
Abstract
We show that counts of squarefree integers up to X in short intervals of size H tend to a Gaussian distribution as long as
1 Introduction
1.1 Statistics of counts of squarefrees
Let
for the number of squarefrees no more than x.
It is well known that
If H is fixed and does not grow with X, at most
For H tending to infinity with X, matters become at once simpler and more difficult; simpler because some of the irregularities in the distribution just described are smoothed out at this scale, but more difficult in that natural conjectures become more difficult to prove.
Let
be the count of squarefrees in the interval
as long as
Keating and Rudnick [25] studied this problem in a function field setting, connecting it with Random Matrix Theory, and suggested based on this that (1.1) will hold for
Because
In [17], Hall[1] studied higher moments of counts of squarefrees in short intervals
where k is a positive integer, proving the upper bound
for any
Our first main result confirms this conjecture.
Theorem 1.1.
For
for every positive integer k, where
Thus if
Note that the main term is the k-th moment of a centered Gaussian random variable with variance
If
Theorem 1.2.
Let
Then, for any
That is, the centered, normalized counts tend in distribution to a Gaussian random variable.
Gaussian limit theorems are known for the sums over short intervals of several important arithmetic functions (for instance divisor functions
A comparison between a short interval containing 125 primes with a short interval containing 125 squarefrees. The relative paucity of gaps and clusters of squarefrees is indicative of the rigidity of their distribution.

A short interval near 100000 containing 125 primes.

A short interval near 100000 containing 125 squarefrees.
Hall in [17] asked also about the order of magnitude of the absolute moments
and as a standard corollary of Theorems 1.1 and 1.2, we obtain an asymptotic formula for these.
Corollary 1.3.
For fixed
Then
Proof.
We give a quick derivation in the language of probability.
By [4, Theorem 25.12] and the subsequent corollary, if
Remark 1.4.
For a given result relating to the behavior of an arithmetic function in short intervals, it is natural to consider the analogous problem in a short arithmetic progression.
For example, in analogy to the quantity
where
and one can define the analogous moments
As noted by Nunes [37, Sections 1.2, 3.2], one may reduce the estimation of
1.2 B-frees
It is natural to write our proofs in the more general setting of B-free numbers. We recall their definition shortly, but first we fix some notation.
For a sequence J of natural numbers, we will write
for the count of elements of J no more than x.
Definition 1.5.
We say that a sequence J is of index
Definition 1.6.
A measurable function L defined, finite, positive, and measurable on
A sequence
For instance, the function
Fix a non-empty subset
We write
so that B-frees have asymptotic density
We write
We introduce an arithmetic function
Observe that
We denote by
1.2.1 Variance and moments
Let
Proposition 1.7.
If the sequence
exists, and moreover, for any
We will describe an explicit formula for
When
Proposition 1.8.
If the sequence
If
Proposition 1.9.
If the sequence
where
This generalizes a result of Avdeeva [2] which requires more robust assumptions about
In fact, we do not need an asymptotic formula for the variance to prove that the moments are Gaussian.
Theorem 1.10.
If
for every positive integer k. Here c is an absolute constant depending only on α.
It is evident that Proposition 1.8 and Theorem 1.10 recover the moment estimate Theorem 1.1 for squarefrees. Moreover, for the same reasons as given for the central limit theorem there, we have the following theorem.
Theorem 1.11.
Let
If the sequence
Remark 1.12.
Combining Theorem 1.10 and Proposition 1.7, we see that, for each k, the moments
In Section 6.2, we give a further application of Theorem 1.10 to estimates for the frequency of long gaps between consecutive B-free numbers, improving results of Plaksin [39] and Matomäki [29].
1.3 Fractional Brownian motion
We have mentioned that the squarefrees and more generally B-frees in a random interval
Nonetheless, a glance at Figure 1 comparing squarefrees to primes – along with consideration of the central limit theorems we have just discussed – reveals that, at a scale of
We give here a short introduction to fractional Brownian motion, as we believe this perspective sheds substantial light on the distribution of B-frees; however, the remainder of the paper is arranged so that a reader only interested in the central limit theorems of the previous sections can avoid this material.
