Web & text mining lecture10
•Download as PPT, PDF•
1 like•1,613 views

This document discusses text mining and lexicon construction. It introduces text mining and describes how lexicons are important for tasks like question answering and information extraction. It then discusses different approaches for constructing lexicons, including iterative expansion of phrase lists, multilevel bootstrapping, and co-training algorithms using internal word features.

























































Web & text mining lecture10
- 1. CS276B Web Search and Mining Lecture 10 Text Mining I Feb 8, 2005 (includes slides borrowed from Marti Hearst) 1
- 2. Text Mining Today Introduction Lexicon construction Topic Detection and Tracking Future Two more text mining lectures Question Answering Summarization … and more 2
- 3. The business opportunity in text mining… 100 90 80 70 60 Unst ruct ured St ruct ured 50 40 30 20 10 0 Dat a volum e Market Cap 3
- 4. Corporate Knowledge “Ore” Stuff not very accessible via standard data-mining Email Insurance claims News articles Web pages Patent portfolios IRC Scientific articles Customer complaint letters Contracts Transcripts of phone calls with customers Technical documents 4
- 5. Text Knowledge Extraction Tasks Small Stuff. Useful nuggets of information that a user wants: Question Answering Information Extraction (DB filling) Thesaurus Generation Big Stuff. Overviews: Summary Extraction (documents or collections) Categorization (documents) Clustering (collections) Text Data Mining: Interesting unknown correlations that one can discover 5
- 6. Text Mining The foundation of most commercial “text mining” products is all the stuff we have already covered: Information Retrieval engine Web spider/search Text classification Text clustering Named entity recognition Information extraction (only sometimes) Is this text mining? What else is needed? 6
- 7. One tool: Question Answering Goal: Use Encyclopedia/other source to answer “Trivial Pursuit-style” factoid questions Example: “What famed English site is found on Salisbury Plain?” Method: Heuristics about question type: who, when, where Match up noun phrases within and across documents (much use of named entities Coreference is a classic IE problem too! More focused response to user need than standard vector space IR 7 Murax, Kupiec, SIGIR 1993; huge amount of recent work
- 8. Another tool: Summarizing High-level summary or survey of all main points? How to summarize a collection? Example: sentence extraction from a single document (Kupiec et al. 1995; much subsequent work) Start with training set, allows evaluation Create heuristics to identify important sentences: position, IR score, particular discourse cues Classification function estimates the probability a given sentence is included in the abstract 42% average precision 8
- 9. IBM Text Miner terminology: Example of Vocabulary found Certificate of deposit CMOs Commercial bank Commercial paper Commercial Union Assurance Commodity Futures Trading Commission Consul Restaurant Convertible bond Credit facility Credit line Debt security Debtor country Detroit Edison Digital Equipment Dollars of debt End-March Enserch Equity warrant Eurodollar … 9
- 10. What is Text Data Mining? Peoples’ first thought: Make it easier to find things on the Web. But this is information retrieval! The metaphor of extracting ore from rock: Does make sense for extracting documents of interest from a huge pile. But does not reflect notions of DM in practice. Rather: finding patterns across large collections discovering heretofore unknown information 10
- 11. Real Text DM What would finding a pattern across a large text collection really look like? Discovering heretofore unknown information is not what we usually do with text. (If it weren’t known, it could not have been written by someone!) However, there is a field whose goal is to learn about patterns in text for its own sake … Research that exploits patterns in text does so mainly in the service of computational linguistics, rather than for learning about and exploring text collections. 11
- 12. Definitions of Text Mining Text mining mainly is about somehow extracting the information and knowledge from text; 2 definitions: Any operation related to gathering and analyzing text from external sources for business intelligence purposes; Discovery of knowledge previously unknown to the user in text; Text mining is the process of compiling, organizing, and analyzing large document collections to support the delivery of targeted types of information to analysts and decision makers and to discover relationships between related facts that span wide domains of inquiry. 12
