


















Big Data Day LA 2015 - What's new and next in Apache Tez by Bikas Saha of Hortonworks
- 1. Page1 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Apache Tez Bikas Saha @bikassaha
- 2. Page2 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Apache Hadoop YARN and HDFS Flexible Enables other purpose-built data processing models beyond MapReduce (batch), such as interactive and streaming Efficient Double processing IN Hadoop on the same hardware while providing predictable performance & quality of service Shared Provides a stable, reliable, secure foundation and shared operational services across multiple workloads The Data Operating System for Hadoop 2.x Data Processing Engines Run Natively IN Hadoop BATCH MapReduce LOG STORE Kafka STREAMING Storm IN-MEMORY Spark GRAPH Giraph SAS LASR, HPA ONLINE HBase, Accumulo OTHERS HDFS: Redundant, Reliable Storage YARN: Cluster Resource Management
- 3. Page3 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Tez •API’s and libraries to create data processing applications on YARN •Customizable and adaptable DAG definition •Orchestration framework to execute the DAG in a Hadoop cluster •NOT a general purpose execution engine Open Source Apache Project
- 4. Page4 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Tez – Goals • Tez solves the hard problems of running on a distributed Hadoop environment • Apps can focus on solving their domain specific problems • Tez instantiates the physical execution structure. App fills in logic and behavior • API targets data processing specified as a data flow graph App Tez • Custom application logic • Custom data format • Custom data transfer technology • Distributed parallel execution • Negotiating resources from the Hadoop framework • Fault tolerance and recovery • Shared library of ready-to-use components • Built-in performance optimizations • Hadoop Security
- 5. Page5 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Tez – Adoption • Apache Hive – Most popular SQL-like interface for data in Hadoop • Apache Pig – Scripting language used in some of the largest Hadoop installations • Apache Flink (Stratosphere project from TU Berlin) – General purpose engine with language integrated data processing API • Cascading + Scalding – Language integrated data processing API in Java/Scala • Commercial Products – Datameer, Syncsort and other in progress
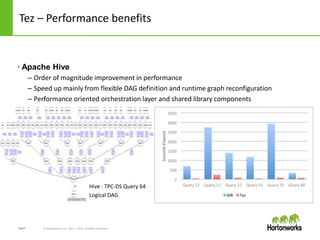
- 6. Page6 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Tez – Performance benefits • Apache Hive – Order of magnitude improvement in performance – Speed up mainly from flexible DAG definition and runtime graph reconfiguration – Performance oriented orchestration layer and shared library components Hive : TPC-DS Query 64 Logical DAG
- 7. Page7 © Hortonworks Inc. 2011 – 2014. All Rights Reserved Tez – Scale and Reliability • Apache Pig – Predominant number of data processing jobs at Yahoo with up to 5000 node clusters – Multi-Petabyte jobs – On track for using Pig with Tez for all production Pig jobs – Already use Hive with Tez for large scale analytics • Hortonworks customers – All new customers default on Hive with Tez • Cascading + Scalding – Cascading 3.0 released with Tez integration – Very promising results with beta users http://scalding.io/2015/05/scalding-cascading-tez-♥/
- 8. © Hortonworks Inc. 2013 Tez – DAG API // Define DAG DAG dag = DAG.create(); // Define Vertex Vertex Scan1 = Vertex.create(Processor.class); // Define Edge Edge edge = Edge.create(Scan1, Partition1, SCATTER_GATHER, PERSISTED, SEQUENTIAL, Output.class, Input.class); // Connect them dag.addVertex(Scan1).addEdge(edge)…. Page 8 Defines the global logical processing flow Scan1 Scan2 Partition1 Partition2 Join Scatter Gather Scatter Gather
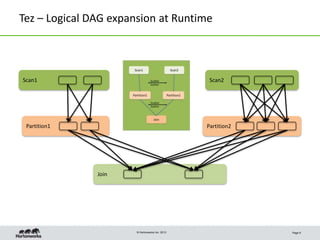
- 9. © Hortonworks Inc. 2013 Tez – Logical DAG expansion at Runtime Page 9 Partition1 Scan2 Partition2 Join Scan1
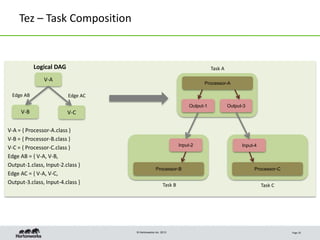
