1 Introduction
Convolution neural networks (CNNs) have become the go-to solution for a wide range of problems, such as object recognition [
1], speech processing, and machine translation. Deep CNN models trained with large datasets are highly relevant and critical to ever-growing cloud services, such as face identification (e.g., Apple iPhoto and Google Picasa) and speech recognition (e.g., Apple Siri and Google assistant). However, a CNN algorithm involves a huge volume of computationally intensive convolutions. For example, a basic CNN model created in 2012, AlexNet [
2] requires 724 M floating point
multiply-accumulate (MAC) operations just for inference. The floating-point MAC count is more than 20 times in general for training a CNN. Such increase in the number of MAC makes training three order of magnitude higher compute and memory intensive than inference [
5]. As a result, traditional CPUs and GPUs struggle to achieve high processing throughput per watt [
3] for CNN applications. To address this, several FPGA [
4] and ASIC [
5] approaches have been proposed to accomplish large-scale CNN acceleration.
A CNN comprises two stages: training and inference. Most hardware accelerators for CNNs in prior literature focus only on the inference stage, while the training is done offline using GPUs. However, training a CNN is up to several hundred times more compute and power intensive than its inference [
5]. Moreover, for many applications, training is not a one-time activity, especially under changing environmental and system conditions, where re-training of CNN at regular intervals is essential to maintaining prediction accuracy for the application over time. This calls for an energy-efficient training accelerator in addition to the inference accelerator.
Training a CNN, in general, employs a backpropagation algorithm that demands high memory locality and compute parallelism. Recently, a few resistive-memory (ReRAM or memristor crossbar)-based training accelerators have been demonstrated for CNNs, e.g., ISAAC [
5], PipeLayer [
6], and RCP [
7]. ISAAC and RCP use highly parallel memristor crossbar arrays to address the need for parallel computations in CNNs. In addition, ISAAC uses a very deep pipeline to improve system throughput. However, this is only beneficial when a large number of consecutive images can be fed into the architecture. Unfortunately, during training, in many cases, a limited number of consecutive images need to be processed before weight updates. The deep pipeline in ISAAC also introduces frequent pipeline bubbles. Compared to ISAAC, PipeLayer demonstrates an improved pipeline approach to enhance throughput. However, RCP, DPE, ISAAC, and PipeLayer involve several
analog-to-digital (AD) and
digital-to-analog (DA) conversions, which become a performance bottleneck, in addition to their large power consumption. Also, training in these accelerators involves sequential weight updates from one layer to another. This incurs inter-layer waiting time for synchronization, which reduces overall performance. This calls for an analog accelerator that can drastically reduce the number of AD/DA conversions, and inter-layer waiting time. It has been recently demonstrated that a completely analog matrix-vector multiplication is 100× more efficient than its digital counterpart implemented with an ASIC, FPGA, or GPU [
8]. Vandroome et al. [
9] have demonstrated a small-scale efficient recurrent neural network using analog photonic computing. A few efficient on-chip photonic inference accelerators have also been proposed in References [
10,
11,
23]. However, a full-fledged analog deep learning (or CNN to be precise) accelerator that is capable of both training and inference is yet to be demonstrated.
In this article, we propose
LiteCON, a novel silicon photonics-based neuromorphic CNN accelerator. It comprises silicon photonic microdisk-based convolution, memristive memory, high-speed photonic waveguides, and analog amplifiers.
LiteCON works completely in the analog domain, therefore, we use the term neuromorphic in it (a neuromorphic system is made up analog components to mimic human brain behavior, in this case CNN, an artificial neural network). The lower footprint, low-power characteristics, and ultrafast nature of silicon microdisk enhance the efficiency of
LiteCON. LiteCON is a first-of-its-kind memristor-integrated silicon photonic CNN accelerator for end-to-end analog training and inference. It is intended to perform highly energy efficient and ultra-fast training for deep learning applications with state-of-the-art prediction accuracy. The main contributions of this article are summarized as follows:
•
We propose LiteCON, a fully analog and scalable silicon photonics-based CNN accelerator for energy-efficient training;
•
We introduce a novel compute and energy-efficient silicon microdisk-based convolution and backpropagation architecture;
•
We demonstrate a pipelined data distribution approach for high throughput training with LiteCON;
•
We synthesize the
LiteCON architecture using a photonic CAD framework (IPKISS [
16]). The synthesized
LiteCON is used to execute four variants of VGG-Net [
12] and two variants of LeNet [
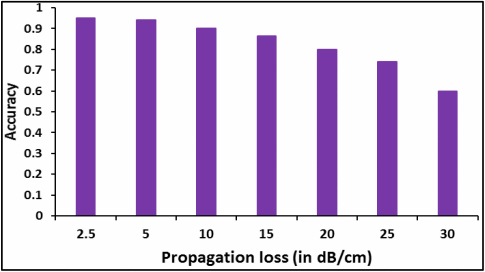
13], demonstrating up to 30×, 34×, and 4.5× improvements during training, and up to 34×, 40×, and 5.5× during inference, in throughput, energy efficiency, and computational efficiency per watt, respectively, compared to the state-of-the-art CNN accelerators.
