





























Zaharia spark-scala-days-2012
- 1. Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark-project.org UC BERKELEY
- 2. My Background Grad student in the AMP Lab at UC Berkeley » 50-person lab focusing on big data Committer on Apache Hadoop Started Spark in 2009 to provide a richer, Hadoop-compatible computing engine
- 3. Spark Goals Extend the MapReduce model to support more types of applications efficiently » Spark can run 40x faster than Hadoop for iterative and interactive applications Make jobs easier to program »Language-integrated API in Scala »Interactive use from Scala interpreter
- 4. Why go Beyond MapReduce? MapReduce simplified big data analysis by giving a reliable programming model for large clusters But as soon as it got popular, users wanted more: » More complex, multi-stage applications » More interactive ad-hoc queries
- 5. Why go Beyond MapReduce? Complex jobs and interactive queries both need one thing that MapReduce lacks: Efficient primitives for data sharing Query 1 Stage 3 Stage 2 Stage 1 Query 2 Query 3 Iterative algorithm Interactive data mining
- 6. Why go Beyond MapReduce? Complex jobs and interactive queries both need one thing that MapReduce lacks: Efficient primitives for data sharing Query 1 Stage 3 Stage 2 Stage 1 In MapReduce, the only way to shareQuery 2 across data jobs is stable storage (e.g. HDFS) Query 3 -> slow! Iterative algorithm Interactive data mining
- 7. Examples HDFS HDFS HDFS HDFS read write read write iter. 1 iter. 2 . . . Input HDFS query 1 result 1 read query 2 result 2 query 3 result 3 Input . . . I/O and serialization can take 90% of the time
- 8. Goal: In-Memory Data Sharing iter. 1 iter. 2 . . . Input query 1 one-time processing query 2 query 3 Input Distributed memory . . . 10-100× faster than network and disk
- 9. Solution: Resilient Distributed Datasets (RDDs) Distributed collections of objects that can be stored in memory for fast reuse Automatically recover lost data on failure Support a wide range of applications
- 10. Outline Spark programming model User applications Implementation Demo What’s next
- 11. Programming Model Resilient distributed datasets (RDDs) » Immutable, partitioned collections of objects » Can be cached in memory for efficient reuse Transformations (e.g. map, filter, groupBy, join) » Build RDDs from other RDDs Actions (e.g. count, collect, save) » Return a result or write it to storage
- 12. Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns BaseTransformed RDD RDD Cache 1 lines = spark.textFile(“hdfs://...”) Worker results errors = lines.filter(_.startsWith(“ERROR”)) messages = errors.map(_.split(„t‟)(2)) tasks Block 1 Driver cachedMsgs = messages.cache() Action cachedMsgs.filter(_.contains(“foo”)).count cachedMsgs.filter(_.contains(“bar”)).count Cache 2 Worker . . . Cache 3 Worker Block 2 Result: scaled tosearch of Wikipedia full-text 1 TB data in 5-7 sec in <1 sec (vs 20 for on-disk data) (vs 170 sec sec for on-disk data) Block 3
- 13. RDD Fault Tolerance RDDs track the series of transformations used to build them (their lineage) to recompute lost data E.g: messages = textFile(...).filter(_.contains(“error”)) .map(_.split(„t‟)(2)) HadoopRDD FilteredRDD MappedRDD path = hdfs://… func = _.contains(...) func = _.split(…)
- 14. Example: Logistic Regression Goal: find best line separating two sets of points random initial line target
- 15. Example: Logistic Regression val data = spark.textFile(...).map(readPoint).cache() var w = Vector.random(D) for (i <- 1 to ITERATIONS) { val gradient = data.map(p => (1 / (1 + exp(-p.y*(w dot p.x))) - 1) * p.y * p.x ).reduce(_ + _) w -= gradient } println("Final w: " + w)
- 16. Logistic Regression Performance 4000 3500 110 s / iteration Running Time (s) 3000 2500 2000 Hadoop 1500 Spark 1000 500 0 first iteration 80 s further iterations 6 s 1 5 10 20 30 Number of Iterations
- 17. Spark Users
- 18. User Applications In-memory analytics on Hive data (Conviva) Interactive queries on data streams (Quantifind) Exploratory log analysis (Foursquare) Traffic estimation w/ GPS data (Mobile Millennium) Algorithms for DNA sequence analysis (SNAP) ...