- 10. © Hortonworks Inc. 2013 Tez – Task Composition Page 10 V-A V-B V-C Logical DAG Output-1 Output-3 Processor-A Input-2 Processor-B Input-4 Processor-C Task A Task B Task C Edge AB Edge AC V-A = { Processor-A.class } V-B = { Processor-B.class } V-C = { Processor-C.class } Edge AB = { V-A, V-B, Output-1.class, Input-2.class } Edge AC = { V-A, V-C, Output-3.class, Input-4.class }
- 11. © Hortonworks Inc. 2013 Tez – Composable Task Model Page 11 Hive Processor HDFS Input Remote File Server Input HDFS Output Local Disk Output Custom Processor HDFS Input Remote File Server Input HDFS Output Local Disk Output Custom Processor RDMA Input Native DB Input Kakfa Pub-Sub Output Amazon S3 Output Adopt Evolve Optimize
- 12. © Hortonworks Inc. 2013 Tez – Customizable Core Engine Page 12 Vertex-2 Vertex-1 Start vertex Vertex Manager Start tasks DAG Scheduler Get Priority Get Priority Start vertex Task Scheduler Get container Get container • Vertex Manager • Determines task parallelism • Determines when tasks in a vertex can start. • DAG Scheduler Determines priority of task • Task Scheduler Allocates containers from YARN and assigns them to tasks
- 13. © Hortonworks Inc. 2013 Tez – Customizable core engine: graph reconfiguration Page 14 Vertex 1 tasks Vertex 2 Input Data App Master Input Initializer + Vertex Manager Filtering values Vertex State Machine Reconfigure Vertex Apply Filter to Prune Input Partitions Event Model Map tasks send data statistics events to the Reduce Vertex Manager. Vertex Manager Pluggable application logic that understands the data statistics and can formulate the correct parallelism. Advises vertex controller on parallelism Hive – Dynamic Partition Pruning
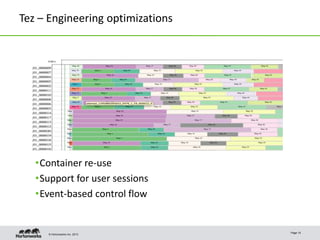
- 14. © Hortonworks Inc. 2013 Tez – Engineering optimizations •Container re-use •Support for user sessions •Event-based control flow Page 15
- 15. © Hortonworks Inc. 2013 Tez – Developer tools – Local Mode • Fast prototyping – no hadoop setup required • Quick turnaround in Unit testing – no overheads for allocating resources , launching JVM’s. • Easy debuggability – Single JVM • Scheduling / RPC invocations skipped Page 16
- 16. © Hortonworks Inc. 2013 Tez – Developer Tools - Tez UI • View Status and progress of DAG/Vertex • Diagnostics on failure • View counters for DAG/Vertex • View and compare counters across tasks/attempts • View app specific information Page 17
- 17. © Hortonworks Inc. 2013 Tez – Developer Tools - Tez UI Page 18
- 18. © Hortonworks Inc. 2013 Tez – Job Analysis tools - Swimlanes • “$TEZ_HOME/tez-tools/swimlanes/yarn-swimlanes.sh <app_id>” Page 19
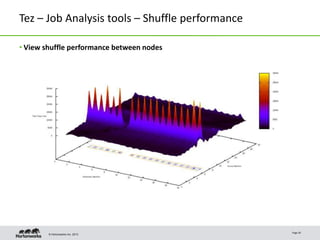
- 19. © Hortonworks Inc. 2013 Tez – Job Analysis tools – Shuffle performance • View shuffle performance between nodes Page 20
- 20. © Hortonworks Inc. 2013 Tez – Job Analysis tools – Shuffle performance • View shuffle performance between nodes Page 21
- 21. © Hortonworks Inc. 2013 Tez – Hybrid Execution Page 22 • Run “compute where its most efficient” • Building on the pluggable design of Tez, different vertices in the DAG can run in different execution environments • Hive LLAP daemons can run initial scans, map joins etc. while large joins can run in YARN containers • Best of both worlds and the pattern can be repeated for Apache Phoenix or your MPP database MPP Daemon MPP Daemon MPP Daemon MPP Daemon MPP Daemon MPP Daemon Vertex 1 Vertex 2 Vertex 3 YARNYARN YARN Join Scan/Filter
- 22. © Hortonworks Inc. 2013 Tez – How can you help? •Improve core Tez infrastructure – Apache open source project. Your use cases and code are welcome •Port DB ideas to Hive+Tez world – Evolve distributed query optimization and execution •Use Tez hybrid execution – Use the Hive-LLAP pattern to get the best of both worlds with your execution environment •Integrate your project with Tez – Get benefits similar to Hive, Pig, Cascading, Flink. Takes between 1-6 months depending on the complexity of the target project
- 23. © Hortonworks Inc. 2013 Tez – How to contribute •Useful links – Work tracking: https://issues.apache.org/jira/browse/TEZ – Code: https://github.com/apache/tez – Developer list: dev@tez.apache.org User list: user@tez.apache.org Issues list: issues@tez.apache.org
