











































VMworld 2013: DRS: New Features, Best Practices and Future Directions
- 1. DRS: New Features, Best Practices and Future Directions Aashish Parikh, VMware VSVC5280 #VSVC5280
- 2. 22 Disclaimer This session may contain product features that are currently under development. This session/overview of the new technology represents no commitment from VMware to deliver these features in any generally available product. Features are subject to change, and must not be included in contracts, purchase orders, or sales agreements of any kind. Technical feasibility and market demand will affect final delivery. Pricing and packaging for any new technologies or features discussed or presented have not been determined.
- 3. 33 Talk Outline Advanced Resource Management concepts • VM Happiness and Load-balancing New features in vSphere 5.5 • Going after harder problems, tackling specific pain-points Integrating with new Storage and Networking features • Playing nicely with vFlash, vSAN and autoscaling proxy switch ports Future Directions • What’s cooking in DRS labs!
- 4. 44 Related Material Other DRS talks at VMworld 2013 • VSVC5821 - Performance and Capacity management of DRS clusters (3:30 pm, Monday) • STO5636 - Storage DRS: Deep Dive and Best Practices to Suit Your Storage Environments (4 pm, Monday & 12:30 pm Tuesday) • VSVC5364 - Storage IO Control: Concepts, Configuration and Best Practices to Tame Different Storage Architectures (8:30 am, Wed. & 11 am, Thursday) From VMworld 2012 • VSP2825 - DRS: Advanced Concepts, Best Practices and Future Directions • Video: http://www.youtube.com/watch?v=lwoVGB68B9Y • Slides: http://download3.vmware.com/vmworld/2012/top10/vsp2825.pdf VMware Technical Journal publications • VMware Distributed Resource Management: Design, Implementation, and Lessons Learned • Storage DRS: Automated Management of Storage Devices In a Virtualized Datacenter
- 5. 55 Advanced Resource Management Concepts Contention, happiness, constraint-handling and load-balancing
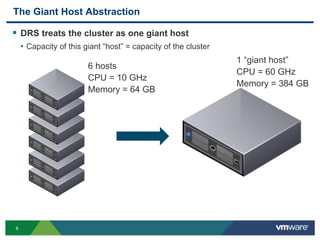
- 6. 66 The Giant Host Abstraction DRS treats the cluster as one giant host • Capacity of this giant “host” = capacity of the cluster 1 “giant host” CPU = 60 GHz Memory = 384 GB 6 hosts CPU = 10 GHz Memory = 64 GB
- 7. 77 Why is That Hard? Main issue: fragmentation of resource across hosts Primary goal: Keep VMs happy by meeting their resource demands! 1 “giant host” CPU = 60 GHz Memory = 384 GB VM demand < 60 GHz All VMs running happily
- 8. 88 Why Meet VM Demand as the Primary Goal? VM demand satisfied VM or application happiness Why is this not met by default? • Host level overload: VM demands may not be met on the current host Three ways to find more capacity in your cluster • Reclaim resources from VMs on current host • Migrate VMs to a powered-on hosts with free capacity • Power on a host (exit DPM standby mode) and then migrate VMs to it Note: demand current utilization
- 9. 99 Why Not Load-balance the DRS Cluster as the Primary Goal? Load-balancing is not free • When VM demand is low, load-balancing may have some cost but no benefit Load-balancing is a mechanism used to meet VM demands Consider these 4 hosts with almost-idle VMs Note: all VMs are getting what they need Q: Should we balance VMs across hosts?
- 10. 1010 Important Metrics and UI Controls CPU and memory entitlement • VM deserved value based on demand, resource settings and capacity Load is not balanced but all VMs are happy!
- 11. 1111 DRS Load-balancing: The Balls and Bins Problem Problem: assign n balls to m bins • Balls could have different sizes • Bins could have different sizes Key Challenges • Dynamic numbers and sizes of balls/bins • Constraints on co-location, placement and others Now, what is a fair distribution of balls among bins? DRS load-balancing • VM resource entitlements are the ‘balls’ • Host resource capacities are the ‘bins’ • Dynamic load, dynamic capacity • Various constraints: DRS-Disabled-On-VM, VM-to-Host affinity, …
- 12. 1212 Goals of DRS Load-balancing Fairly distribute VM demand among hosts in a DRS cluster Enforce constraints • Recommend mandatory moves Recommend moves that significantly improve imbalance Recommend moves with long-term benefit
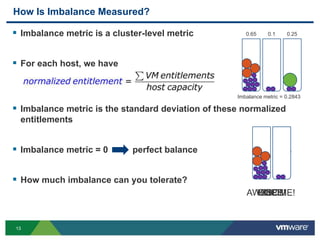
- 13. 1313 How Is Imbalance Measured? Imbalance metric is a cluster-level metric For each host, we have Imbalance metric is the standard deviation of these normalized entitlements Imbalance metric = 0 perfect balance How much imbalance can you tolerate? AWESOME!OOPS!OUCH!YIKES! 0.65 0.1 0.25 Imbalance metric = 0.2843
- 14. 1414 The Myth of Target Balance UI slider tells us what star threshold is acceptable Implicit target number for cluster imbalance metric • n-star threshold tolerance of imbalance up to n * 10% in a 2-node cluster Constraints can make it hard to meet target balance Meeting aggressive target balance may require many migrations • DRS will recommend them only if they also make VMs happier If all VMs are happy, a little imbalance is not really a bad thing!