The rest of the article is organized as follows. Section
2 presents a brief overview of CNNs and prior art. Section
3 provides a gentle introduction of the components used in
LiteCON. The details of the
LiteCON architecture are described in Section
4. Section
5 illustrates an example design of
LiteCON, followed by Section
6, which contains the experimental setup, results, and comparative analysis. Last, we present concluding remarks in Section
7.
5 LiteCON Case Study
In this section, we present the working of the proposed pipelined
LiteCON architecture for a CNN benchmark VGG [
16] on the ImageNet dataset [
17]. In our experiments, we consider all variants of the VGG [
16] and LeNet [
18] benchmarks as shown in Table
1. We integrate the PConv layer, ReLU layer, POOL layer, and FC layer based on VGG-A model for this case study as shown in Figure
6(a). See that for one convolution in
\( {\rm{F}}{{\rm{E}}}_1 \) for VGG-1 (Table
1), there is an equivalent PConv in
\( {\rm{F}}{{\rm{E}}}_1 \) of Figure
6(a); similarly, for two back-to-back convolutions in
\( {\rm{F}}{{\rm{E}}}_3 \) , there are two back-to-back PConv in
\( {\rm{F}}{{\rm{E}}}_3 \) of Figure
6(a). The backpropagation accelerator is connected to the feedforward accelerator as follows: BP-1 with
\( {\rm{F}}{{\rm{E}}}_1 \) , BP-2 with
\( {\rm{F}}{{\rm{E}}}_2 \) , BP-3 with
\( {\rm{F}}{{\rm{E}}}_3 \) , and so on. The rest of the section discusses how
LiteCON mimics VGG-A.
VGG for the ImageNet dataset operates on a 224 × 224 image input. As mentioned earlier, LiteCON is designed to convolve 28 × 28 pixels at a time, i.e., one LiteCON cycle. Therefore, it requires 64 LiteCON cycles to execute a 224 × 224 image. The SRAM register array in LiteCON is of size 256 KB to store five images of size 224 × 224. PConv performs feature extraction on a 28 × 28 input data at a time in a pipelined manner.
Figure
6(b) demonstrates the pipelined dataflow of the feedforward operation in
LiteCON. We consider a 2.5 GHz clock. Therefore, the clock cycle period
\( {{\rm{T}}}_{{\rm{sm}}} = 400 \) ps. As shown in Figure
6(b), at
\( t = {{\rm{T}}}_{{\rm{sm}}} \) , the first set of 28 × 28 pixels from SRAM (i.e., A) are convolved (64 filters/features) and are stored in memristor crossbars (for data storage) (the yellow interface module in Figure
5(a) represents data transfer into memristors in the peripheral circuit). To illustrate the pipelined approach, we explain the convolution of another three set of 28 × 28 pixels, namely, B, C, and D. Note that PConv convolves a 28 × 28 input in one clock cycle (Section
4.1.2). As
\( {\rm{F}}{{\rm{E}}}_1 \) for VGG-A consists of one convolution layer (see Table
1), convolved photonic outputs of PConv-1 of
\( {\rm{F}}{{\rm{E}}}_1 \) is sent to the ReLU layer through the photodiode followed by the POOL layer. The time required for convolved data of one FE to arrive at the next FE,
\( {T}_{FE} \) = photodiode conversion time + ReLU time + POOL time + interface time = 20 ps + 10 ps + 10 ps + 10 ps = 50 ps. From
\( t = {T}_{sm} \) to
\( t = 2{T}_{sm} \) , PConv(A) outputs from the peripheral circuit of
\( F{E}_1 \) are photodiode-converted, ReLUed and POOL'ed, and then fed to
\( {\rm{F}}{{\rm{E}}}_2 \) .