- 24. © Hortonworks Inc. 2013 Tez Thanks for your time and attention! Video with Deep Dive on Tez http://goo.gl/BL67o7 http://www.infoq.com/presentations/apache-tez Questions? @bikassaha Page 25
Editor's Notes
- TODO: Rohit compile list of current apps out there and 1-2 sentences on what they do for the notes here The first wave of Hadoop was about HDFS and MapReduce where MapReduce had a split brain, so to speak. It was a framework for massive distributed data processing, but it also had all of the Job Management capabilities built into it. The second wave of Hadoop is upon us and a component called YARN has emerged that generalizes Hadoop’s Cluster Resource Management in a way where MapReduce is NOW just one of many frameworks or applications that can run atop YARN. Simply put, YARN is the distributed operating system for data processing applications. For those curious, YARN stands for “Yet Another Resource Negotiator”. [CLICK] As I like to say, YARN enables applications to run natively IN Hadoop versus ON HDFS or next to Hadoop. [CLICK] Why is that important? Businesses do NOT want to stovepipe clusters based on batch processing versus interactive SQL versus online data serving versus real-time streaming use cases. They're adopting a big data strategy so they can get ALL of their data in one place and access that data in a wide variety of ways. With predictable performance and quality of service. [CLICK] This second wave of Hadoop represents a major rearchitecture that has been underway for 3 or 4 years. And this slide shows just a sampling of open source projects that are or will be leveraging YARN in the not so distant future. For example, engineers at Yahoo have shared open source code that enables Twitter Storm to run on YARN. Apache Giraph is a graph processing system that is YARN enabled. Spark is an in-memory data processing system built at Berkeley that’s been recently contributed to the Apache Software Foundation. OpenMPI is an open source Message Passing Interface system for HPC that works on YARN. These are just a few examples.
- For anyone who has been working on MapReduce, there is this age-old problem around “how do I figure out the correct number of reducers?”. We guess some number at compile-time and usually that turns out to be incorrect at run-time. Let’s see how we can use the Tez model to fix that. So here is this Map Vertex and this Reduce Vertex, which have these tasks running and you have the Vertex Manager running inside the framework … [CLICK] The Map Tasks can send Data Size Statistics to the Vertex Manager, which can then extrapolate those statistics to figure out “what would be the final size of the data when all of these Maps finish?”. Based on that, it can realize that the data size is actually smaller than expected, and I can actually run two reduce tasks instead of three. [CLICK] The Vertex Manager sends a Set Paralellism command to the framework which changes the routing information in-between these two tasks and also cancels the last task.
- For anyone who has been working on MapReduce, there is this age-old problem around “how do I figure out the correct number of reducers?”. We guess some number at compile-time and usually that turns out to be incorrect at run-time. Let’s see how we can use the Tez model to fix that. So here is this Map Vertex and this Reduce Vertex, which have these tasks running and you have the Vertex Manager running inside the framework … [CLICK] The Map Tasks can send Data Size Statistics to the Vertex Manager, which can then extrapolate those statistics to figure out “what would be the final size of the data when all of these Maps finish?”. Based on that, it can realize that the data size is actually smaller than expected, and I can actually run two reduce tasks instead of three. [CLICK] The Vertex Manager sends a Set Paralellism command to the framework which changes the routing information in-between these two tasks and also cancels the last task.