


AIスタートアップ・Preferred Networks(東京都千代田区、以下PFN)は11月15日、大大規模言語モデルなど生成AI向けの独自プロセッサ「MN-Core L1000」の開発を始めると発表した。生成AIの推論時に、GPUなどの既存プロセッサに比べ最大10倍の高速処理を目指す。提供予定は2026年。 PFNでは16年から、深層学習の特徴である行列演算に最適化した独自プロセッサ「MN-Core」シリーズの開発を神戸大学と共同で進めている。L1000ではこれに、「三次元積層DRAM」という最新技術を組み合わせる。 三次元積層DRAMは、演算器に対してメモリを垂直方向に積載することで、従来のハイエンドGPUが搭載するHBM(high bandwidth memory)と比べてもメモリ帯域幅を拡大できるという。近年のAIプロセッサで利用が広がるSRAM(static random ac

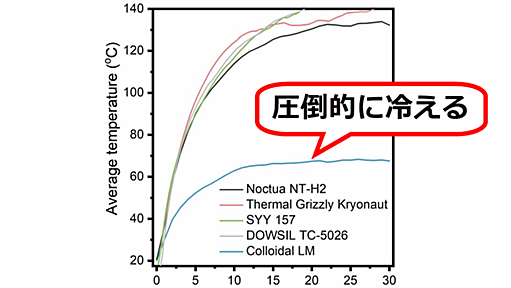
四川大学とテキサス大学オースティン校の共同研究チームが液体金属と窒化アルミニウムを混合した熱伝導材料を開発しました。新開発の材料はCPUなどの熱を効率的に放熱可能で、市販のCPUグリスと比べて圧倒的に高い放熱性能を備えていることが確かめられています。 Mechanochemistry-mediated colloidal liquid metals for electronic device cooling at kilowatt levels | Nature Nanotechnology https://www.nature.com/articles/s41565-024-01793-0 Prof. Fu Qiang /Wu Kai's Team Made Progress in Colloidal Thermal Conductive Materials-Sichuan Univer
フランスの市場調査会社Yole Groupは、フラグシップスマートフォン用のアプリケーションプロセッサを調査し、「APU - Smartphone SoC Floorplan Comparison 2024(APU - スマートフォン向けSoCのフロアプラン比較 2024)」と題する研究の分析概要を発表した。【訂正あり】 フランスの市場調査会社Yole Groupは、フラグシップスマートフォン用のアプリケーションプロセッサを調査し、「APU - Smartphone SoC Floorplan Comparison 2024(APU -スマートフォン向けSoCのフロアプラン比較 2024)」と題する研究の分析概要を発表した。この調査は、ファウンドリー技術からパッケージング、コスト分析に至るまでさまざまな技術分野を網羅し、特にSoC(System on Chip)アーキテクチャに重点を置いて

「アーキテクチャライセンス」はArmのビジネスモデル Armは、スマートフォン/タブレットやPC、組み込み機器で使われるCPUやGPUの“アーキテクチャ”の設計をなりわいとしている。 「それならIntelやAMD、NVIDIAと同じでは?」と思う人もいるかもしれないが、これらの企業は、自ら設計したCPU/GPUを自社で販売している。それに対して、Armは自らCPU/GPUを販売していない。「ならどうやって生計を立てているの?」という点だが、アーキテクチャをもっぱら他社にライセンス(利用許諾)することで生計を立ている。 AppleやMediaTekなど、同社のライセンス供与先は多岐に渡る。QualcommもArmとライセンス契約を締結し、その上で同社のSoC(System on a Chip)に搭載するCPUコアの設計を行ってきた。 ArmはなぜQualcommへのライセンスを取り消すのか?

科学の世界では、それまでの常識が覆ることを俗に「パラダイムシフト」と呼ぶ。 しかし、もしもAIの世界にパラダイムシフトという言葉があるとしたら、今週の人類は一体何度のパラダイムシフトを経験しただろうか。 そのトドメの一撃とも言えるのが、BitNetのLlama8B版だ。 Lllama-8B構造で学習された最初のBitNetであり、全てを変えてしまうゲームチェンジャーでもある。CPUのみで秒間5-20トークンを出力する。超強力なLLM推論エンジンの出現だ。 BitNetとは、そもそも1.58ビットに相当する情報量で、本来は4ビット以上必要な大規模言語モデルの計算を劇的に高速化する技術である。 LLMの推論には通常は巨大な浮動小数点数(8ビットから16ビット)の、大量の乗算(掛け算)が必要なため、GPUなどの特殊な半導体を必要としていた。特にNVIDIAのGPUがこの目的にマッチしていたので今

Intel,デスクトップPC向け新CPU「Core Ultra 200S」を発表。前世代でバカ高かった消費電力を大幅に減らす ライター:米田 聡 2024年10月11日,Intelは,新世代のデスクトップPC向けCPU「Core Ultra 200S」シリーズ(開発コードネーム Arrow Lake-S)を発表した。 これまでIntelは,ノートPC向けに開発コードネーム「Meteor Lake」こと,「Core Ultra 100」シリーズで,「Foveros」と称する3Dパッケージング技術を使用して複数のシリコンチップを組み合わせたプロセッサを提供してきた。しかしデスクトップPC向けCPUは,現行世代の第14世代Coreプロセッサまで,モノリシック(単一のシリコンチップ)構成を続けてきた。新しいCore Ultra 200Sシリーズは,デスクトップPC向けとして初めて,3Dパッケージン

