







































Выбор NoSQL базы данных для вашего проекта: "Не в свои сани не садись"
- 1. Выбор NoSQL базы данных для вашего проекта: "Не в свои сани не садись" Докладчик: Алексей Зиновьев
- 2. ● аспирант ОмГУ, математик ● занимаюсь теорией графов, прогнозированием пробок, исследованием транспортных систем ● большой фанат различных Maps API ● лидер GDG Omsk, соорганизатор IT-субботников
- 3. О чем этот доклад? Отдохнул на базе… данных
- 4. Мир NoSQL баз данных велик и ужасен и каждая хороша в чем-то своем. А в чем именно? На чем основываться, выбирая NoSQL решение для своего проекта? Может быть на предпочтениях бабушки вашего ведущего программиста или на основе забрасывания сапога за ворота в ночь перед Рождеством? Давайте попробуем разобраться в критериях оценки и выявить различия между самыми популярными вариантами. Нас ждет увлекательный полет над гладью болот MongoDB, Cassandra, Riak, Hbase, Neo4j, CouchDB. А в тихом омуте, как известно, и черти водятся.
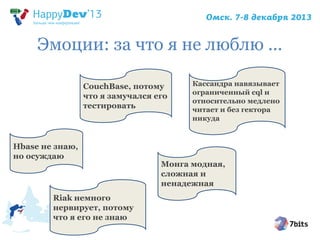
- 5. Эмоции
- 6. Эмоции ● То, что мы чувствуем важно ● Мода и тренд ● Протест и компромисс ● Запечатление и эффект якоря влияют на нас не меньше чем умные статьи ● Через это должен пройти каждый и этот этап не стоит откладывать
- 7. Эмоции: за что я не люблю ... CouchBase, потому что я замучался его тестировать Кассандра навязывает ограниченный cql и относительно медлено читает и без гектора никуда Hbase не знаю, но осуждаю Монга модная, сложная и ненадежная Riak немного нервирует, потому что я его не знаю
- 9. Мифы - это часть борьбы Утверждение Процент согласных Mongo - ненадежна и падает 45% Cassandra надежна, устойчива и почти не падает 53% CouchDB предназначен для веба 35% Neo4j нужен только, чтобы хранить граф социальных сетей 54% Hbase нужна только тем, кто не может прикрутить к Hadoop другой нормальной базы 70% Mongo имеет отличный встроенный MapReduce 62% Cassandra навязывает нам SQL - подход 86%
- 10. Суровая реальность ● Нет базы “моей мечты” ● Чтобы решать задачи, необходимо знакомство с основными парадигмами и их воплощениями ● Если вы будете, вопреки голосу разума, цепляться за первую любовь - вас ждет поражение
- 11. Принципы приличной NoSQL ● Масштабируемость (автоматическое распределение данных) ● Поддержка нескольких датацентров ● Возможность добавлять прозрачно новые сервера ● Собственная, отличная от реляционной, модель данных ● Согласованность в конечном счете
- 12. Критерии сравнения NoSQL ● ● ● ● ● ● ● ● ● ● ● кривая обучения производительность возможности языка запросов свои фреймворки и “ORM” простота интеграции с Hadoop, поддержка MapReduce поддержка основных языков программирования наличие вспомогательных средств для работы мобильная версия СУБД поддержка основных концепций по управления данными сфера влияния и распространение в проектах наличие конкурентов при решении определенной задачи
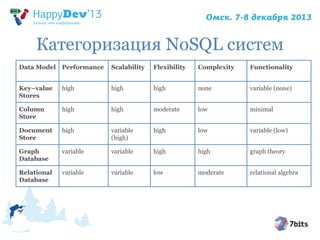
- 13. Категоризация NoSQL систем Data Model Performance Scalability Flexibility Complexity Functionality Key–value Stores high high high none variable (none) Column Store high high moderate low minimal Document Store high variable (high) high low variable (low) Graph Database variable variable high high graph theory Relational Database variable variable low moderate relational algebra
- 14. Сравнение возможностей I Модель данных API запросов Система хранения данных Cassandra Семейства столбцов Thrift Memtable/SSTable CouchDB Документы Map/Reduce Append-only-B-tree Hbase Семейства столбцов Thrift, REST Memtable/SSTable on HDFS MongoDB Документы Cursor B-tree Neo4j Графы Graph On-disk linked lists Riak Ключ/Значение Nested hashes, REST Hash
- 15. Сравнение возможностей II Вторичные индексы MapReduce Произвольные запросы Cassandra да нет CQL (no joins) CouchDB да JavaScript временные представления Hbase нет Hadoop слабая поддержка MongoDB да JavaScript полный набор (no joins) Neo4j да (с помощью Lucene) нет (графы и MapReduce?) обход графа, поиск Riak да JavaScript, Erlang слабая поддержка, Lucene
- 16. Riak: преимущества ● Отказоустойчивость (кольцо) ● Links (ссылки на другие ключи) + фильтры ключей ● MapReduce (Erlang + JS) ● REST ● Подсистема поиска ● Возможность настройки параметров согласованности и доступности на уровне отдельного запроса
- 17. Riak: недостатки ● Бедные возможности запросов ● Нет ACID ● Неполноценная поддержка JavaScript ● Отсутствие поддержки структур данных
- 18. Mongo: преимущества ● ● ● ● Полноценный язык запросов Aggregation framework Mongo + Node.js + JS Хранение сложных денормализованных документов ● Большой выбор индексов (Btree, 2d, 3d ● Репликация данных и сегментирование коллекций ● Community
- 19. Mongo: недостатки ● Ограничение на размер результата (16 Мб) ● Проблема четного числа узлов и сложные выборы ● Опечатка стоит дорого ● Над планированием кластера надо думать ● Иногда навязывает воспроизведение схемы в коде (проверка типов и т.д.)