Definition 1.13.
A random process
for all
Using
For a proof that such a stochastic process exists and is uniquely defined by this definition, see e.g. [36].
Classical Brownian motion is a fractional Brownian motion with a Hurst parameter of
Donsker’s theorem is a classical result in probability theory showing that a random walk with independent increments scales to Brownian motion (see [5, Section 8]).
We prove an analogue of Donsker’s theorem for counts of B-frees using the following set up.
We select a random starting point
Set
where
For integer τ, this is a random walk which increases on B-frees and decreases otherwise, and for non-integer τ, the function
Theorem 1.14.
Let
and choose a random integer
where
A graph of

A random walk on squarefrees
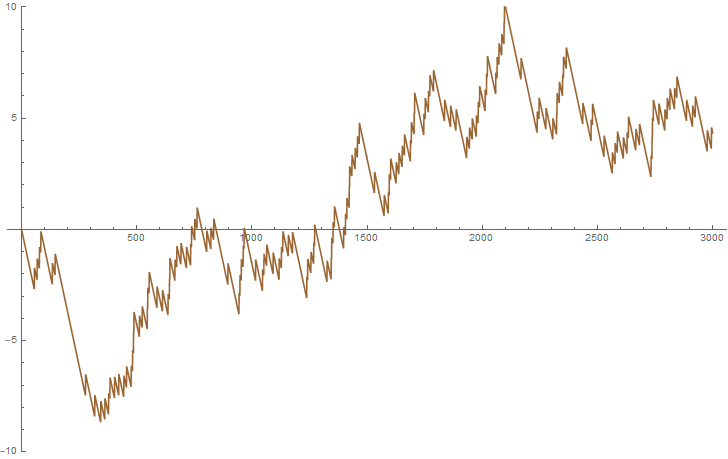
A random walk on primes
A fractional Brownian motion and Brownian motion respectively, randomly generated using Mathematica, to be compared with the previous figure.
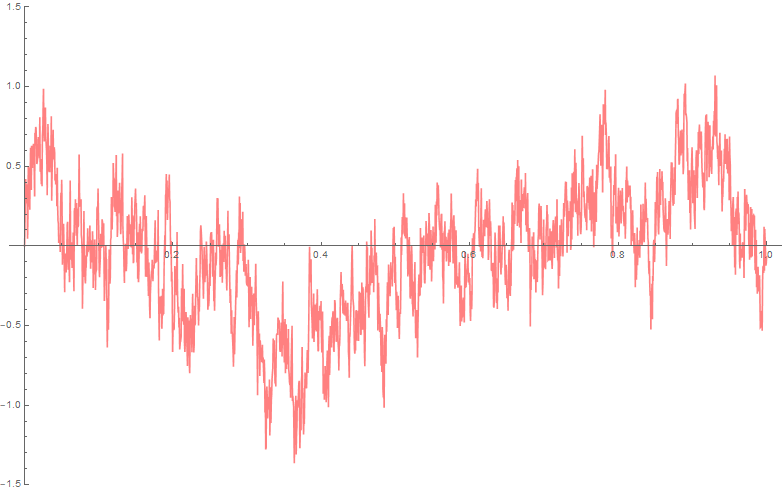
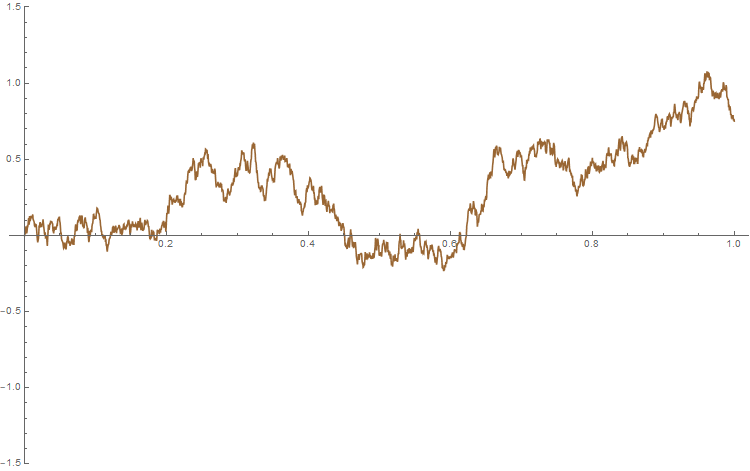
Our proof of this result follows similar ideas as the proof of Theorem 1.10.