- 15. 1515 Key Takeaway Points The Goals of DRS • Provide the giant host abstraction • Meet VM demand and keep applications at high performance • Use load balancing as a secondary metric while making VMs happy DRS recommends moves that reduce cluster imbalance Constraints can impact achievable imbalance metric If all VMs are happy, a little imbalance is not really a bad thing!
- 16. 1616 New Features in vSphere 5.5 Going after harder problems, tackling specific pain-points
- 17. 1717 Restrict #VMs per Host Consider a perfectly balanced cluster w.r.t. CPU, Memory Bigger host is ideal for new incoming VMs However, spreading VMs around is important to some of you! • In vSphere 5.1, we introduced a new option LimitVMsPerESXHost = 6 • DRS will not admit or migrate more than 6 VMs to any Host This number must be managed manually – not really the DRS way!
- 18. 1818 AutoTune #VMs per Host *NEW* in vSphere 5.5: LimitVMsPerESXHostPercent Currently: 20 VMs New: 12 VMs Total: 32 VMs VMs per Host limit automatically set to: Mean + (Buffer% * Mean) • Mean (VMs per host, including new VMs): 8 • Buffer% (value of new option): 50 • Therefore, new limit automatically set to: 8 + (50% * 8) = 12 Use for new operations, not to correct current state Host1 Host2 Host3 Host4
- 19. 1919 Latency-sensitive VMs and DRS Several efforts to help latency-sensitive apps • VSVC5596 - Extreme Performance Series: Network Speed Ahead • VSVC5187 - Silent Killer: How Latency Destroys Performance...And What to Do About It DRS recognizes VMs marked as latency-sensitive DRS initial placement “just works” DRS load-balancing treats VMs as if soft-affine to current hosts • Latency-sensitive workloads may be sensitive to vMotions • Soft affinity is internal, no visible new rule in the UI VMs will not be migrated unless absolutely necessary • To fix otherwise unfixable host overutilization • To fix otherwise unfixable soft/hard rule-violation DRS recognizes VMs marked as latency-sensitive
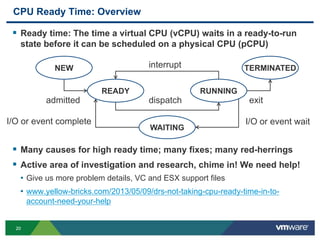
- 20. 2020 CPU Ready Time: Overview Ready time: The time a virtual CPU (vCPU) waits in a ready-to-run state before it can be scheduled on a physical CPU (pCPU) Many causes for high ready time; many fixes; many red-herrings Active area of investigation and research, chime in! We need help! • Give us more problem details, VC and ESX support files • www.yellow-bricks.com/2013/05/09/drs-not-taking-cpu-ready-time-in-to- account-need-your-help NEW TERMINATED WAITING READY RUNNING dispatch interrupt exitadmitted I/O or event waitI/O or event complete
- 21. 2121 CPU Ready Time: Common “Problems” and Solutions “%RDY is 80, that cannot be good” • Cumulative number – divide by #vCPUs to get an accurate measure • Rule-of-thumb: up to 5% per vCPU is usually alright “Host utilization is very low, %RDY is very high” • Host power-management settings reduce effective pCPU capacity! • Set BIOS option to “OS control” and let ESX decide • Low VM or RP CPU limit values restrict cycles delivered to VMs • Increase limits (or set them back to “unlimited”, if possible) “Host and Cluster utilization is very high, %RDY is very high” • Well, physics.. • Add more capacity to the cluster
- 22. 2222 CPU Ready Time: NUMA Scheduling Effects NUMA-scheduler can increase %RDY vCPUs scheduled for data locality in caches and local memory So what’s the solution? • There’s no real solution – there’s no real problem here! Application performance is often better! • Benefit of NUMA-scheduling is usually more than the hit to %RDY For very CPU-heavy apps, disabling NUMA-rebalancer might help • http://blogs.vmware.com/vsphere/2012/02/vspherenuma-loadbalancing.html node0 node1 Localmemory Localmemory 0 7 1 6 2 5 3 4 cores 7 0 6 1 5 2 4 3 cores
- 23. 2323 CPU Ready Time: Better Handling in DRS Severe load imbalance in the cluster - high #vCPU / #pCPU ratio • DRS automatically detects and addresses severe imbalance aggressively • Functionality added in vSphere 4.1 U3, 5.0 U2 and 5.1 CPU demand estimate too low – DRS averaging out the bursts • 5-minute CPU average may capture CPU active too conservatively • *NEW* in vSphere 5.5: AggressiveCPUActive = 1 • DRS Labs!: Better CPU demand estimation techniques Other reasons for performance hit due to high %RDY values • Heterogeneous workloads on vCPUs of a VM, correlated workloads • DRS Labs!: NUMA-aware DRS placement and load-balancing