- 13. True Text Data Mining: Don Swanson’s Medical Work Given medical titles and abstracts a problem (incurable rare disease) some medical expertise find causal links among titles symptoms drugs results E.g.: Magnesium deficiency related to migraine This was found by extracting features from medical literature on migraines and nutrition 13
- 14. Swanson Example (1991) Problem: Migraine headaches (M) Stress is associated with migraines; Stress can lead to a loss of magnesium; calcium channel blockers prevent some migraines Magnesium is a natural calcium channel blocker; Spreading cortical depression (SCD) is implicated in some migraines; High levels of magnesium inhibit SCD; Migraine patients have high platelet aggregability; Magnesium can suppress platelet aggregability. All extracted from medical journal titles 14
- 15. Swanson’s TDM Two of his hypotheses have received some experimental verification. His technique Only partially automated Required medical expertise Few people are working on this kind of information aggregation problem. 15
- 16. Gathering Evidence All Migraine Research migraine CCB PA All Nutrition Research magnesium SCD stress 16
- 17. Or maybe it was already known? 17
- 19. What is a Lexicon? A database of the vocabulary of a particular domain (or a language) More than a list of words/phrases Usually some linguistic information Morphology (manag- e/es/ing/ed → manage) Syntactic patterns (transitivity etc) Often some semantic information Is-a hierarchy Synonymy Numbers convert to normal form: Four → 4 Date convert to normal form Alternative names convert to explicit form Mr. Carr, Tyler, Presenter → Tyler Carr 19
- 20. Lexica in Text Mining Many text mining tasks require named entity recognition. Named entity recognition requires a lexicon in most cases. Example 1: Question answering Example 2: Information extraction Where is Mount Everest? A list of geographic locations increases accuracy Consider scraping book data from amazon.com Template contains field “publisher” A list of publishers increases accuracy Manual construction is expensive: 1000s of person hours! Sometimes an unstructured inventory is sufficient Often you need more structure, e.g., hierarchy 20
- 21. Lexicon Construction (Riloff) Attempt 1: Iterative expansion of phrase list Start with: Large text corpus List of seed words Identify “good” seed word contexts Collect close nouns in contexts Compute confidence scores for nouns Iteratively add high-confidence nouns to seed word list. Go to 2. Output: Ranked list of candidates21
- 22. Lexicon Construction: Example Category: weapon Seed words: bomb, dynamite, explosives Context: <new-phrase> and <seed-phrase> Iterate: Context: They use TNT and other explosives. Add word: TNT Other words added by algorithm: rockets, bombs, missile, arms, bullets 22
- 23. Lexicon Construction: Attempt 2 Multilevel bootstrapping (Riloff and Jones 1999) Generate two data structures in parallel The lexicon A list of extraction patterns Input as before Corpus (not annotated) List of seed words 23
- 24. Multilevel Bootstrapping Initial lexicon: seed words Level 1: Mutual bootstrapping Level 2: Filter lexicon Extraction patterns are learned from lexicon entries. New lexicon entries are learned from extraction patterns Iterate Retain only most reliable lexicon entries Go back to level 1 2-level performs better than just level 1. 24
- 25. Scoring of Patterns Example Concept: company Pattern: owned by <x> Patterns are scored as follows score(pattern) = F/N log(F) F = number of unique lexicon entries produced by the pattern N = total number of unique phrases produced by the pattern Selects for patterns that are Selective (F/N part) Have a high yield (log(F) part) 25
- 26. Scoring of Noun Phrases Noun phrases are scored as follows score(NP) = sum_k (1 + 0.01 * score(pattern_k)) where we sum over all patterns that fire for NP Main criterion is number of independent patterns that fire for this NP. Give higher score for NPs found by highconfidence patterns. Example: New candidate phrase: boeing Occurs in: owned by <x>, sold to <x>, offices of <x> 26
- 27. Shallow Parsing Shallow parsing needed For identifying noun phrases and their heads For generating extraction patterns For scoring, when are two noun phrases the same? Head phrase matching X matches Y if X is the rightmost substring of Y “New Zealand” matches “Eastern New Zealand” “New Zealand cheese” does not match “New 27 Zealand”