Note that
1.4 Notation and conventions
Throughout the rest of this paper, we allow the implicit constants in
1.5 The structure of the proof
There is a heuristic way to understand the Gaussian variation of
The contribution of the first summand is close to the value
is approximated by a linear combination of terms
Heuristically, if X is large and
Nonetheless, we do not quite have independence; instead, roughly speaking, one may use the same Fourier decomposition to relate the k-th moment
where
It can be seen that Gaussian behavior will then follow from most solutions to the above equation being diagonal, meaning there is some pairing
However, this strategy if used by itself is not sufficient to prove a central limit theorem; the Fundamental Lemma was already known to Hall who used it to obtain his upper bound
We obtain an upper bound for the number of off-diagonal solutions to (1.5) by bringing in two ideas in addition to those used by Montgomery–Soundararajan.
The first is due to Nunes, who showed in the recent paper [37] that solutions to (1.5) make a contribution to
In order to prove that counts of B-frees scale to a fractional Brownian motion, it is not sufficient to consider the flat counts
where φ belongs to a class of functions that includes step-functions.
A proof of a central limit theorem for flat counts remains essentially unchanged as long as φ is of bounded variation and compactly supported in
2 An expression for moments
In this section, we prove Proposition 1.7, giving an expression for
In order to eventually have a nice framework to prove Theorem 1.14 on fractional Brownian motion, we generalize the moments we consider.
Suppose
For
We introduce the arithmetic function
Given a bounded function
where, as usual,
Proposition 2.1.
If the sequence
where
Obviously, Proposition 2.1 implies Proposition 1.7 by setting
Our ultimate goal will be to prove generalizations of Theorems 1.1 and 1.10, showing that the moments
2.1 The Fundamental Lemma and other preliminaries
We prove Proposition 2.1 in the next subsection, but first we must introduce a few tools.
For
Note that
and recall
Lemma 2.2.
We have
Proof.
We use (2.2) to obtain
for
and we use the estimate
to conclude.
For
and consider
Lemma 2.3.
For φ supported in a compact subset of
where the implied constant depends on φ only.
Proof.
Suppose φ is supported on an interval
As φ is of bounded variation, the claim follows. ∎
We introduce the arithmetic function
Lemma 2.4.
For a sieving set B, for any
Proof.
Note that
where
The next lemma is a variation on an estimate of Nunes [37, Lemma 2.4], who treated the corresponding result when
Lemma 2.5.
Suppose the sequence
Proof.
We prove the claim by induction on k.
For
which is stronger than what is needed.
We now assume that the bound holds for
We set
Observe that, by comparing exponents in the factorizations,
where we have used Lemma 2.4 in the last step.
For each of the tuples summed over in
where we used the facts that
the number of
Applying the induction hypothesis to bound the last double sum, we obtain
Taking
Finally, throughout this paper, in order to control the inner sums defining
Lemma 2.6 (Montgomery and Vaughan’s Fundamental Lemma).
Let
Later, in Lemmas 4.1 and 5.5, we will cite variants of this result.
2.2 Proof of Proposition 2.1
Proof.
We examine the inner sum defining
where for notational reasons we have written
The function
Thus
From the definition (2.4), each term
for a parameter z to be chosen later.
