 転送中
転送中リダイレクトします 以前ここにあったブログは、現在 http://blog.dotroid.net/2008/03/pythonmysql.html にあります。 リダイレクトしますか。


# encoding: utf-8 import re #文字列に半角カタカナが存在するか? #Pythonの正規表現を使用して、渡された文字列に半角カタカナがあるかチェックします。(UTF-8向け) #Python 正規表現 半角カタカナ UTF8 regexp = re.compile(r'(?:\xEF\xBD[\xA1-\xBF]|\xEF\xBE[\x80-\x9F])') result = regexp.search("aaaaアあああああ") if result != None : print(u"文字列に半角カタカナが存在する".encode('shift_jis')) else : print(u"文字列に半角カタカナが存在しない".encode('shift_jis')) #↓ #"文字列に半角カタカナが存在する"
id:piro_sukeさんがアレコレやってるのを見てちょいと試しているうちに、予想外なところで罠にハマってしまったbonlifeです。同じことで躓く人はあまりいないような気がしますが、備忘録メモです。 csvモジュールで日本語を扱う場合に気をつけないと悲しい気持ちになってしまうかもしれませんよ、というお話。 サンプル1 sys.getdefaultencoding() で得られる文字コードは cp932 ファイルの文字コードは cp932 出力するCSVの文字コードは cp932 # -*- coding: cp932 -*- import sys import csv import codecs print "default encoding : %s" % (sys.getdefaultencoding()) f = codecs.open('out.csv','wb','cp932

30分プログラム、その646。PythonでCSV読み込んでみた。 ソートされた複数のCSVファイルを結合するスクリプト - pgyの日記をやろうとしたけど、うまくいかなかった。 とりあえず、CSV読み込み部分だけをどうぞ。 使い方 $ python csv-read.py data1.csv {'data12': 'data121', 'data11': 'data111', '#id': '1'} {'data12': 'data122', 'data11': 'data112', '#id': '2'} {'data12': 'data123', 'data11': 'data113', '#id': '3'} {'data12': 'data124', 'data11': 'data114', '#id': '4'} {'data12': 'data125', 'data11':

試しにチャット履歴をCSVファイルに保存するという場合の例を取り上げます。まぁ実際はメッセンジャーアプリのXMLファイル等をコンバートして保存する例を持ってきた方が良いのかもしれませんが、そうするとコードが長くなり今記事の焦点が合わなくなるので割愛します。 ソースコード #!/usr/bin/python # coding: UTF-8 # CSVファイルに書き込み import csv # CSVファイルを扱うためのモジュールのインポート filename = "table02.csv" writecsv = csv.writer(file(filename, 'w'), lineterminator='n') # 書き込みファイルの設定 writecsv.writerow(['2007/11/12 20:19:18', 'や、こんばんは。']) # 1行(リスト)の書き込み write

[Home] [Setting up Mac OS X] [Python]: [ファイルを読む] 日本語を使う Pythonで日本語を使う Python 2.4以降では、標準で日本語を扱うことができます。 PythonのソースコードをUTF-8で書くには 日本語を扱うPythonのスクリプトの中では、UTF-8の文字コードを使うのが 楽です。 Mac OS Xのターミナルで日本語を扱う場合は、 ここの「4. Terminalの設定を変える」の 指示に従ってください。 以下、ソースコードの簡単な例を示します。 #!/usr/bin/env python # -*- coding: utf-8 -*- import re jtext = u'子猫が隠れんぼをしています' print 'jtext has', len(jtext), 'Japanese characters.' if re.se
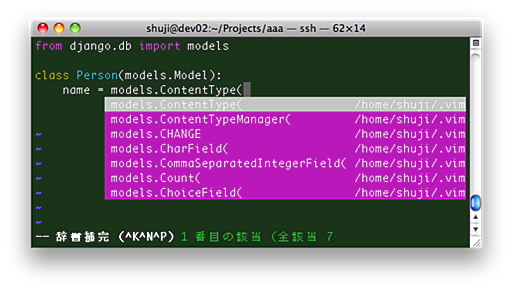
vimでPythonの開発環境を作ってみました。 自動インデント コード補完 スクリプトの実行 インデントの設定 自動 インデントはPythonでコーディングをする場合には必須な機能です。定番の設定があるので、.vimrcに追記します。 filetype plugin on autocmd FileType python setl autoindent autocmd FileType python setl smartindent cinwords=if,elif,else,for,while,try,except,finally,def,class autocmd FileType python setl expandtab tabstop=4 shiftwidth=4 softtabstop=4インデントは4文字でタブ文字ではなく半角スペースで設定するようにしています。また、if等の
Kuwataさんの昨日の日記 http://return0.dyndns.org/log/2009/10/06#s_1 を読んで僕はゲラゲラと笑ってしまった。内容的には、Catyスクリプトの分岐処理のマジメな話で、これで大笑いするのは僕だけだろう。 まず、前後の事情を説明すると、昨日Kuwataさんと打ち合わせて、Catyスクリプトの分岐処理をどうすべきかが話題になった。例を示そう。Kuwataさんが出した例と本質的に同じ: ユーザーがログインしているかどうかをチェックする。 トークン(ワンタイムチケット)をチェックする。 フォームデータが適切かどうかをチェックする。 フォームデータを処理する(ここではエラーチェック不要)。 なにかがまずいなら、適切なページにリダイレクト、またはフォーワードする。 常識的なプログラミング言語(擬似コード)で書けば: if (logged_in()) { i

