What does rename() do?
•Download as PPTX, PDF•
5 likes•769 views

Berlin Buzzwords 2017 talk: A look at what our storage models, metaphors and APIs are, showing how we need to rethink the Posix APIs to work with object stores, while looking at different alternatives for local NVM. This is the unabridged talk; the BBuzz talk was 20 minutes including demo and questions, so had ~half as many slides



























What does rename() do?
- 1. 1 © Hortonworks Inc. 2011 – 2017 All Rights Reserved What does rename() do? Steve Loughran stevel@hortonworks.com @steveloughran June 2017
- 2. 2 © Hortonworks Inc. 2011 – 2017 All Rights Reserved How do we safely persist & recover state?
- 3. 3 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Why? ⬢ Save state for when application is restarted ⬢ Publish data for other applications ⬢ Process data published by other applications ⬢ Work with more data than fits into RAM ⬢ Share data with other instances of same application ⬢ Save things people care about & want to get back
- 4. 4 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Define "Storage"?
- 5. FAT8 dBASE II & Lotus 1-2-3 int 21h
- 6. Linux: ext3, reiserfs, ext4 sqlite, mysql, leveldb open(path, O_CREAT|O_EXCL) rename(src, dest) Windows NT, XP NTFS Access, Excel CreateFile(path, CREATE_NEW,...) MoveFileEx(src, dest, MOVEFILE_WRITE_THROUGH)
- 7. Facebook Prineville Datacentre 1+ Exabyte on HDFS + cold store Hive, Spark, ... FileSystem.rename()
- 8. 8 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Model and APIs
- 9. 9 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Structured data: algebra
- 10. 10 © Hortonworks Inc. 2011 – 2017 All Rights Reserved
- 11. 11 © Hortonworks Inc. 2011 – 2017 All Rights Reserved
- 12. 12 © Hortonworks Inc. 2011 – 2017 All Rights Reserved
- 13. 13 © Hortonworks Inc. 2011 – 2017 All Rights Reserved File-System Directories and files Posix with stream metaphor
- 14. 14 © Hortonworks Inc. 2011 – 2017 All Rights Reserved org.apache.hadoop.fs.FileSystem hdfs s3awasb adlswift gcs Hadoop offers Posix API to remote cluster filesystems & storage
- 15. val work = new Path("s3a://stevel-frankfurt/work") val fs = work.getFileSystem(new Configuration()) val task00 = new Path(work, "task00") fs.mkdirs(task00) val out = fs.create(new Path(task00, "part-00"), false) out.writeChars("hello") out.close(); fs.listStatus(task00).foreach(stat => fs.rename(stat.getPath, work) ) val statuses = fs.listStatus(work).filter(_.isFile) require("part-00" == statuses(0).getPath.getName)
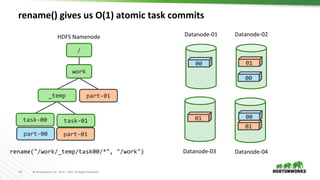
- 16. 16 © Hortonworks Inc. 2011 – 2017 All Rights Reserved rename() gives us O(1) atomic task commits / work _temp part-00 part-01 00 00 00 01 01 01 part-01 rename("/work/_temp/task00/*", "/work") task-00 task-01 HDFS Namenode Datanode-01 Datanode-03 Datanode-02 Datanode-04
- 17. 17 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Amazon S3 doesn't have a rename() / work _temp part-00 part-01 00 00 00 01 01 part-01 LIST /work/_temp/task-01/* task-00 task-01 01 01 01 COPY /work/_temp/task-01/part-01 /work/part-01 DELETE /work/_temp/task-01/part-01 01 S3 Shards
- 18. 18 © Hortonworks Inc. 2011 – 2017 All Rights Reserved part-01 01 01 01 Fix: fundamentally rethink how we commit / work 00 00 00 POST /work/part-01?uploads => UploadID POST /work/part01?uploadId=UploadID&partNumber=01 POST /work/part01?uploadId=UploadID&partNumber=02 POST /work/part01?uploadId=UploadID&partNumber=03 S3 Shards
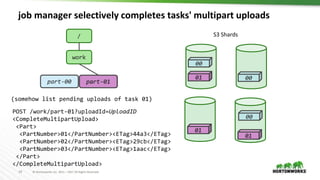
- 19. 19 © Hortonworks Inc. 2011 – 2017 All Rights Reserved job manager selectively completes tasks' multipart uploads / work part-00 00 00 00 part-01 (somehow list pending uploads of task 01) 01 01 01 POST /work/part-01?uploadId=UploadID <CompleteMultipartUpload> <Part> <PartNumber>01</PartNumber><ETag>44a3</ETag> <PartNumber>02</PartNumber><ETag>29cb</ETag> <PartNumber>03</PartNumber><ETag>1aac</ETag> </Part> </CompleteMultipartUpload> part-01 01 01 01 S3 Shards
- 20. 20 © Hortonworks Inc. 2011 – 2017 All Rights Reserved S3A O(1) zero-rename commit demo!