On the other hand, by (2.5),
where
and in this latter case,
Furthermore, note using Lemma 2.3 and the first part of Lemma 2.2 that
Thus the contribution of terms for which
Thus (2.7) is
We now complete the sum above. Directly applying Lemma 2.6 (and appealing to Lemma 2.3 and the second part of Lemma 2.2), we see that the corresponding sum over tuples
is
Hence, from (2.6), (2.8), (2.9),
where
(Note that the absolute convergence of this sum is implied by the above derivation.)
Setting
It remains to demonstrate
Note also that, as
The sums over
and we see
Remark 2.7.
From (2.10), reindexing
The absolute convergence of this sum is implied by the above argument.
Remark 2.8.
When
When
3 Estimates for variance
3.1 Preliminary results on the index of B,
[
B
]
and
〈
B
〉
In this section, we will estimate the variance
Lemma 3.1.
For a sieving set B, the sequence
Proof.
Suppose
On the other hand,
Introducing a parameter
so
In the converse direction, if
To prove an upper bound for
Other authors have proved results in this area based on assumptions regarding the index of the set B (for instance [15]). Though we will not require it in what follows, for completeness’ sake, we note the following implication.
Proposition 3.2.
For a sieving set B, if B has index α, then
Proof.
As
We will first show for any
For notational reasons, let
This gives (3.2) for
Now note
As ε is arbitrary, this implies
Using (3.1) as before, this implies
It seems likely that the converse to Proposition 3.2 is false, but we do not pursue this here.
3.2 Variance for
〈
B
〉
with index α
We now show that the exponent of the variance is determined by the index of
Lemma 3.3.
Suppose φ is of bounded variation, supported on a compact subset of
Proof.
We have
For an upper bound, we apply Lemma 2.3 and the second part of Lemma 2.2 to see that
As
Suppose
We now split the proof of the lower bound into two cases, depending on whether or not
Case 1:
Using the convolution formula
Moreover, if
where in the last step we used the fact that φ is non-vanishing on some open interval.
Since
Since
uniformly in m, we may use positivity to restrict to
where in the second to last step we used the fact that
Case 2:
Let
if K is large enough.
Since
since, again by Lemma 3.1,
Obviously, this implies Proposition 1.8 where
3.3 Variance for regularly varying
〈
B
〉
If
We begin with a useful expression for
Lemma 3.4.
We have
Proof.
We begin with the expression in Remark 2.7 for
we see that (2.10) gives
But, in this sum,
we obtain
Write
which in turn simplifies to (3.5). ∎
We will use the following result of Pólya to estimate the above sum.
Proposition 3.5 (Pólya).
If
for some
Proof.
This can be found in Pólya and Szegő’s book [41, Problem No. 159 in Part II, Chapter 4 of Volume I]; see also Pólya’s paper [40]. ∎
Proof of Proposition 1.9.
We define
For both
where
where the coefficients
Note the Euler product defining
with the implications
which will be important later.
By using the Dirichlet convolution implicit in (3.6), we can write
for
But, from the bound
The last estimate follows because if
Therefore, one may check that Pólya’s proposition may be applied and
where rearrangement of sums and integrals is justified in the second line of (3.8) by absolute convergence.
By a change of variables
since the sums over λ and c can then be simplified as
which recovers the constant (1.2) claimed in the proposition. ∎
Remark 3.6.
We will not require it, but with a bit more work, one can show that if
where
4 Diagonal terms
In this section, we show how the approximation of
We say that the tuple
We adopt the abbreviations
Our approach in this section largely follows Montgomery and Soundararajan’s proof of [33, Theorem 1]. We will use the following variant of the Fundamental Lemma; the result is a generalization of [33, Lemma 2], which corresponds to B being the set of primes. The original proof[3] works as is.
Lemma 4.1 (Montgomery and Soundararajan).
Let
for all
The next lemma separates repeated or non-paired r from what we will show is the main contribution to
Lemma 4.2.