 Python: 画像で与えられた迷路に対し2点間の最短経路を求める
Python: 画像で与えられた迷路に対し2点間の最短経路を求める
迷路の描かれた画像に対して、ピクセルの座標で指定したスタート地点とゴール地点の最短経路を求めるプログラムをPython+PILで書いてみた。使用する画像は、デジカメで撮ったものでも、ウェブから拾ってきたものでも、ペイントソフトで自作したものでも構わない。 まずは使用例を見て欲しい。この画像は携帯カメラで撮った自作の簡単な迷路だ(画像上)。それに対して指定した2点間の最短経路を赤線で示してみた(画像下)。ピクセル単位で計測しているので赤線が若干ガタガタしていて完全な最短経路ではないがほぼ最短と考えていいだろう。迷路画像(画像上)をmaze01.jpgとし、スタート地点の座標が(240, 160)、ゴール地点の座標が(210, 400)の場合、コマンドラインで以下のように実行する。 maze_solver.py maze01.jpg -s 240 160 -g 210 400 これで最短経路を

Copyright (c) 2005 Dave Kuhlman. All Rights Reserved. This software is subject to the provisions of the MIT License http://www.opensource.org/licenses/mit-license.php. Abstract This document provides an outline for a course on NumPy/SciPy. PyTables and Matplotlib are also discussed. 1 What is SciPy? SciPy is both (1) a way to handle large arrays of numerical data in Python and (2) a way to apply
Recommender Systems 2007(http://recsys.acm.org/2007/)で発表された論文である,Bhaskar Mehta, Thomas Hofmann, and Wolfgang Nejdl, Robust Collaborative Filtering, In Proceedings of the 1st ACM Conference on Recommender Systems, ACM Press, October 2007, pp. 49–56. を読んだメモです.この論文では,ある種の攻撃に耐えられるような,頑強な協調フィルタリングの手法を提案していますが,その説明は後日行うことにして,今回は,関連研究に挙げられていた,特異値分解を用いたレコメンデーションアルゴリズムについて説明を行いたいと思います. 特異値分解 ある任意のm x n行列は下

コンテンツへスキップ 登録は無効化されました。
自然言語処理の技法の1つに、潜在的意味解析(LSA)というものがある。 単語文書行列Aがあった場合、特異値分解(SVD)により A=UΣV に分解し、特異値を大きいほうからk個使って Ak=UkΣkVk のように階数の低減を行うことで、階数kのAへの近似を最小誤差で得ることができる。 つまり特異値分解の計算さえできてしまえばLSAもすぐできるわけだが、 pythonの数値解析モジュールScipyにかかれば特異値分解もあっという間である。 まずは特異値分解まで↓ from numpy import * from scipy import linalg A = matrix([ [5, 8, 9, -4, 2, 4], [2, -4, 9, 4, 3, 3], [-3, 4, 8, 0, 5, 6], [-2, 5, 4, 7, 0, 2] ]) u, sigma, v = linalg.sv

初出: 2007/6/27 更新: 2007/7/1 文章からキーワードを抽出するスクリプトをPythonモジュールとして実装しました。 分かち書きした上に、適切に複合語をつくり、さらに重要そうなものかどうかのスコアをつけます。 アルゴリズムは、以下のサイトを参考にしました。 http://gensen.dl.itc.u-tokyo.ac.jp/ ここで紹介されている論文 * 中川裕志、森辰則、湯本紘彰: "出現頻度と連接頻度に基づく専門用語抽出",自然言語処理、Vol.10 No.1, pp. 27 - 45, 2003年1月 http://www.r.dl.itc.u-tokyo.ac.jp/~nakagawa/academic-res/jnlp10-1.pdf に掲載されているFLR法のみを実装しています。 実行結果サンプル たとえば、こんなページの本文をテキストフ
リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