- 24. 2424 Memory Demand Estimation DRS’ view of VM memory hierarchy Active memory determined by statistical sampling by ESX, often underestimates demand! *NEW* in vSphere 5.5 – burst protection! • PercentIdleMBInMemDemand = 25 (default) DRS / DPM memory demand = Active + (25% * IdleConsumed) • For aggressive demand computation, PercentIdleMBInMemDemand = 100 Active Idle Consumed Consumed Configured
- 25. 2525 Key Takeaway Points Number of VMs per host can now be managed with ease • Use this wisely, VM happiness and load-balance can be adversely affected DRS handles latency-sensitive VMs effectively Better handling of CPU ready time • *NEW* in vSphere 5.5: AggressiveCPUActive • We need your help – precise problem descriptions and dump files Better handling of memory demand – burst protection • *NEW* in vSphere 5.5: PercentIdleMBInMemDemand
- 26. 2626 Integrating with New Storage and Networking Features Playing nicely with vFlash, vSAN, autoscaling proxy switch ports
- 27. 2727 VMware vFlash: Overview VMware vFlash: new host-side caching solution in vSphere 5.5 vFlash reservations statically defined per VMDK Cache is write-through (i.e. used as read cache only) Cache blocks copied to destination host during vMotion by default ESX host SSDvFlash vmdk1 vmdk2 Shared storage
- 28. 2828 VMware vFlash: DRS Support and Best Practices DRS initial placement “just works” • vFlash reservations are enforced during admission control DRS load-balancing treats VMs as if soft-affine to current hosts VMs will not be migrated unless absolutely necessary • To fix otherwise unfixable host overutilization or soft/hard rule-violation Best practices: • Use vFlash reservations judiciously • Mix up VMs that need and do not need vFlash in a single cluster
- 29. 2929 VMware vFlash: Things to Know Migration time is proportional to cache allocation No need to re-warm on destination vMotions may take longer Host-maintenance mode operations may take longer vFlash space can get fragmented across the cluster – no defrag. mechanism Technical deep-dive • STO5588 - vSphere Flash Read Cache Technical Overview
- 30. 3030 VMware vSAN: Interop with DRS vSAN creates a distributed datastore using local SSDs and disks A vSAN cluster can also have hosts without local storage VMDK blocks are duplicated across several hosts for reliability DRS is compatible with vSAN vMotion may cause remote accesses until local caches are warmed
- 31. 3131 Autoscaling Proxy Switch Ports and DRS DRS admission control – proxy switch ports test • Makes sure that a host has enough ports on the proxy switch to map • vNIC ports • uplink ports • vmkernel ports In vSphere 5.1, ports per host = 4096 • Hosts will power-on no more than ~400 VMs *NEW* in vSphere 5.5, autoscaling switch ports • Ports per host discovered at host boot time • Proxy switch ports automatically scaled DRS and HA will admit more VMs! VMware DRS Virtual Switch
- 32. 3232 Key Takeaway Points DRS and vFlash play nice! • Initial placement “just works” • vFlash reservations are enforced during admission control • DRS load-balancing treats VMs as if soft-affine to current hosts DRS and vSAN are compatible with each other Proxy switch ports on ESX hosts now autoscale upon boot • Large hosts can now admit many more VMs
- 33. 3333 Future Directions What’s cooking in DRS labs!
- 34. 3434 Network DRS: Bandwidth Reservation Per-vNIC shares and limits have been available since vSphere 4.1 We are experimenting with per vNIC bandwidth reservations In presence of network reservations • DRS will respect those during placement and future vMotion recommendations • pNIC capacity at host will be pooled together for this What else would you like to see in this area? Is pNIC contention an issue in your environment? Network RPs?
