The Marriage of the Data Lake and the Data Warehouse and Why You Need Both

In the past few years, the term "data lake" has leaked into our lexicon. But what exactly IS a data lake? Some IT managers confuse data lakes with data warehouses. Some people think data lakes replace data warehouses. Both of these conclusions are false. Their is room in your data architecture for both data lakes and data warehouses. They both have different use cases and those use cases can be complementary. Todd Reichmuth, Solutions Engineer with Snowflake Computing, has spent the past 18 years in the world of Data Warehousing and Big Data. He spent that time at Netezza and then later at IBM Data. Earlier in 2018 making the jump to the cloud at Snowflake Computing. Mike Myer, Sales Director with Snowflake Computing, has spent the past 6 years in the world of Security and looking to drive awareness to better Data Warehousing and Big Data solutions available! Was previously at local tech companies FireMon and Lockpath and decided to join Snowflake due to the disruptive technology that's truly helping folks in the Big Data world on a day to day basis.






















The Marriage of the Data Lake and the Data Warehouse and Why You Need Both
- 1. 1 todd.reichmuth@snowflake.com Solution Engineering Data Marriage of the Lake and Warehouse (why you need both)
- 2. 2 Data Lake a place to store ALL (not only structured) data in native format that can inexpensively grow without limits and can exist until the end of time Data Warehouse a place to store “enhanced” data that is integrated, governed, cleansed, and well defined. Typically the data is multi-dimensional, historical, and non-volatile. Data Mart a subset of the data warehouse, oriented to a specific business line or team. Big Data Data characterized by the 3 (sometimes up to 5) V’s. Volume (high), Velocity (near real time), Variety (everything), Veracity (trustworthy), Value (actionable insights) Usually satisfied by Data Lake, sometimes by Data Warehouse Let’s agree on terminology 2
- 3. 3 In the beginning, ”analytics” were run against operational systems. This led to single purpose decision support systems. It became apparent that this was not sustainable. Siloed environments caused multiple interpretations of the truth, duplicated effort, high cost, and slow time to value. An enterprise solution was needed. • 1979 – Bill Inmon introduces the term Data Warehouse • 1983 – Teradata introduces DBC/1012 specifically designed for decision support • 1986 – Ralph Kimball founds Red Brick Systems • 1988 – IBM publishes an article introducing the term “Business Data Warehouse” • 1992 – Bill Inmon publishes a book ”Building the Data Warehouse” • 1996 – Ralph Kimball publishes a book “The Data Warehouse Toolkit” Evolution of the Data warehouse
- 4. 4 Data Warehouse architecture in the early days OLTP System ERP CRM Data Warehouse Flat Files ETL OLAP Reporting Mining
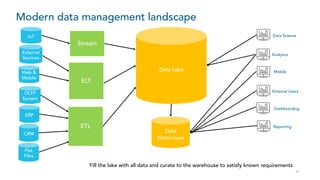
- 5. 5 Data warehouse architecture evolution OLTP System ERP CRM Data Warehouse Flat Files ETL Dashboarding Reporting Analytics Data Science External Users Data Warehouse ??? Data Warehouse ??? Web & Mobile External Sources IoT ELT Stream MobileXML / JSON High Volume Low Latency Data velocity increasing (machine generated + IoT) and in new shapes and sizes. Silo’ing of data came back in different ways. Less tolerance for long analytical cycles. The existing data warehouse could not support this evolution. Structured High Performance
- 6. 6 2010 – James Dixon CTO Pentaho “If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.” Emergence of the Data lake
- 7. 7 Big Data V’s: Warehouse & Lake comparison 7 Data warehouse Data lake Volume Expensive for large data, capacity is often capped Low cost and high capacity Variety Structured Schema on write Structured, semi-structured, unstructured Schema on read Velocity Batch ETL/ELT Hourly or daily latency Streaming Near real time Veracity Highly curated, governed. Source of truth Raw, uncleansed data. Source of fact Value Measure things, detect trends Q: What has worked well? Find relationships, make predictions Q: What will work well?
- 8. 8 Absolutely not (in most cases) !!! They each fulfill a different purpose. Each is optimized for different users, skills, workloads, and service level agreements. The data lake is an “exploratory” layer with low data latency and no preconceived boundaries on how data will be used. Perfect for data scientists and those willing to do their own data preparation and discovery. A data warehouse is a trusted and curated layer for making “bet your career” decisions. Loved by business professionals. Built for easy consumption and ready to publish. Can the data lake eliminate the warehouse?