- 21. 21 © Hortonworks Inc. 2011 – 2017 All Rights Reserved What else to rethink? ⬢ Hierarchical directories to tree-walk ==> list & work with all files under a prefix; ⬢ seek() read() sequences ==> HTTP-2 friendly scatter/gather IO read((buffer1, 10 KB, 200 KB), (buffer2, 16 MB, 4 MB)) ⬢ How to work with Eventually Consistent data? ⬢ or: is everything just a K-V store with some search mechanisms?
- 22. 22 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Model #3: Storage as Memory
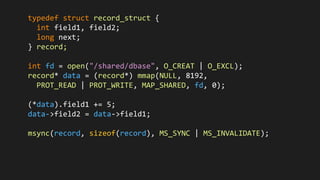
- 23. typedef struct record_struct { int field1, field2; long next; } record; int fd = open("/shared/dbase", O_CREAT | O_EXCL); record* data = (record*) mmap(NULL, 8192, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); (*data).field1 += 5; data->field2 = data->field1; msync(record, sizeof(record), MS_SYNC | MS_INVALIDATE);
- 24. SSD via SATA SSD via NVMe/M.2 Future NVM technologies
- 25. 25 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Non Volatile Memory ⬢ SSD-backed RAM ⬢ near-RAM-speed SSD ⬢ Future memory stores ⬢ RDMA access to NVM on other servers What would a datacentre of NVM & RDMA access do?
- 26. typedef struct record_struct { int field1, field2; record_struct* next; } record; int fd = open("/shared/dbase"); record* data = (record*) pmem_map(fd); // lock ? (*data).field1 += 5; data->field2 = data->field1; // commit ?
- 27. 27 © Hortonworks Inc. 2011 – 2017 All Rights Reserved NVM moves the commit problem into memory I/O ⬢ How to split internal state into persistent and transient? ⬢ When is data saved to NVM ($L1-$L3 cache flushed, sync in memory buffers, ...) ⬢ How to co-ordinate shared R/W access over RDMA? ⬢ How do we write apps for a world where rebooting doesn't reset our state? Catch up: read "The Morning Paper" summaries of research
- 28. 28 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Storage is moving up in scale and/or closer to RAM ⬢ Storage is moving up in scale and/or closer to RAM ⬢ Blobstore APIs address some scale issues, but don't match app expectations for file/dir behaviour; inefficient read/write model ⬢ Non volatile memory is the other radical change ⬢ Posix metaphor/API isn't suited to either —what next? ⬢ SQL makes all this someone else's problem (leaving only O/R mapping, transaction isolation...)
- 29. 29 © Hortonworks Inc. 2011 – 2017 All Rights Reserved29 © Hortonworks Inc. 2011 – 2017. All Rights Reserved Questions?
- 30. 30 © Hortonworks Inc. 2011 – 2017 All Rights Reserved Backup Slides
Editor's Notes
- Trivia: dir rename only came with DOS 3.0
- Facebook prineville photo store is probably at the far end of the spectrum
- Zermelo–Fraenkel set theory (with axiom of choice) and a relational algebra. Or, as it is known: SQL
- Relational Set theory
- Everything usies the Hadoop APIs to talk to both HDFS, Hadoop Compatible Filesystems and object stores; the Hadoop FS API. There's actually two: the one with a clean split between client side and "driver side", and the older one which is a direct connect. Most use the latter and actually, in terms of opportunities for object store integration tweaking, this is actually the one where can innovate with the most easily. That is: there's nothing in the way. Under the FS API go filesystems and object stores. HDFS is "real" filesystem; WASB/Azure close enough. What is "real?". Best test: can support HBase.
- This is how we commit work in Hadoop FileOutputFormat, and so, transitively, how Spark does it too (Hive does some other things, which I'm ignoring, but are more manifest file driven)
- This is my rough guess at a C-level operation against mmaped data today. Ignoringthe open/sync stuff, then the writes in the middle are the operations we need to worry about, as they update the datastructures in-situ. Nonatomically.
- This is my rough guess at a C-level operation against mmaped data today. Ignoringthe open/sync stuff, then the writes in the middle are the operations we need to worry about, as they update the datastructures in-situ. Nonatomically.
- Work like RAMCloud has led the way here, go look at the papers. But that was at RAM, not NVM, where we have the persistence problem Some form of LSF model tends to be used, which ties in well with raw SSD (don't know about other techs, do know that non-raw SSD doesn't really suit LFS) If you look at code, we generally mix persisted (and read back) data with transient; load/save isn't so much seriaiizing out data structures as marshalling the persistent parts to a form we think they will be robust over time, unmarshalling them later (exceptions: Java Serialization, which is notoriously brittle and insecure) What apps work best here? Could you extend Spark to make RDDs persistent & shared, so you can persist them simply by copying to part of cluster memory?, e.g a "NVMOutputFormat"