Let
If k is even, we have
where
Proof.
We first consider odd k.
There are no vectors
We now consider even k. By the triangle inequality,
There are
This finishes the proof. ∎
We now show that paired and non-repeated terms above can be reduced to powers of the variance.
Proposition 4.3.
Let
Proof.
Let j be the number of values of i for which
where
Recall
Montgomery and Soundararajan [33, equation (34)] showed that
for B being the set of primes and
Due to (4.2), we may apply Lemma 4.1 with
Additionally, as
and hence, for any value of
We take
as
Taken together, Lemma 4.2 and Proposition 4.3 show that paired and non-repeated terms in
5 Off-diagonal terms
In this section, we show that the repeated or non-paired terms contribute negligibly to
5.1 Preliminary estimates: Nunes’s reduction in the range of
𝐫
Following Nunes [37], in this subsection, we will show that, in the sum defining
The following bound follows directly from the Fundamental Lemma. (Very similar estimates have been used in [34, p. 317, equation (9)], [17, equation (33)], and [37, Lemma 2.3].)
Lemma 5.1 (Montgomery and Vaughan).
Given integers
The following elementary estimate was proved by Nunes [37, Lemma 2.3] in the special case
Lemma 5.2 (Nunes).
Given
Proof.
Ignore the restriction
The Fundamental Lemma only sees the
We now use Nunes’s bound (5.2) to deal with
Lemma 5.3.
Let
Proof.
Appealing to (5.2), the contribution of
The claimed bound then follows from Lemma 2.4 since
We now use the Fundamental Lemma to show that, among those
Lemma 5.4.
Let
Proof.
If
so that our sum is at most
The claimed bound again follows from Lemma 2.4, as
5.2 Using the Fundamental Lemma
To estimate off-diagonal contributions, we use the following variant of the Fundamental Lemma.
It generalizes [34, Lemma 7] of Montgomery and Vaughan, which corresponds to B being the set of primes and
Lemma 5.5 (Montgomery and Vaughan).
Let
where
if
We use this to produce a first bound on repeated or non-paired
Proposition 5.6.
Let
where
Proof.
Let
If
(The parameter T is taken to be
In our case,
so the total contribution of the
which is absorbed in the error term since the series over r is
Suppose that
We claim that there is at least one pair
Hence, necessarily,
which is also absorbed in the error term.
We now treat the contribution of
Assuming always that Lemma 5.5 is applied with the first two elements of
by Cauchy–Schwarz, where
and
To study the first sum, we write r as
Because
so that
Plugging the definition of
Plugging this bound in (5.3), we end up with
In order to get a good upper bound on
Lemma 5.7.
Let χ be a Dirichlet character modulo q, and suppose
Proof.
By the definition of
The bound for principal characters is evident, so we now consider non-principal ones.
The sum over smaller
with the trivial bound
where
In what follows, we use the notation
Proposition 5.8.
Suppose
for
Proof.
Expanding the square, we have
The two congruences in the innermost sum imply
and we may replace the inner double sum over
We can detect (5.4) using orthogonality of characters, obtaining
By Lemma 5.7, the contribution of the principal character
which gives the first term in the required bound. We now consider the non-principal characters. Applying the pointwise bound for the sum of F twisted by χ as given in Lemma 5.7, we see that they contribute
This gives the second contribution to the bound, and we are done. ∎
Proposition 5.9.
Let N be in the range
Proof.
We dyadically decompose the inner sum over a in the definition of
for any positive integer U, as we now explain.
First, we may replace
as, in general, if
Putting this in the definition of
Now, by orthogonality, we have
Thus, using this in the conclusion of Proposition 5.8 with
Inserting this estimate back into our upper bound for
where
where the variable
where τ is the usual divisor function.
To treat
It remains to treat
Hence, we further bound
Consider first
The inner sum in
Bounding the minimum trivially by
Finally, we treat
Using the bound
It follows then that
as claimed. ∎
Remark 5.10.