There can be 8 such data movements as
\( \frac{{{T}_{sm}}}{{{T}_{FE}}} = 8 \) . In one data movement, 4 28 × 28 features can be processed. Therefore, at
t = \( 2{T}_{sm} \) , 32 PConv(A) features arrive at
\( {\rm{F}}{{\rm{E}}}_2 \) . Similar to PConv(A), from
\( t = 2{T}_{sm} \) to
\( t = 3{T}_{sm} \) , 32 PConv(B) features; from
\( t = 3{T}_{sm} \) to
\( t = 4{T}_{sm} \) , 32 PConv(C) features; from
\( t = 4{T}_{sm} \) to
\( t = 5{T}_{sm} \) , 32 PConv(D) features are convolved and stored in the peripheral circuit of
\( F{E}_2 \) . After this, from
\( t = 5{T}_{sm} \) to
\( t = 6{T}_{sm} \) , the remaining 32 PConv(A) features in
\( F{E}_1 \) are convolved in
\( F{E}_2 \) . In this way, by
t = \( 6{T}_{sm} \) , all the 64 PConv(A) features in
\( F{E}_1 \) are convolved with 128
\( F{E}_2 \) filters to produce 128 features and stored in the memristors of its peripheral circuit. Similarly, remaining 32 B, C, and D features are convolved and stored (Figure
6(b)) by
\( t = 7{T}_{sm} \) ,
\( t = 8{T}_{sm} \) , and
\( t = 9{T}_{sm} \) , respectively.
\( F{E}_1 \) has 64 features
, \( F{E}_2 \) has 128 features,
\( F{E}_3 \) has 256 features, etc, as per the VGG-A configuration (Table
1). It is important to note that 64 PConv(A) features from
\( F{E}_1 \) are convolved with 128 kernels/filters to produce 128 PConv(A) features for
\( F{E}_2 \) . Similarly, 128 PConv(A) features from
\( {\rm{F}}{{\rm{E}}}_2 \) are convolved with 256 kernels to produce 256 PConv(A) features for
\( F{E}_3 \) .
A, B, C, and D are convolved separately until
\( t = 10{T}_{sm} \) when all of them arrive at
\( F{E}_3 \) as 256 7 × 7 features each. Now, all of these features are merged together to form 256 28 × 28 features. Therefore, it will require another
\( 8{T}_{sm} \) time (i.e.,
\( t = 10{T}_{sm} \) \( \textrm{tot} = 18{T}_{sm} \) ) to send 256 28 × 28 features from
\( F{E}_3 \) and convolve them as 512 14 × 14 features at
\( F{E}_4 \) . Similarly, convolution, ReLU, and POOL are performed in
\( F{E}_4 \) and
\( F{E}_5 \) . As illustrated in Figure
6(b), at
\( t = 24{T}_{sm} \) , 512 features are obtained from
\( F{E}_5 \) for 56 × 56 pixels. As shown in Figure
5(a), features from
\( F{E}_5 \) are stored in SRAM until all the 224 × 224 pixels are extracted. For 224 × 224 pixels, it will take
\( 16 \times 24{T}_{sm} = 384 \) \( {T}_{sm} = 153.6\ \textrm{ns} \) (in
\( 24{T}_{sm},4\;28 \times 28 \) pixels are convolved; therefore,
\( 16 \times 24{T}_{sm} \) for 224 × 224 pixels). After this, all the features are retrieved from SRAM and fed to FC for feature classification. The first FC operation requires
\( ({T}_{sm} + {T}_{FE}) \) time as FC is identical to FE. The second FC operation requires
\( {T}_{FE} \) time as no more SRAM or memristor read is needed. This means that
LiteCON requires 153.6 ns (for FE)
\( + {T}_{sm} + 2T\ = 154 \) ns, for one forward pass. After a forward pass, the FC output is sent to the BP architecture for backpropagation. Each layer in BP requires
\( {T}_b \) units of time where
\( {T}_b \) = (error modulation to light carrier) + (split time) + (WDM multiplexing time) + (split time) + (weight modulation time) + (ReLU function derivative modulation time) + (photodiode time) = 10 ps + 10 ps + 10 ps + 10 ps + 10 ps + 10 ps +20 ps = 80 ps. It takes 6
\( {T}_b \) units of time to complete one backward pass.
In summary, LiteCON requires 154 ns for one forward pass and 80 ps for a backward pass. The ultra-fast nature of photonic interconnects allows for high-speed backpropagation in LiteCON.