TechEvent Databricks on Azure
•Download as PPTX, PDF•
2 likes•412 views

Apache Spark is a fast and general engine for large-scale data processing. It was created by UC Berkeley and is now the dominant framework in big data. Spark can run programs over 100x faster than Hadoop in memory, or more than 10x faster on disk. It supports Scala, Java, Python, and R. Databricks provides a Spark platform on Azure that is optimized for performance and integrates tightly with other Azure services. Key benefits of Databricks on Azure include security, ease of use, data access, high performance, and the ability to solve complex analytics problems.
Report
Share








































TechEvent Databricks on Azure
- 1. BASEL BERN BRUGG DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. GENEVA HAMBURG COPENHAGEN LAUSANNE MUNICH STUTTGART VIENNA ZURICH Databricks on Azure Spark on the Azure Cloud Marco Amhof Aron Weller
- 2. The Components and the history
- 3. CONTROL EASE OF USE Azure Data Lake Analytics Azure Data Lake Store Azure Storage Any Hadoop technology, any distribution Workload optimized, managed clusters Data Engineering in a Job-as-a-service model Azure Marketplace HDP | CDH | MapR Azure Data Lake Analytics IaaS Clusters Managed Clusters Big Data as-a-service Azure HDInsight Frictionless & Optimized Spark clusters Azure Databricks BIGDATA STORAGE BIGDATA ANALYTICS ReducedAdministration Available Big Data Solutions onAzure
- 5. What is Apache Spark Apache Spark is a fast and general engine for large-scale data processing • Created by UC Berkeley AmpLab • The hot trend in Big Data! • Based on 2007 Microsoft Dryad paper • Written in Scala, supports Java, Python, SQL and R • Can run programs over 100x faster than Hadoop MapReduce in memory, or more than 10x faster on disk • Runs everywhere – runs on Hadoop, Mesos, standalone or in the cloud • Databricks is the main contributor and also the main commercial vendor of Spark
- 6. Apache Spark • In-memory computing capabilities deliver speed • General execution model supports wide variety of use cases • Ease of development by native APIs • Java • Scala • Python • R Spark Use Cases • Ad hoc, exploratory, interactive analytics • Real-time + Batch Analytics • Real-Time Machine Learning • Real-Time Graph Processing • Approximate, Time-bound queries • … Databricks provides a performance optimized Spark Plattform! (Up to 5 times faster than open source Spark)
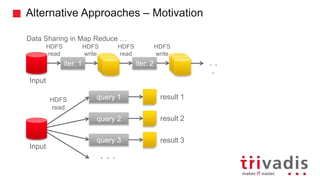
- 7. Alternative Approaches – Motivation Data Sharing in Map Reduce … iter. 1 iter. 2 . . . Input HDFS read HDFS write HDFS read HDFS write Input query 1 query 2 query 3 result 1 result 2 result 3 . . . HDFS read
- 8. iter. 1 iter. 2 . . . Input Alternative Approaches – Motivation What we would be more efficient … this is what Spark offers! Distributed memory Input query 1 query 2 query 3 . . . one-time processing
- 9. Spark: A brief history
- 10. Apache Spark Spark Unifies: Batch Processing Interactive SQL Real-time processing Machine Learning Deep Learning Graph Processing An unified, open source, parallel, data processing framework for Big Data Analytics Spark Core Engine Spark SQL Interactive Queries Spark Structured Streaming Stream processing Spark MLlib Machine Learning Yarn Mesos Standalone Scheduler Spark MLlib Machine Learning Spark Streaming Stream processing GraphX Graph Computation
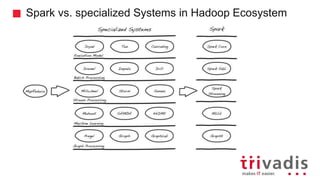
- 11. Spark vs. specialized Systems in Hadoop Ecosystem
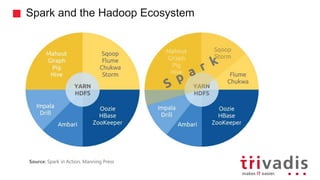
- 12. Spark and the Hadoop Ecosystem Source: Spark in Action, Manning Press
- 13. Databricks Spark offers very high performance Benchmarks have shown Databricks to often have better performance than alternatives
- 14. Databricks - Company Overview • Founded in late 2013 • By the creators of Apache Spark, original team from UC Berkeley AMPLab • Largest code contributor code to Apache Spark • Provides support • Provides certifications • Main Product: The Unified Analytics Platform