It is worth highlighting the main novelty of our argument over the work in [34, Lemma 8], specifically the treatment of the expressions
For simplicity, assume that
uniformly over both reduced residues
In contrast, when B is a sparse set of index
held uniformly in
6 The central limit theorem for general weights φ
6.1 A proof of the central limit theorem
We assemble the estimates of the previous sections to show that
Theorem 6.1.
Suppose φ is of bounded variation and supported in a compact subset of
for every positive integer k. Here c is an absolute constant depending only on α.
Proof.
By Lemma 4.2 and Proposition 4.3, we have
Let
We apply Proposition 5.9 to bound
We now choose
Obviously, this implies Theorem 1.10 and thus the central limit theorem, Theorem 1.11, for flat counts in short intervals.
In fact, more generally, combining Theorem 6.1 with Proposition 2.1, we see that, as long as
By the moment method, this implies that weighted counts also satisfy a central limit theorem.
Theorem 6.2.
Let
and choose a random integer
tends to the standard normal distribution
6.2 An application to long gaps
Estimate (6.1) allows us to obtain strong information about the frequency of long gaps between consecutive B-free integers.
Given
Thus
Improving on work of Plaksin [39], Matomäki [29] used a sieve-theoretic method to show that, for any
(with no upper bound constraint on the range of H if B consists only of primes). As a consequence of our k-th-moment bounds, we can prove the following.
Corollary 6.3.
If
Since we have
Proof.
If
Combined with Proposition 1.8 and Theorem 1.10, this implies that if
We deduce immediately that
7 Fractional Brownian motion
7.1 Convergence in
C
[
0
,
1
]
We now prove Theorem 1.14, showing that a random walk on the B-frees tends to a fractional Brownian motion.
There is ready-made machinery to demonstrate that a sequence of random elements of
Theorem 7.1.
If
(convergence of finite-dimensional distributions) for any
(tightness) the sequence of random elements
Proof.
This is a direct consequence of [23, Lemma 16.2 and Theorem 16.3]. ∎
We also have the following device for proving tightness.
Theorem 7.2 (Kolmogorov–Chentsov).
Using the notation of the previous theorem, if
for all
Proof.
This is a special case of [23, Corollary 16.9]. ∎
7.2 The B-free random walk
We apply these results to the random functions
Lemma 7.3.
If we have a sequence of natural numbers J is regularly varying with index
for all
Proof.
Obviously, the result is true if
If
(The reader should check that this may be done.)
It then follows from Karamata’s representation of slowly varying functions (see [26, consequence (2.5) of Theorem 2.2, p. 180]) that if
for tH and H sufficiently large depending on ε. By compactness, then
for
Proof of Theorem 1.14.
Let
Let us treat (i) first.
Note, for each
by Proposition 1.9.
As
Thus we will have the finite-dimensional distributions of
tends to a real-valued Gaussian distribution. But
and so the Gaussian behavior follows from Theorem 6.2.
We now demonstrate (ii).
Note that, for any positive integer ν and
as long as X (and thus H) is sufficiently large so that
Funding source: H2020 European Research Council
Award Identifier / Grant number: 851318
Funding source: National Science Foundation
Award Identifier / Grant number: 1854398
Funding statement: Ofir Gorodetsky is supported by funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 851318). Brad Rodgers received partial support from an NSERC grant and US NSF FRG grant 1854398.
Acknowledgements
Most of this work was completed while A. M. was a CRM-ISM postdoctoral fellow at the Centre de Recherches Mathématiques. He would like to thank the CRM for its financial support. We thank Francesco Cellarosi for useful discussions, as well as the anonymous referee for carefully reading the paper and providing a number helpful comments leading to improvements in its exposition.