- 28. Seed Words 28
- 31. Level 1: Mutual Bootstrapping Drift can occur. It only takes one bad apple to spoil the barrel. Example: head Introduce level 2 bootstrapping to prevent drift. 31
- 33. Evaluation 33
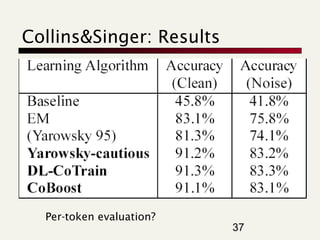
- 34. Collins&Singer: CoTraining Similar back and forth between New: They use word-internal features an extraction algorithm and a lexicon Is the word all caps? (IBM) Is the word all caps with at least one period? (N.Y.) Non-alphabetic character? (AT&T) The constituent words of the phrase (“Bill” is a feature of the phrase “Bill Clinton”) Classification formalism: Decision Lists 34
- 35. Collins&Singer: Seed Words Note that categories are more generic than in the case of Riloff/Jones. 35
- 36. Collins&Singer: Algorithm Train decision rules on current lexicon (initially: seed words). Apply decision rules to training set Result: new set of decision rules. Result: new lexicon Repeat 36
- 38. Lexica: Limitations Named entity recognition is more than lookup in a list. Linguistic variation Non-linguistic variation Manage, manages, managed, managing Human gene MYH6 in lexicon, MYH7 in text Ambiguity What if a phrase has two different semantic classes? Bioinformatics example: gene/protein metonymy 38
- 39. Lexica: Limitations - Ambiguity Metonymy is a widespread source of ambiguity. Metonymy: A figure of speech in which one word or phrase is substituted for another with which it is closely associated. (king – crown) Gene/protein metonymy The gene name is often used for its protein product. TIMP1 inhibits the HIV protease. TIMP1 could be a gene or protein. Important difference if you are searching for TIMP1 protein/protein interactions. Some form of disambiguation necessary to identify correct sense. 39
- 40. Discussion Partial resources often available. E.g., you have a gazetteer, you want to extend it to a new geographic area. Some manual post-editing necessary for high-quality. Semi-automated approaches offer good coverage with much reduced human effort. Drift not a problem in practice if there is a human in the loop anyway. Approach that can deal with diverse evidence preferable. Hand-crafted features (period for “N.Y.”) help a lot. 40
- 41. Terminology Acquisition Goal: find heretofore unknown noun phrases in a text corpus (similar to lexicon construction) Lexicon construction Emphasis on finding noun phrases in a specific semantic class (companies) Application: Information extraction Terminology Acquisition Emphasis on term normalization (e.g., viral and bacterial infections -> viral_infection) Applications: translation dictionaries, 41 information retrieval
- 42. References Julian Kupiec, Jan Pedersen, and Francine Chen. A trainable document summarizer. http://citeseer.nj.nec.com/kupiec95trainable.html Julian Kupiec. Murax: A robust linguistic approach for question answering using an on-line encyclopedia. In the Proceedings of 16th SIGIR Conference, Pittsburgh, PA, 2001. Don R. Swanson: Analysis of Unintended Connections Between Disjoint Science Literatures. SIGIR 1991: 280-289 Tim Berners Lee on semantic web: http://www.sciam.com/ 2001/0501issue/0501berners-lee.html http://www.xml.com/pub/a/2001/01/24/rdf.html Learning Dictionaries for Information Extraction by Multi-Level Bootstrapping (1999) Ellen Riloff, Rosie Jones. Proceedings of the Sixteenth National Conference on Artificial Intelligence Unsupervised Models for Named Entity Classification (1999) Michael Collins, Yoram Singer 42
- 44. First Story Detection Automatically identify the first story on a new event from a stream of text Topic Detection and Tracking – TDT Applications “Bake-off” sponsored by US government agencies Finance: Be the first to trade a stock Breaking news for policy makers Intelligence services Other technologies don’t work for this Information retrieval Text classification Why? 44
- 45. Definitions Event: A reported occurrence at a specific time and place, and the unavoidable consequences. Specific elections, accidents, crimes, natural disasters. Activity: A connected set of actions that have a common focus or purpose campaigns, investigations, disaster relief efforts. Topic: a seminal event or activity, along with all directly related events and activities Story: a topically cohesive segment of news that includes two or more DECLARATIVE 45 independent clauses about a single event.