- 9. 9 • Certain users need/want data in a way the warehouse can best provide • Integrated • Subject oriented • Curated • Time variant • Relational • Ready to consume • Data may need to be enhanced to support particular user needs • Some business functions will require high performance, high concurrency • Enterprise level historical data needs to be carefully managed Why a Lake should not replace a Warehouse
- 10. 10 Modern data management landscape OLTP System ERP CRM Data Warehouse Flat Files ETL Dashboarding Reporting Analytics Data Science External Users Data Lake Web & Mobile External Sources IoT ELT Stream Mobile Fill the lake with all data and curate to the warehouse to satisfy known requirements
- 11. 11 Building the modern data management environment Start filling the lake Low cost pure capture environment Built separate from core IT Data is stored raw Stage 1 Landing zone for raw data Stage 2 Data science environment Stage 3 Offload for data warehouse Stage 4 Key component of data operations Actively used as platform for experimentation Test and learn environment Data scientist given access Governance = “just enough” Large datasets, low intensity workload moved to lake Needle in the haystack searches that do not require indexes Lake becomes a source for EDW Lake becomes core part of data management Attempt to enforce strong governance and tight security
- 12. 12 Data Warehouse • SMP or MPP • Popularity of the appliance • In some cases Hadoop • Oracle, Teradata, Netezza, Vertica, Redshift, etc. Data Lake • File system with abstraction • Hadoop, Amazon S3, Azure Data Lake Storage, Google Cloud Storage Technology tools of choice 1 Can a single technology platform fulfill the needs of both data management frameworks?
- 13. 13 Lake • Cheap and plentiful storage • Ability to handle all data types • Optimized for ingestion Warehouse • Supports commonly used tools • Handles high concurrency • Reliable, Available, Stable • Data protection (secure & recoverable) Desirable capabilities • Low administration • Support for multi-tenant/concurrency • Easily scale up/down, in/out • Low total cost of ownership • No paying for unused capacity • Sharing of data with external entities Technical requirements to satisfy both frameworks
- 14. 1414 Modern data management architecture SMP Shared-disk MPP Shared-nothing Single Server Resizing cluster requires redistributing data. Impact to user. Reads/Writes at the same time cripples the system Each cluster requires its own copy of data (ex: test/dev, HA) Replication requires additional hardware Processes needed to maintain sort and distribution for performance Resizing cluster requires redistributing data. Impact to user. Traditional architectures © 2018 Snowflake Computing Inc. All Rights Reserved. Cloud based, Multi-cluster, shared data Centralized, elastic storage Multiple, Independent compute clusters Unlimited storage and compute, scaled independently gives flexibility
- 15. 15 Cloud-based architecture for big data analytics Data Warehousing Cloud Service Separated Storage, Compute, & Metadata, Global Services One Compute cluster, multiple Databases One Database, multiple Compute clusters Compute clusters scale independently Multi-Cluster compute farms support high concurrency Workloads don't compete with each other Compute cluster Compute cluster Compute cluster Compute cluster Compute cluster S S M XXLL Database Compute cluster Sales Users Data Scientist Finance Users ETL & ELT Services Test/Dev Users Marketing Users XL s Metadata Azure Data Factory
- 16. 1616 Relational database extended to semi-structured data > SELECT … FROM …Semi-structured data (JSON, Avro, XML, Parquet, ORC) Structured data (e.g., CSV, TSV, …) Storage optimization Transparent discovery and storage optimization of repeated elements Query optimization Full database optimization for queries on semi-structured data +
- 17. 1717© 2018 Snowflake Computing Inc. All Rights Reserved. Streaming and Batch Loading Data Sources Web Servers Cloud Storage On Premises Data Lake BI Tools Apps Source Raw Data Augmented Data Snowflake Database S3 S3 Transformation Transformation Kafka/Kinesis COPY PUT + COPY Snowpipe REST API Azure Blob GCS Azure Blob
- 18. 18 A better way to share data Data Providers Data Consumers No data movement Share with unlimited number of consumers Live access Data consumers immediately see all updates Ready to use Consumers can immediately start querying
- 19. 1919 Near Zero Administration NO Infrastructure NO Tuning NO Upgrades/Patches NO Indexing NO Storage worries NO Reorg/Vacuuming NO Partitioning NO Stats gathering NO Workload mgmt. NO Manual backups
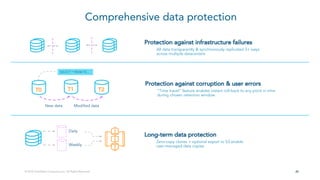
- 20. 2020 Comprehensive data protection Protection against infrastructure failures All data transparently & synchronously replicated 3+ ways across multiple datacenters Long-term data protection Zero-copy clones + optional export to S3 enable user-managed data copies Protection against corruption & user errors “Time travel” feature enables instant roll-back to any point in time during chosen retention window New data Modified data T0 T1 T2 SELECT * FROM T0… Daily Weekly © 2018 Snowflake Computing Inc. All Rights Reserved.