References
[1]
R. Arratia,
The motion of a tagged particle in the simple symmetric exclusion system on
[2] M. Avdeeva, Variance of B-free integers in short intervals, preprint (2015), https://arxiv.org/abs/1512.00149. Search in Google Scholar
[3]
M. Avdeeva, F. Cellarosi and Y. G. Sinai,
Ergodic and statistical properties of
[4] P. Billingsley, Probability and measure, 3rd ed., Wiley Ser. Probab. Math. Stat., John Wiley & Sons, New York 1995. Search in Google Scholar
[5] P. Billingsley, Convergence of probability measures, 2nd ed., Wiley Ser. Probab. Stat., John Wiley & Sons, New York 1999. 10.1002/9780470316962Search in Google Scholar
[6] J. Brüdern, Binary additive problems and the circle method, multiplicative sequences and convergent sieves, Analytic number theory, Cambridge University, Cambridge (2009), 91–132. Search in Google Scholar
[7] F. Cellarosi and Y. G. Sinai, Ergodic properties of square-free numbers, J. Eur. Math. Soc. (JEMS) 15 (2013), no. 4, 1343–1374. 10.4171/JEMS/394Search in Google Scholar
[8]
A. Dymek,
Automorphisms of Toeplitz
[9]
A. Dymek, S. A. Kasjan, J. Kułaga Przymus and M. Lemańczyk,
[10]
E. H. El Abdalaoui, M. Lemańczyk and T. de la Rue,
A dynamical point of view on the set of
[11] N. Enriquez, A simple construction of the fractional Brownian motion, Stochastic Process. Appl. 109 (2004), no. 2, 203–223. 10.1016/j.spa.2003.10.008Search in Google Scholar
[12] P. Erdős, On the difference of consecutive terms of sequences defined by divisibility properties, Acta Arith. 12 (1966/1967), 175–182. 10.4064/aa-12-2-175-182Search in Google Scholar
[13] O. Gorodetsky, K. Matomäki, M. Radziwiłł and B. Rodgers, On the variance of squarefree integers in short intervals and arithmetic progressions, Geom. Funct. Anal. 31 (2021), no. 1, 111–149. 10.1007/s00039-021-00557-5Search in Google Scholar
[14] I. S. Gradshteyn and I. M. Ryzhik, Table of integrals, series, and products, Academic Press, Boston 2014. Search in Google Scholar
[15] G. Grimmett, Large deviations in the random sieve, Math. Proc. Cambridge Philos. Soc. 121 (1997), no. 3, 519–530. 10.1017/S0305004196001594Search in Google Scholar
[16] R. R. Hall, Squarefree numbers on short intervals, Mathematika 29 (1982), no. 1, 7–17. 10.1112/S0025579300012110Search in Google Scholar
[17] R. R. Hall, The distribution of squarefree numbers, J. reine angew. Math. 394 (1989), 107–117. 10.1515/crll.1989.394.107Search in Google Scholar
[18] A. Hammond and S. Sheffield, Power law Pólya’s urn and fractional Brownian motion, Probab. Theory Related Fields 157 (2013), no. 3–4, 691–719. 10.1007/s00440-012-0468-6Search in Google Scholar
[19] M. Hausman and H. N. Shapiro, On the mean square distribution of primitive roots of unity, Comm. Pure Appl. Math. 26 (1973), 539–547. 10.1002/cpa.3160260407Search in Google Scholar
[20] C. P. Hughes and Z. Rudnick, On the distribution of lattice points in thin annuli, Int. Math. Res. Not. IMRN 2004 (2004), no. 13, 637–658. 10.1155/S1073792804131681Search in Google Scholar
[21] H. Iwaniec and E. Kowalski, Analytic number theory, Amer. Math. Soc. Colloq. Publ. 53, American Mathematical Society, Providence 2004. 10.1090/coll/053Search in Google Scholar
[22] M. Jancevskis, Convergent sieve sequences in arithmetic progressions, J. Number Theory 129 (2009), no. 6, 1595–1607. 10.1016/j.jnt.2008.09.009Search in Google Scholar