- 19. Conviva GeoReport Hive 20 Spark 0.5 Time (hours) 0 5 10 15 20 Group aggregations on many keys with the same WHERE clause 40× gain over Apache Hive comes from avoiding repeated reading, deserialization and filtering
- 20. Quantifind Stream Analysis Parsed Extracted Relevant Data Feeds Insights Documents Entities Time Series Load new documents every few minutes Compute an in-memory table of time series Let users query interactively via web app
- 21. Implementation Runs on Apache Mesos cluster Spark Hadoop MPI manager to coexist w/ … Hadoop Mesos Supports any Hadoop storage Node Node Node system (HDFS, HBase, …) Easy local mode and EC2 launch scripts No changes to Scala
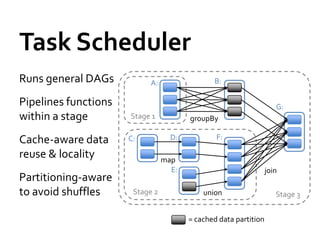
- 22. Task Scheduler Runs general DAGs A: B: Pipelines functions G: within a stage Stage 1 groupBy Cache-aware data C: D: F: reuse & locality map E: join Partitioning-aware to avoid shuffles Stage 2 union Stage 3 = cached data partition
- 23. Language Integration Scala closures are Serializable Java objects » Serialize on master, load & run on workers Not quite enough » Nested closures may reference entire outer scope, pulling in non-Serializable variables not used inside » Solution: bytecode analysis + reflection Interpreter integration » Some magic tracks variables, defs, etc that each line depends on and automatically ships them to workers
- 24. Demo
- 25. What’s Next?
- 26. Hive on Spark (Shark) Compatible port of the SQL-on-Hadoop engine that can run 40x faster on existing Hive data Scala UDFs for statistics and machine learning Alpha coming really soon
- 27. Streaming Spark Extend Spark to perform streaming computations Run as a series of small (~1 s) batch jobs, keeping state in memory as fault-tolerant RDDs Alpha expected by June map reduceByWindow tweetStream T=1 .flatMap(_.toLower.split) .map(word => (word, 1)) .reduceByWindow(5, _ + _) T=2 …
- 28. Conclusion Spark offers a simple, efficient and powerful programming model for a wide range of apps Shark and Spark Streaming coming soon Download and docs: www.spark-project.org @matei_zaharia / matei@berkeley.edu
- 29. Related Work DryadLINQ » Build queries through language-integrated SQL operations on lazy datasets » Cannot have a dataset persist across queries Relational databases » Lineage/provenance, logical logging, materialized views Piccolo » Parallel programs with shared distributed hash tables; similar to distributed shared memory Iterative MapReduce (Twister and HaLoop) » Cannot define multiple distributed datasets, run different map/reduce pairs on them, or query data interactively
- 30. Related Work Distributed shared memory (DSM) » Very general model allowing random reads/writes, but hard to implement efficiently (needs logging or checkpointing) RAMCloud » In-memory storage system for web applications » Allows random reads/writes and uses logging like DSM Nectar » Caching system for DryadLINQ programs that can reuse intermediate results across jobs » Does not provide caching in memory, explicit support over which data is cached, or control over partitioning SMR (functional Scala API for Hadoop)
- 31. Behavior with Not Enough RAM 100 68.8 Iteration time (s) 58.1 80 40.7 60 29.7 40 11.5 20 0 Cache 25% 50% 75% Fully disabled cached % of working set in cache
Editor's Notes
- Point out that Scala is a modern PL etcMention DryadLINQ (but we go beyond it with RDDs)Point out that interactive use and iterative use go hand in hand because both require small tasks and dataset reuse
- Each iteration is, for example, a MapReduce job
- RDDs = first-class way to manipulate and persist intermediate datasets
- You write a single program similar to DryadLINQDistributed data sets with parallel operations on them are pretty standard; the new thing is that they can be reused across opsVariables in the driver program can be used in parallel ops; accumulators useful for sending information back, cached vars are an optimizationMention cached vars useful for some workloads that won’t be shown hereMention it’s all designed to be easy to distribute in a fault-tolerant fashion
- Key idea: add “variables” to the “functions” in functional programming
- Note that dataset is reused on each gradient computation
- Key idea: add “variables” to the “functions” in functional programming
- 100 GB of data on 50 m1.xlarge EC2 machines
- Mention it’s designed to be fault-tolerant
- NOT a modified versionof Hadoop