • Pipelines need to be orchestrated factoring in such dependencies • Further complexity if ensembles etc. are used What makes ML uniquely challenging in production? Part II : Training/Inference
- 8. 8Confidential • Possibly differing engines (Spark, TensorFlow, Caffe, PyTorch, Sci-kit Learn, etc. ) • Different languages (Python, Java, Scala, R ..) • Inference vs Training engines • Training can be frequently batch • Inference (Prediction, Model Serving) can be REST endpoint/custom code, streaming engine, micro-batch, etc. • Feature manipulation done at training needs to be replicated (or factored in) at inference What makes ML uniquely challenging in production? Part III : Heterogeneity in Training/Inference
- 9. 9Confidential Collaboration: • Expertise mismatch between Data Science & Ops complicates handoff and continuous management and optimization Process: • Many objects to be tracked and managed (algorithms, models, pipelines, versions etc.) • Emerging requirements for reproducibility, process audit etc. What makes ML uniquely challenging in production? Part IV : Collaboration, Process
- 10. 10Confidential What we need • Accelerate deployment & facilitate collaboration between Data & Ops teams • Monitor validity of ML predictions, diagnose data and ML performance issues • Orchestrate training, update, and configuration of ML pipelines across distributed, heterogeneous infrastructure with tracking
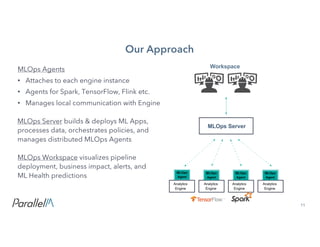
- 11. 11Confidential Our Approach MLOps Workspace visualizes pipeline deployment, business impact, alerts, and ML Health predictions MLOps Agents • Attaches to each engine instance • Agents for Spark, TensorFlow, Flink etc. • Manages local communication with Engine MLOps Server builds & deploys ML Apps, processes data, orchestrates policies, and manages distributed MLOps Agents Workspace Analytics Engine Analytics Engine Analytics Engine Analytics Engine MLOps Server MLOps Agent MLOps Agent MLOps Agent MLOps Agent
- 12. 12Confidential • Link pipelines (training and inference) via an “Intelligence Overlay Network (ION)” • Basically a Directed Graph representation with allowance for cycles •Pipelines are DAGs within each engine • Distributed execution over heterogeneous engines, programming languages and geographies Operational Abstraction Always Update Example – KMeans Batch Training Plus Streaming Inference Anomaly Detection
- 13. 13Confidential Integrating with Analytics Engines (Spark) - Examples • Job Management • Via SparkLauncher: A library to control launching, monitoring and terminating jobs • PM Agent communicates with Spark through this library for job management (also uses Java API to launch child processes) • Statistics • Via SparkListener: A Spark-driver callback service • SparkListener taps into all accumulators which, is one of the popular ways to expose statistics • PM agent communicates with the Spark driver and exposes statistics via a REST endpoint • ML Health / Model collection and updates • PM Agent delivers and receives health events, health objects and models via sockets from custom PM components in the ML Pipeline
- 14. 14Confidential Integrating with Analytics Engines (TensorFlow) - Examples • Job Management • TensorFlow Python programs run as standalone applications • Standard process control mechanisms based on the OS is used to monitor and control TensorFlow programs • Statistics Collection • PM Agent parses contents via TensorBoard log files to extract meaningful statistics and events that data scientists added • ML Health / Model collection • Generation of models and health objects is recorded on a shared medium
- 16. 16Confidential DEMO Configuration • MLOps Server (3 nodes) • MLOps Agent + Spark Engine (1 node) • MLOps Agent + Flink Engine (1 node) • MLOPs Center FlinkSpark NFS Dataset : Training: 10 attributes, 600K samples Inference: A: 1Mil samples @~1K samples/sec B: 1Mil samples @~1K samples/sec MLOps Server MLOps Agent MLOps Agent MLOps Workspace
- 17. 17Confidential Demo example use case: Anomaly Detection HDFS Feature Engineering K-Means (Training) Saved Model (PMML) K-Means Anomaly Detection Multivariate Anomaly Detection Feature Engineering Kafka Always Update
- 18. 18Confidential Demo Baseline K- Means Training Anomaly Detection K-Means ML Ops Server NFS / HDFS Feeder ML Ops Center Spark - Batch Flink - Streaming Inference samples Anomalous Inference samples • ION launched and run • MLOps Center orchestrates Spark and Flink pipelines • Spark training pipeline periodically generates new trained models • Trained models are sent to and updated into inference pipeline . Model We use a “feeder” program to send in different datasets into the above flow to generate various event types and show MLOps Center features
- 19. 19Confidential • Image recognition use cases in security, retail etc. • Utilizing DL algorithms with TensorFlow 1.3 and Flink • Hardware configuration optimized for accelerated distributed training with support for leading tools and frameworks right out of the box • The ability to rapidly move to and manage in production while ensuring ML prediction quality in a dynamic environment High Performance Deep Learning in Production Reference Design: Mellanox and ParallelM https://community.mellanox.com/docs/DOC-3001
- 20. 20Confidential For more information http://www.parallelm.com/ “Deploying A Scalable Deep Learning Solution in Production with Tensorflow: A Reference Design with Mellanox and ParallelM” https://community.mellanox.com/docs/DOC-3001 “TensorFlow: Tips for Getting Started” at ParallelM booth at Strata and online Reference design for Edge/Cloud ML https://www.linkedin.com/pulse/showcasing- edgecloud-machine-learning-management-mec-2017- das/?trackingId=nuAps6ixyIcobHNJbnHe5g%3D%3D Examples of Spark and Flink scaling with Online ML algorithms: http://sf.flink- forward.org/kb_sessions/experiences-with-streaming-vs-micro-batch-for-online- learning/ New O-Reilly book: “Deep Learning with TensorFlow"