- 20. CouchDB: преимущества ● Функции-фильтры и как следствие “псевдошардинг” ● Мобильная версия ● Простота встраивания и резервного копирования ● Функции-валидаторы, функции-представления, функции-фильтры сохраняются в текстовом виде в самой базе данных
- 21. CouchDB: недостатки ● Не всегда удобная система репликации (“все или ничего”) ● Неполноценный язык запросов, основанный на MapReduce операциях над представлениями ● Нет нормального механизма сегментирования
- 22. HBase: преимущества ● Версионирование и сжатие ● Горизонтальное масштабирование ● Первое место по обработке трудоемких запросов ● Быстрое восстановление после отказа ● Отзывчивое community энтузиастов ● Тесная интеграция с Hadoop
- 23. HBase: недостатки ● Суровая документация и высокий порог вхождения ● Заимствованная терминология из мира SQL скорее мешает ● Надо не менее 5 узлов ● Нет средств сортировки и индексирования ● Строгая согласованность без возможности изменений
- 24. Cassandra: преимущества ● Высокая доступность, восстановление на ходу ● Нет центральной точки отказа ● Datastax, Hector и все-все-все ● CQL - SQL без join ● Строка может динамически раcширяться до 2 миллиардов колонок ● Резервное копирование не нужно
- 25. Cassandra: недостатки ● Непростая (по сравнению с Hbase) интеграция с Hadoop ● Моделирование таблиц зависит от ваших запросов ● Нет ACID, нет откатов ● Сложность в моделировании (необходимо сильно поменять взгляд на моделирование данных) ● Требовательная к RAM
- 26. Neo4j: преимущества ● Оптимальна для сильносвязанных сущностей ● Вершины, ребра, атрибуты ● Индексы на значения атрибутов ● ACID ● REST API + Cypher ● Множество плагинов, включая 2d индекс
- 27. Neo4j: недостатки ● Нет полноценного горизонтального масштабирования ● Плохо приспособлен для размещения на нескольких машинах ● Для полноценного удаления приходится перезапускать сервер
- 29. Чемпионы-тяжеловесы Граф Число вершин Число ребер Объем данных на диске Прирост в день Web-граф 1 трлн 8 трлн 100 PB 300 TB Facebook (граф 1 млрд друзей) 140 млрд 1 PB 15 TB Дорожный граф Европы 18 млн 42 млн 20 GB 50 MB Дорожный граф Омска 80 000 160 000 300 MB 500 KB
- 33. Фаза исследования Эту фазу не стоит пропускать, ибо это единственная фаза, которая позволяет вам экономить деньги. До ее начала необходимо ответить себе на вопросы о характере ваших данных и сформулировать требования по их использованию.
- 34. Первая развилка: связи В вашем приложении есть сеть данных, граф знаний, а самый популярный запрос связан с обходом сложной иерархии объектов? Вы готовы отказаться размещения на нескольких машинах? Neo4j спешит на помощь!
- 35. Вторая развилка: BigData Данные о достаточно большом количестве объектов, изменяющихся во времени и пространстве (движения звезд, личная переписка, фотки в Instagram)
- 36. Вторая развилка: BigData Придется попрощаться с SQL и наращиванием мощности одного сервера. Впрочем и Neo4j для этого не готов
- 37. Третья развилка: простота Нужно лишь чтение/запись по ключу, безграничное масштабирование, отсутствие точек общего отказа Между данными почти нет связей. Riak оставляет всех позади себя, добавляя возможность MapReduce над вашими данными.
- 38. Четвертая развилка: иерархия Структура данных отличается высокой изменчивостью и большой вложенностью. Связность отдельных сегментов данных невысока. Riak уходит, на сцену выходит Mongo DB, кружась в смертельном танго с CouchDB.
- 39. Пятая развилка: отчеты Необходима обработка и сложная агрегация данных при помощи Hadoop. Данные довольно плоские. Hbase царствует безраздельно, но Cassandra наступает ей на пятки, предлагая ряд преимуществ.
- 40. О данных замолвите слово ● Данные - это океан, полный морских существ ● Но пока они не выловлены, пользы от никакой ● Средство лова: удочку, сеть, глушить гранатой или вычерпывать кастрюлей, выбираем мы сами
- 41. Список источников 1. Эрик Редмонд, Джим Р. Уилсон “Семь баз данных за семь недель” 2. “A generic intro to NoSQL” by Ben Scofield. 3. http://nosql-database.org/ 4. Исследования компании Тамтэк 5. Собственные исследования
- 42. Данные - все, способ хранения - ничто!
- 43. Вопросы?