- 15. Databricks from Architecture View
- 16. Azure Databricks Azure Databricks is a first party service on Azure. Azure Databricks is integrated seamlessly with Azure services: • Azure Portal: Service an be launched directly from Azure Portal • Azure Storage Services: Directly access data in Azure • Azure Active Directory: For user authentication • Azure SQL DW and Azure Cosmos DB: Enables you to combine structured and unstructured data for analytics • Apache Kafka for HDInsight: Enables you to use Kafka as a streaming data source or sink • Azure Billing: You get a single bill from Azure • Azure Power BI: For rich data visualization Microsoft Azure
- 17. Optimized Databricks Runtime Engine DATABRICKS I/O SERVERLESS Collaborative Workspace Cloud storage Data warehouses Hadoop storage IoT / streaming data Rest APIs Machine learning models BI tools Data exports Data warehouses Azure Databricks Enhance Productivity Deploy Production Jobs & Workflows APACHE SPARK MULTI-STAGE PIPELINES DATA ENGINEER JOB SCHEDULER NOTIFICATION & LOGS DATA SCIENTIST BUSINESS ANALYST Build on secure & trusted cloud Azure Databricks
- 18. Azure Databricks Core Components Azure Databricks
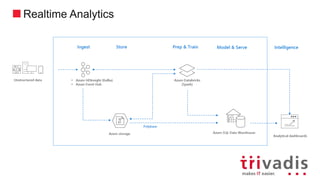
- 19. Business / custom apps (Structured) Logs, files and media (unstructured) Azure Storage Polybase Azure SQL Data Warehouse Data Factory Data Factory Azure Databricks (Spark) Analytical dashboards (PowerBI) Model & ServePrep & TrainStoreIngest Intelligence Modern Data Analytics Landscape Azure Analysis ServicesOn Prem, Cloud Apps & Data
- 21. Analytics on Big Data using Data Science
- 23. ProvisioningAzure Databricks Azure Databricks is provisioned directly from the Azure Portal like any other Azure service • With Azure Databricks, the Azure Portal offers a unified portal to provision and administer Azure Databricks as well as other Azure services. Any Azure user with the appropriate subscription and authorization can provision Azure Databricks service. • There is no need for a separate Databricks account
- 24. Spark Machine Learning Overview Offers a set of parallelized machine learning algorithms Supports Model Selection (hyperparameter tuning) using Cross Validation and Train-Validation Split. Supports Java, Scala or Python apps using DataFrame-based API. Benefits include: – An uniform API across ML algorithms and across multiple languages – Optimizations through Tungsten and Catalyst Spark MLlib comes pre-installed on Azure Databricks 3rd Party libraries supported include: H20 Sparkling Water, SciKit- learn, XGBoost and more
- 25. MMLSpark Microsoft Machine Learning Library for Apache Spark (MMLSpark) lets you easily create scalable machine learning models for large datasets. It includes integration of SparkML pipelines with the Microsoft Cognitive Toolkit and OpenCV, enabling you to: Ingress and pre-process image data Featurize images and text using pre-trained deep learning models Train and score classification and regression models using implicit featurization
- 26. Visualization inside Azure Databricks Azure Databricks supports a number of visualization plots out of the box ! All notebooks, regardless of their language, support Databricks visualizations. When you run the notebook the visualizations are rendered inside the notebook in-place The visualizations are written in HTML. You can change the plot type just by picking from the selection
- 27. Advance Visualization using Power BI Enables powerful visualization of data in Spark with Power BI Power BI is a business analytics tool that provides data Visualization, Report and Dashboard throughout an organization Power BI Desktop can connect to Azure Databricks clusters to query data using JDBC/ODBC server that runs on the driver node.