- 46. Examples 2002 Presidential Elections Thai Airbus Crash (11.12.98) On topic: stories reporting details of the crash, injuries and deaths; reports on the investigation following the crash; policy changes due to the crash (new runway lights were installed at airports). Euro Introduced (1.1.1999) On topic: stories about the preparation for the common currency (negotiations about exchange rates and financial standards to be shared among the member nations); official introduction of the Euro; economic details of the shared currency; reactions within the EU and around the world. 46
- 47. TDT Tasks First story detection (FSD) Topic tracking Detect the first story on a new topic Once a topic has been detected, identify subsequent stories about it Standard text classification task However, very small training set (initially: 1!) Linking Given two stories, are they about the same topic? One way to solve FSD 47
- 48. The First-Story Detection Task To detect the first story that discusses a topic, for all topics. First Stories Time = Topic 1 = Topic 2 Not First Stories There is no supervised topic training (like Topic Detection) 48
- 49. First Story Detection New event detection is an unsupervised learning task Detection may consist of discovering previously unidentified events in an accumulated collection – retro Flagging onset of new events from live news feeds in an on-line fashion Lack of advance knowledge of new events, but have access to unlabeled historical data as a contrast set The input to on-line detection is the stream of TDT stories in chronological order simulating real-time incoming documents The output of on-line detection is a YES/NO decision per document 49
- 50. Patterns in Event Distributions News stories discussing the same event tend to be temporally proximate A time gap between burst of topically similar stories is often an indication of different events Different earthquakes Airplane accidents A significant vocabulary shift and rapid changes in term frequency are typical of stories reporting a new event, including previously unseen proper nouns Events are typically reported in a relatively brief time window of 1- 4 weeks 50
- 51. TDT: The Corpus TDT evaluation corpora consist of text and transcribed news from 1990s. A set of target events (e.g., 119 in TDT2) is used for evaluation Corpus is tagged for these events (including first story) TDT2 consists of 60,000 news stories, Jan-June 1998, about 3,000 are “on topic” for one of 119 topics Stories are arranged in chronological order 51
- 52. Tasks in News Detection News Feeds Segmentation Detection Retro On-Line Tracking 52
- 53. Approach 1: KNN On-line processing of each incoming story Compute similarity to all previous stories Cosine similarity Language model Prominent terms Extracted entities If similarity is below threshold: new story If similarity is above threshold for previous story s: assign to topic of s Threshold can be trained on training set Threshold is not topic specific! 53
- 54. Approach 2: Single Pass Clustering Assign each incoming document to one of a set of topic clusters A topic cluster is represented by its centroid (vector average of members) For incoming story compute similarity with centroid 54
- 55. Similar Events over Time 55
- 56. Approach 3: KNN + Time Only consider documents in a (short) time window Compute similarity in a time weighted fashion: m: number of documents in window, d_i: ith document in window Time weighting significantly increases performance. 56
- 57. FSD - Results UMass , CMU: Single-Pass Clustering Dragon: Language Model 57
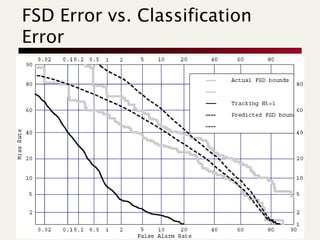
- 58. FSD Error vs. Classification Error 58
- 59. Discussion Hard problem Becomes harder the more topics need to be tracked. Why? Second Story Detection much easier that First Story Detection Example: retrospective detection of first 9/11 story easy, on-line detection hard 59
Editor's Notes
- Examples are: Letters from customers, email correspondence, recordings of phone calls with customers, contracts, technical documentation, patents, etc. With ever dropping prices of mass storage, companies collect more and more of such data. But what can we get from this data? That’s where text mining comes in. The goal of text mining is to extract knowledge from this ninety percent unstructured masses of text.
- This is some of the vocabulary found by feature extraction in a collection of financial news stories. The process of feature extraction is fully automatic – the vocabulary is not predefined. Nevertheless, as you can see, the names and multi-word terms that are found are of high quality, and in fact correspond closely to the characteristic vocabulary used in the domain of the documents being analyzed. In fact, what is found in feature extraction is to a large degree the vocabulary in which concepts occurring in the document collections are expressed. [the canonical forms are shown]