


















Support vector machine
- 1. zekeLabs Support Vector Machines Learning made Simpler ! www.zekeLabs.com
- 2. Agenda ● Introduction to SVM ● Advantages & Disadvantages of SVM ● Classification Algo using SVM ● Linearly Separable Data ● Non linearly separable Data ● Understanding Kernels ● Gamma & C for RBF kernel ● Unbalanced Data ● Regression using SVM ● Kernels in Regression ● Novelty Detection ● Additional ● Applications
- 3. Introduction to Support Vector Machine ● First developed in the mid-1960s by Vladimir Vapnik. Support Vector Machine Classification Regression Outlier Detection
- 4. Advantages of SVM ● Effective in high dimensional spaces. ● Where number of dimensions is greater than the number of samples. ● Uses a subset of training points in the decision function (called support vectors), so it is also memory efficient. ● Versatile: different Kernel functions can be specified for the decision function. Common kernels are provided, but it is also possible to specify custom kernels.
- 5. Disadvantages of SVM ● Very sensitive to hyper-parameters ● Different kernels needs different parameters ● SVMs do not directly provide probability estimates, these are calculated using an expensive five-fold cross-validation
- 7. Algo ● This algorithm looks for a linearly separable hyperplane, or a decision boundary separating members of one class from the other. ● If such a hyperplane does not exist, SVM uses a nonlinear mapping to transform the training data into a higher dimension. Then it searches for the linear optimal separating hyperplane. ● With an appropriate nonlinear mapping to a sufficiently high dimension, data from two classes can always be separated by a hyperplane. ● The SVM algorithm finds this hyperplane using support vectors and margins.
- 8. Linearly Separable Data ● Among the infinite straight lines possible to separate the red from blue balls, find the optimal one. ● Intuitively it is clear that if a line passes too close to any of the points, that line will be more sensitive to small changes in one or more points. ● Hyperplane Generalization
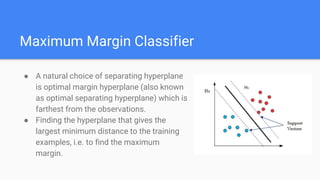
- 9. Maximum Margin Classifier ● A natural choice of separating hyperplane is optimal margin hyperplane (also known as optimal separating hyperplane) which is farthest from the observations. ● Finding the hyperplane that gives the largest minimum distance to the training examples, i.e. to find the maximum margin.
- 10. Soft-margin Classifier ● Maximum margin classifier may not practically exist. ● Extending maximum margin to a soft-margin, a small amount of data is allowed to cross margins or even the separating hyperplanes. ● Support Vector Machine maximizes the soft margin. ● C parameter leads to larger penalty for errors & thus inversely proportional to soft margin.
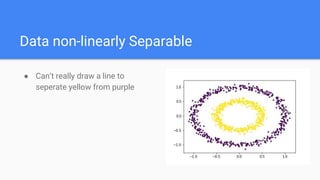
- 11. Data non-linearly Separable ● Can’t really draw a line to seperate yellow from purple
- 12. Data non-linearly Separable ● If such a hyperplane does not exist, SVM uses a nonlinear mapping to transform the training data into a higher dimension. ● Transformation , Z = X^2 + Y^2 ● Now, we see a plane exists separating them both
- 13. Kernels ● We don’t have to do the transformation manually. ● This is done by kernel tricks Kernel Tricks Linear Poly RBF Custom
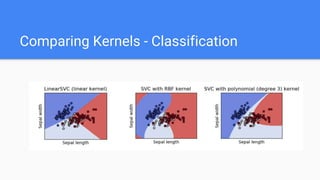
- 14. Comparing Kernels - Classification
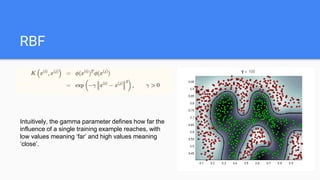
- 15. RBF Intuitively, the gamma parameter defines how far the influence of a single training example reaches, with low values meaning ‘far’ and high values meaning ‘close’.
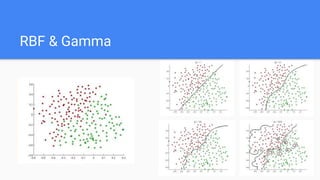
- 16. RBF & Gamma
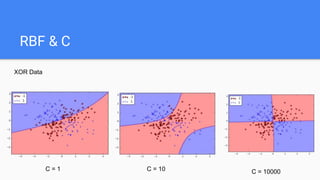
- 17. RBF & C ● The C parameter trades off misclassification of training examples against simplicity of the decision surface. ● A low C makes the decision surface smooth, while a high C aims at classifying all training examples correctly by giving the model freedom to select more samples as support vectors.
- 18. RBF & C XOR Data C = 1 C = 10 C = 10000
- 19. RBF - Gamma & C
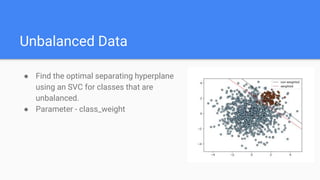
- 20. Unbalanced Data ● Find the optimal separating hyperplane using an SVC for classes that are unbalanced. ● Parameter - class_weight
- 22. Foundations ● y = f(x) + noise ● This can be achieved by training the SVM model on a sample set, i.e., training set, a process that involves sequential optimization of an error function.
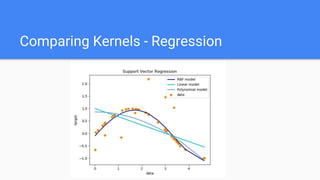
- 23. Comparing Kernels - Regression
- 24. Novelty Detection using SVM
- 25. One Class SVM ● The training data is not polluted by outliers, and we are interested in detecting anomalies in new observations. ● One-class SVM is an unsupervised algorithm that learns a decision function for novelty detection: classifying new data as similar or different to the training set.
- 26. Additional : Custom Kernel ● You can also use your own defined kernels by passing a function to the keyword kernel in the constructor.
- 28. Thank You !!!
- 29. Visit : www.zekeLabs.com for more details THANK YOU Let us know how can we help your organization to Upskill the employees to stay updated in the ever-evolving IT Industry. Get in touch: www.zekeLabs.com | +91-8095465880 | info@zekeLabs.com