- 29. Secure Collaboration Azure Databricks enables secure collaboration between colleagues Fine Grained Permissions AAD-based User Authentication
- 30. Security Databricks fully integrated with the Azure Platform Active Directory – Impersonation Information – Network Security – Storage Security – etc. No crossing network borders for connecting to sources Encrypted end to end communication
- 31. Ease of use Databricks fully integrated with the Azure Platform One entry point, the Azure Portal Simplified access to your data Webbrowser based notebook application – Developers playground – Analysts environment Pay only while you use One billing point, Azure Platform
- 32. Data Access Databricks fully integrated with the Azure Platform Azure Storage – Blob Storage – Data Lake Store Azure Databases – SQL Server Data Warehouse (Relational) – Cosmos DB (NoSQL) Azure Event Hub etc.
- 33. Performance Databricks fully integrated with the Azure Platform Direct access to the data – Files – Databases – Virtual machines Direct access to the event hub Databricks optimized Spark Azure performance
- 35. Name Presentation35 9/26/2018 Problems solved using Databricks on Azure
- 36. Complex Architecture Using Spark on Azure is hard. It needs a complex architecture to get and use the data without loosing the tight security of Azure. Active Directory
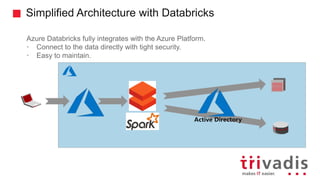
- 37. Simplified Architecture with Databricks Azure Databricks fully integrates with the Azure Platform. • Connect to the data directly with tight security. • Easy to maintain. Active Directory
- 38. Use Cases
- 39. Computer Science Powerhouse as base platform for data science Efficient machine learning libraries included – simply import the MLLib-Libraries and use them Use what you know best – use R, Python, Scala, Java or even SQL for your analysis Power to fit – use clusters to speed up training of your models
- 40. Marketing Get more information in the 360 degree customer view Gain deeper insights in social media – aggregated, filtered and weightened See trends faster – more wide field of information sources Get sight on potencial customers you would miss – using graph technology to identify in a big mass of potencial customers
- 41. Industry Optimize your productivity, efficiency and machine maintainance Leverage sensor data using data science – predictive maintainance on machines – potencial on higher throughput on machines Access to a more wide source of information – identify new markets based on recent customer segments – faster time to market
- 44. Mixing Languages in Notebooks Normally a notebook is associated with a specific language. However, with Azure Databricks notebooks, you can mix multiple languages in the same notebook. This is done using the language magic command: • %python Allows you to execute python code in a notebook • %sql Allows you to execute sql code in a notebook • %r Allows you to execute r code in a notebook • %scala Allows you to execute scala code in a notebook • %sh Allows you to execute shell code in your notebook. • %fs Allows you to use Databricks Utilities - dbutils filesystem commands. • %md To include rendered markdown
- 45. Spark Structured Streaming Comparison
- 46. Spark - Benefits Performance Using in-memory computing, Spark is considerably faster than Hadoop (100x in some tests). Can be used for batch and real-time data processing. Developer Productivity Easy-to-use APIs for processing large datasets. Includes 100+ operators for transforming. Ecosystem Spark has built-in support for many data sources, rich ecosystem of ISV applications and a large dev community. Available on multiple public clouds (AWS, Google and Azure) and multiple on-premises distributors Unified Engine Integrated framework includes higher-level libraries for interactive SQL queries, Stream Analytics, ML and graph processing. A single application can combine all types of processing.