- 35. 3535 Static VM Overhead Memory: Overview Static overhead memory is the amount of additional memory required to power-on or resume a VM Various factors affect the computation • VM config. Parameters • VMware features (FT, CBRC; etc) • Host config. parameters • ESXi Build Number This value is used for admission control! • (Reservation + static overhead) must be admitted for a successful power-on • Used by DRS initial placement, DRS load-balancing, manual migrations
- 36. 3636 Static VM Overhead Memory: Better Estimation Better estimation of static overhead memory leads to more consolidation during power-on! • www.yellow-bricks.com/2013/05/06/dynamic-versus-static-overhead-memory Some very encouraging results so far Here’s an example of a 10 vCPU VM with memsize = 120 GB • The current approach computes static overhead memory: • The new approach computes static overhead memory: <drumroll> 988.06 MB 12.26 GB
- 37. 37 Proactive DRS: Overview Monitor ComputeEvaluate Remediate Verify Inventory Rules and constraints Available capacity Usage statistics Alarms, notifications RP tree integrity Rule and constraint parameters Free capacity Growth rates Derived metrics RP violations Rule and constrain violations Capacity sufficient? VMs happy? Cluster balanced? Migrate to fix violations Increase VM entitlement • On same host (re-divvy) • On another host (migrate) • On another host (power on + migrate) Monitor RemediateCompute Evaluate Predict Motivation • VM demand can be clipped • Remediation can be expensive Goals • Predict and avoid spikes • Make remediation cheaper • Proactive load-balancing • Proactive DPM • Use predicted data for placement, evacuation DRS life-cycleProactive DRS life-cycle
- 38. 3838 Proactive DRS: Predicting Demand with vC Ops VMware Operations Manager – a.k.a. vC Ops • Monitors VCs and their inventories • Collects stats, does analytics and capacity planning Monitors VC performance stats and provides dynamic thresholds • Gray area (literally ) • Range of predicted values Proactive DRS uses upper bound as predicted demand • Various CPU and Memory metrics • Not perfect: capacity planning vs demand estimation • Work in progress, encouraging results so far
- 39. 3939 Proactive DRS: Fling We wrote you a fling! • http://www.labs.vmware.com/flings/proactive-drs • http://flingcontest.vmware.com Fun tool to try out basic Proactive DRS • Connects to vC Ops, downloads dynamic thresholds, creates stats file • Puts per-cluster “predicted.stats” files into your VCs, runs once a day To enable Proactive DRS, simply set ProactiveDRS = 1 More details, assumptions, caveats on the fling page
- 41. 4141 In Summary VM Happiness is the key goal of DRS Load balancing keeps VMs happy and resource utilization fair New features in vSphere 5.5 • Automatic management of #VMs per ESX host, Latency-sensitive VM support • Better ready-time handling, Better memory demand estimation Interoperability with vFlash, vSAN, autoscaling proxy switch ports Tons of cool DRS stuff in the pipeline, feedback welcome! • Beginnings of network DRS, Better estimation of VM static overhead memory • Proactive DRS!
- 42. THANK YOU
- 44. DRS: New Features, Best Practices and Future Directions Aashish Parikh, VMware VSVC5280 #VSVC5280
- 46. 4646 DRS — Overview DRS Cluster vMotion Ease of Management Initial Placement Runtime CPU/Memory Load-balancing VM-to-VM and VM-to-host Affinity and Anti-Affinity Host Maintenance Mode Add Host ••• Always respect resource controls!
- 47. 4747 How Are Demands Computed? Demand indicates what a VM could consume given more resources Demand can be higher than utilization • Think ready time CPU demand is a function of many CPU stats Memory demand is computed by tracking pages in guest address space and the percentage touched in a given interval
- 48. 4848 Evaluating Candidates Moves to Generate Recommendations Consider migrations from over-loaded to under-loaded hosts • Δ = Imbalance Metricbefore move – Imbalance Metricafter move • ‘Δ’ is also called goodness Constraints and resource specifications are respected • VMs from Host2 are anti-affine with Host1 Prerequisite/dependent migrations also considered List of good moves is filtered further Only the best of these moves are recommended Host1 Host2 Host3
- 49. 4949 CPU Ready Time: Final Remarks “Host utilization is very high, %RDY is very high” • Well, physics.. Other reasons for performance hit due to high %RDY values • Heterogenous workloads on vCPUs of a VM, correlated workloads Playing with more ideas in DRS Labs! • Better CPU demand estimation • NUMA-aware DRS placement and load-balancing Active area of investigation and research, chime in! We need help! • Give us more problem details, VC and ESX support files • www.yellow-bricks.com/2013/05/09/drs-not-taking-cpu-ready-time-in-to- account-need-your-help