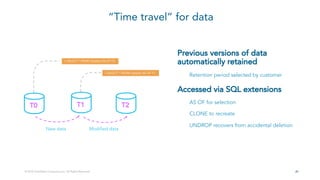
- 21. 2121© 2018 Snowflake Computing Inc. All Rights Reserved. “Time travel” for data Previous versions of data automatically retained Retention period selected by customer Accessed via SQL extensions AS OF for selection CLONE to recreate UNDROP recovers from accidental deletion New data Modified data T0 T1 T2 > SELECT * FROM mytable AS OF T0 > SELECT * FROM mytable AS OF T1
- 22. 2222 Zero-copy data cloning Instant data cloning operations Databases, schema, tables, etc Metadata-only operation Modified data stored as new blocks Unmodified data stored only once No data copying required, no cost! Instant test/dev environments Test code on your entire production dataset Swap tables into production when ready CLONE 1 MODIFIED DATA © 2018 Snowflake Computing Inc. All Rights Reserved.
- 23. 23 Data Science Reporting Ad-hoc analytics ETL and Processing Pay for what you actually use…down to the second Morning Noon Night Workload Morning Noon Night Workload Morning Noon Night Workload Morning Noon Night Workload S 2S Autoscaling Multi-cluster Warehouse L Autosuspend/Autoresume M Autosuspend/Autoresume M 2M Autoscaling Multi-cluster Warehouse
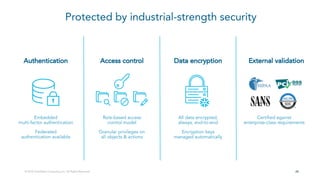
- 24. 2424 Access control Role-based access control model Granular privileges on all objects & actions Authentication Embedded multi-factor authentication Federated authentication available Data encryption All data encrypted, always, end-to-end Encryption keys managed automatically External validation Certified against enterprise-class requirements Protected by industrial-strength security © 2018 Snowflake Computing Inc. All Rights Reserved.
- 25. 25 Big Data V’s: Warehouse & Lake comparison 2 Data warehouse Data lake Volume Expensive for large data, capacity is often capped Low cost and high capacity Variety Structured Schema on write Structured, semi-structured, unstructured Schema on read Velocity Batch ETL/ELT Hourly or daily latency Streaming Near real time Veracity Highly curated, governed. Source of truth Raw, uncleansed data. Source of fact Value Measure things, detect trends Q: What has worked well? Find relationships, make predictions Q: What will work well?
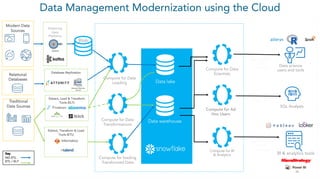
- 26. 26 Data Management Modernization using the Cloud Modern Data Sources Streaming Data Platforms Compute for Data Scientists Compute for Ad Hoc Users Compute for BI & Analytics Data lake Data warehouse Native JDBC / ODBC Connector Web UI SQL Analysts Data science users and tools Native JDBC / ODBC Connector BI & analytics tools Compute for Data Loading Compute for Data Transformations Blob Extract, Load & Transform Tools (ELT) Extract, Transform & Load Tools (ETL) Traditional Data Sources Key NO ETL ETL / ELT Relational Databases Database Replication Compute for loading Transformed Data
- 27. © 2018 Snowflake Computing Inc. All Rights Reserved. Thank you!