






























Five things virtualization has changed in your dr plan
- 1. Five Things Virtualization Has Changed In Your Disaster Recovery Plan Josh Mazgelis – Senior Product Marketing Manager Friday, December 06, 2013
- 2. Quick Introductions About Neverfail About Josh Mazgelis Business Continuity Lifecycle Management (BCLM) Disaster recovery software Product Marketing Manager • (The guy who knows technology) 18+ years in the tech industry • Application high availability • 12+ years in the market • TS, SA, PM, SE, PMK… • 8 years in disaster recovery VMware & Microsoft partner Experience working customers • Significant investments Strategic OEM relationships • VMware vCenter Heartbeat • SolarWinds Orion Failover Engine • Cisco, Honeywell, others… • IT disaster recovery • Personal experience in recovering from failures Online in many places • Twitter, LinkedIn, Spiceworks…
- 3. Today’s Agenda Improvements in backup processes Improvements in server recovery Increased simplicity in disaster recovery deployment Improvements in complete site recovery options Increased complexity in SLA management
- 4. Recovery Definitions Recovery Point Objective (RPO): The maximum desired time period prior to a failure or disaster during which changes to data may be lost as a consequence of recovery. Recovery time objective (RTO) The recovery time objective (RTO) is the maximum tolerable length of time that a computer, system, network, or application can be down after a failure or disaster occurs.
- 6. How is Backup Better with Virtualization Traditional computers become VM containers • Just files on a disk, not complete disk volumes • Fully abstracted from the physical hardware layer Basic protection is easier obtain • Many vendors provide methods of moving protecting VM’s • Replication and deduplication are commonplace • Block-level backup & restore speed processes
- 7. Traditional Server Backup Treat each machine like a physical server Backup agent in each machine • Supports physical and virtual machines • Enables granularity in the backup objects • Inefficient and “expensive” with resources
- 8. Modern Virtual Server Backup Treat VM’s as containers on disk • VMware Consolidated Backup as an example Quick and simple copies of all virtual machines • Limited granularity in backup & recovery • Does not address physical servers
- 9. Improvements in Recovery from Failures
- 10. How is Recovery Better with Virtualization? Hypervisor clusters improve hardware availability Bare-metal recovery presents fewer challenges Increasing abstraction of resources Resiliency in virtual hardware
- 11. How We Used To Do Application Recovery Application data backed up to tape library daily • Tapes trucked to and from off-site storage daily Supporting OS & application installed on “spare” (i.e. “previously replaced”) hardware Application data restored (hopefully) to DR server • RTO measured in hours to days!
- 12. How We Recover with Virtualization Backup a VM image to some disk storage Restore that image to a previous version -or- Restore that image to another hypervisor
- 13. One Pitfall of Virtual Recovery A copy of a sick VM is still a sick VM Restore that image to a previous version (hit on RPO) -or- Repair that image and accept downtime (hit on RTO)
- 14. Increased Simplicity in Disaster Recovery Deployment
- 15. How are DR Deployments Better with Virtualization?
- 16. How are DR Deployments Better with Virtualization? Redundant compute power is more affordable • Virtual datacenters being defined in software • Private cloud & public cloud deployments Retired hardware supports similar hypervisors • Old physical servers can be reused more easily • VM images restart on any hardware with no changes
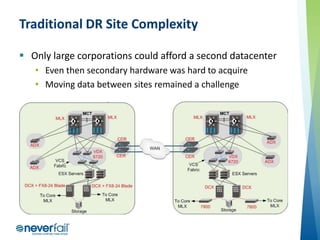
- 17. Traditional DR Site Complexity Only large corporations could afford a second datacenter • Even then secondary hardware was hard to acquire • Moving data between sites remained a challenge
- 18. Recovery as a Service (RaaS) for Everyone RaaS enables DR “sites” for most SMB’s • Pay-as-you-go pricing models • Operating expense vs. capital expenses
- 19. Improvements in Complete Site Recovery
- 20. How is Full Site Recovery is Better with Virtualization Restoring backups to a new location is more simple • Dissimilar hardware is no longer a hurdle • “Recovering” from site failures is more of “restarting” Replication of VM images between sites • Storage hardware or hypervisor level replication • Many built-in and add-on replication options These are the site recovery “enablers” • Better backup & restore over wide-area networks • Stand-by capacity to bring required machines online
- 21. How is Full Site Recovery is Better with Virtualization Automation of site recovery process • Recovery could be done by hand, but would take many hours • Automation simplifies the task to “one button” to push • Most critical machines can be prioritized in recovery plans Many plans can be customized to meet specific needs • Incorporation of 3rd-party tools in recovery plans • Neverfail’s Heartbeat Failover Engine is one example • Increased RPO/RTO for physical & virtual machines
- 22. Site Recovery with VMware SRM Does periodic replication meet RPO requirements? What about physical servers?