「Core Ultra 200Sシリーズ」発表&予約販売開始! 最上位のCore Ultra 9は激レア? 2024年10月11日0時(日本時間)、インテルは開発コード“Arrow Lake”として知られてきた新世代のデスクトップPC向けCPUを「Core Ultra 200Sシリーズ」として正式発表した。2009年、インテルが初めて「Core i」の名を冠した製品を投入して以来、最新のCoreプロセッサーまで14もの世代を重ねてきたシリーズはひとまず終了。今後はモバイル向けCPUと同様に“i”のない「Core Ultra 9」や「Core Ultra 7」「Core Ultra 5」というブランドになる。 本稿はインテルが開催したメディア向けブリーフィングの内容・資料の中から、Core Ultra 200Sシリーズの価格/プラットフォーム/パフォーマンスの3つにフォーカスしてまとめたもの

従来、CPUコアは製造時のテストをパスすれば信頼できると考えられてきた。しかし、半導体の微細化が進み、CPUの構造が複雑化するにつれ、製造時には検出できない潜在的な欠陥が増えていることが明らかになってきた。これらの欠陥は使用中に顕在化し、静かにデータ破壊を引き起こす可能性がある。 正常なCPUがまれに計算エラーを起こす。厄介なことに、このエラーは多くの場合“サイレント”であり、誤った計算結果が唯一の症状となる。そのためエラーが発生したことに気付くのが非常に難しい。エラーが検出されずに後続の計算に影響を与え、被害が拡大するケースもある。 研究者らはこの問題を「計算実行エラー」(Computational Execution Errors、CEE)と呼んでいる。調査によると、大規模サーバ群では数千台に数個の割合でCEEが発生しているとのこと。これは単なるランダムなハードウェアエラーの増加ではな

大きな転換点を迎えるPCプラットフォーム Core Ultra(シリーズ2)とApple M4チップの「類似性」と決定的な「差異」:本田雅一のクロスオーバーデジタル(3/3 ページ) PC向けSoC(CPU)のトレンドに大きな変化が起こる可能性 技術的な優位性というのは、うつろうものだ。全体を俯瞰した中で、特定のメーカーだけが特別に優秀なチップを作り出す、なんてことはもちろんあり得るとは思う。しかし、AppleやIntelのような巨大企業が英知を振り絞って奮起している時、それが成果としての結実するのは「技術的な優位性」よりも「コンセプト」を重視した場合に多いと思われる。 繰り返しになるが、Apple Siliconが素晴らしい成果を上げた理由はPCを“完全な”垂直統合体制で開発できる企業が他に存在しないからだ。 ただ、「どのようにすれば優れた製品が生まれるか」という見本を見せれば、それをま

イギリスの半導体メーカー・Pragmatic Semiconductorがハーバード大学などと共同で、ぐにゃぐにゃと曲げられるCPU「Flex-RV」を開発しました。このチップは一般的なシリコンチップとは違って柔軟な素材で作られており、Pragmatic Semiconductorは実際にFlex-RVをペンに巻きつけながら動作させる映像を公開しています。 Bendable non-silicon RISC-V microprocessor | Nature https://www.nature.com/articles/s41586-024-07976-y A Bendable Non-silicon RISC-V Microprocessor - Pragmatic Semiconductor, Qamcom, Harvard - YouTube Flex-RVは、オープンソースの命令

これはなかなかいいんでないの?NVIDIAチップの5倍高速で価格1/10の中国AIチップ搭載コンピュータ Maker Faire Tokyo 2024に行ってきた。 深圳在住の高須さんが僕を見るなり「これ見てこれ」と連れていかれ、新製品のRDK X3を紹介された。 RDK X3とは何かというと、要は最新のAIチップを搭載したシングルボードマイコン、つまりRaspberry Piのようなものである。 このチップの中核にあるSunrise3(通称X3)チップは4つのCortex-A53ARMの高性能コアと、二つデュアル構成のBernoulliベルヌーイBPUだという。 このベルヌーイというNPUは初耳だが、とにかく速くてすごいらしい。5TOPS、つまり一秒間に5兆回の計算ができるらしい。ただ、「何の計算」を「5兆回」なのかがイマイチ明確になっておらず、ちょっとモヤモヤする。 ちなみに最近Mic

米Intelが2022年にソニーの「PlayStation 6」チップの設計・製造契約を逃したことが、まだ始まったばかりの受託製造事業の構築に大きな打撃を与えたと、事情を知る3人の情報筋が明らかにした。 Intelが、次期PlayStation 6チップの設計で米アドバンスト・マイクロ・デバイセズ(AMD)と、受託製造業者として台湾セミコンダクター・マニュファクチャリング・カンパニー(TSMC)と競争入札プロセスで勝利しようとした努力は、数十億ドルの収益と月数千枚のシリコンウェーハの製造に相当しただろうと、情報筋の2人は語った。 IntelとAMDは、契約の入札プロセスで最終候補に残った2社だった。 ソニーのPlayStation 6チップの設計事業を獲得することは、Intelの設計部門にとっての勝利となり、同時に同社の受託製造事業、すなわちファウンドリ事業にとっても勝利となったはずだ。フ

LinkedInの記事をめぐっているうちに見つけた、マイクロアーキテクチャに関する面白い事例。 CPUのマイクロアーキテクチャのさらに奥深くまで理解が必要な問題を解決するために、どのようなツールをつかってどのように解決したかの話。 netflixtechblog.com Netflix内でのワークロード最適化のため、AWSのインスタンスサイズを移行(16 vCPUから48 vCPU)し、CPUがボトルネックとなるワークロードの性能向上を図った。 このインスタンスの移行により、性能をほぼ直線的に増加させることを想定し、スループットがおよそ3倍になると予想した。 しかし、結果としてこの移行で想定する性能は達成できなかった。 https://netflixtechblog.com/seeing-through-hardware-counters-a-journey-to-threefold-pe

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く