[23] O. Kallenberg, Foundations of modern probability, 2nd ed., Probab. Appl. (New York), Springer, New York 2002. 10.1007/978-1-4757-4015-8Search in Google Scholar
[24]
S. A. Kasjan, G. Keller and M. Lemańczyk,
Dynamics of
[25] J. Keating and Z. Rudnick, Squarefree polynomials and Möbius values in short intervals and arithmetic progressions, Algebra Number Theory 10 (2016), no. 2, 375–420. 10.2140/ant.2016.10.375Search in Google Scholar
[26] J. Korevaar, Tauberian theory, Grundlehren Math. Wiss. 329, Springer, Berlin 2004. 10.1007/978-3-662-10225-1Search in Google Scholar
[27]
J. Kułaga Przymus, M. Lemańczyk and B. Weiss,
On invariant measures for
[28] S. Lester and N. Yesha, On the distribution of the divisor function and Hecke eigenvalues, Israel J. Math. 212 (2016), no. 1, 443–472. 10.1007/s11856-016-1290-0Search in Google Scholar
[29]
K. Matomäki,
On the distribution of
[30]
M. K. Mentzen,
Automorphisms of subshifts defined by
[31] L. Mirsky, Note on an asymptotic formula connected with r-free integers, Quart. J. Math. Oxford Ser. 18 (1947), 178–182. 10.1093/qmath/os-18.1.178Search in Google Scholar
[32] L. Mirsky, Arithmetical pattern problems relating to divisibility by rth powers, Proc. Lond. Math. Soc. (2) 50 (1949), 497–508. 10.1112/plms/s2-50.7.497Search in Google Scholar
[33] H. L. Montgomery and K. Soundararajan, Primes in short intervals, Comm. Math. Phys. 252 (2004), no. 1–3, 589–617. 10.1007/s00220-004-1222-4Search in Google Scholar
[34] H. L. Montgomery and R. C. Vaughan, On the distribution of reduced residues, Ann. of Math. (2) 123 (1986), no. 2, 311–333. 10.2307/1971274Search in Google Scholar
[35] H. L. Montgomery and R. C. Vaughan, Multiplicative number theory. I. Classical theory, Cambridge Stud. Adv. Math. 97, Cambridge University, Cambridge 2007. 10.1017/CBO9780511618314Search in Google Scholar
[36] I. Nourdin, Selected aspects of fractional Brownian motion, Bocconi & Springer Ser. 4, Springer, Milan 2012. 10.1007/978-88-470-2823-4Search in Google Scholar
[37] R. M. Nunes, Moments of the distribution of k-free numbers in short intervals and arithmetic progressions, Bull. Lond. Math. Soc. 54 (2022), no. 4, 1282–1298. 10.1112/blms.12628Search in Google Scholar
[38] P. Parczewski, A fractional Donsker theorem, Stoch. Anal. Appl. 32 (2014), no. 2, 328–347. 10.1080/07362994.2013.866521Search in Google Scholar
[39]
V. A. Plaksin,
Distribution of
[40] G. Pólya, Bemerkungen über unendliche Folgen und ganze Funktionen, Math. Ann. 88 (1923), no. 3–4, 169–183. 10.1007/BF01579177Search in Google Scholar
[41] G. Pólya and G. Szegő, Problems and theorems in analysis. I, Class. Math., Springer, Berlin 1998. Search in Google Scholar
[42] K. F. Roth, On the gaps between squarefree numbers, J. Lond. Math. Soc. 26 (1951), 263–268. 10.1112/jlms/s1-26.4.263Search in Google Scholar
[43] P. Sarnak, Three lectures on the Möbius function, randomness and dynamics (Lecture 1), 2011, http://publications.ias.edu/sites/default/files/MobiusFunctionsLectures(2).pdf. Search in Google Scholar
[44] T. Sottinen, Fractional Brownian motion, random walks and binary market models, Finance Stoch. 5 (2001), no. 3, 343–355. 10.1007/PL00013536Search in Google Scholar
© 2023 Walter de Gruyter GmbH, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.