- 23. Expanding New Models with Traditional Methods Incorporate physical servers with 3rd-party options • Neverfail extends VMware SRM to include physical servers
- 24. Increased Complexity in SLA Management
- 25. How are SLA’s More Complex with Virtualization? Dynamic virtual environments change quickly • • • • New machines quickly deployed into environment New applications may quickly become “critical” VM’s move easily to different hosts & disks Does DR planning keep up with changes? Better protection is costs more resources • Compute power for stand-by servers • Bandwidth for data/server replication • Storage for VM copies & versioning
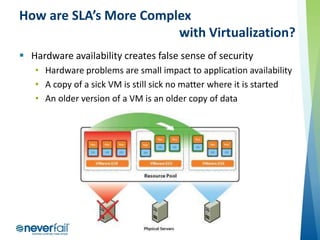
- 26. How are SLA’s More Complex with Virtualization? Hardware availability creates false sense of security • Hardware problems are small impact to application availability • A copy of a sick VM is still sick no matter where it is started • An older version of a VM is an older copy of data
- 27. How are SLA’s More Complex with Virtualization? Growing rift between physical and virtual machines • New “backup 2.0” solutions getting attention • Physical servers getting “backup 1.0” protection • Critical servers may not have adequate visibility & protection Increased SLA expectations • Business is relying on IT more than ever • Perception of recovery capabilities becoming faster • Hardware & environmental issues are in fact reduced • Application downtime still a persistent problem
- 28. How Do We Manage the Complexities of Disaster Recovery in a Virtual World? Business continuity lifecycle management • BC/DR needs to be a continual process, not a one-time project • Recovery plans need to evolve with the environment • Continual monitoring and updating of DR plans
- 29. You’ve Heard Enough From Me Today… …are your questions ready to be answered?
- 30. Questions and Answers Please use the GoToWebinar console to submit your questions for us We will answer as many questions we can, and follow up on those that we can’t! Visit us at www.neverfailgroup.com to learn more • Also find us online at: • Spiceworks, LinkedIn, Twitter, Facebook, Google+ • Or call us direct: • (512) 327-5777 • (0) 870 777-1500
- 31. Thank You & Closing Statements Thank you from me & from Neverfail for your time today Thank you from your company for being on top of BCLM Thank you from Spiceworks on your community involvement Last minutes announcements from Abby @ Spiceworks…
- 32. Thank you for your time We look forward to helping you with BCLM
- 33. Session Abstract 5 things virtualization has changed in your BC plan Are you still rolling with the changes? Virtualization has made a huge impact on the way we deploy our computer workloads, and with that it has also changed the ways in which we protect them. The business continuity plans in place for IT even just five years ago look very different than what many companies have in place today. Keeping on top of these changes will help you understand your recovery capabilities, and your limitations as well. Join us with our friends at Neverfail and make sure you're keeping your IT business continuity plans spicy and fresh!
Editor's Notes
- If I have things like VMware HA/FT, SRM, or other hypervisor replication tools, is that adequate protection for my application?You mention "business continuity life-cycle management". How is that different from BC planning?Are there any hardware or technical requirements in extending SRM to physical servers with the Heartbeat engine?