
Abstract
Code-based cryptography is one of the main areas of interest for NIST’s Post-Quantum Cryptography Standardization call. In this paper, we introduce DAGS, a Key Encapsulation Mechanism (KEM) based on quasi-dyadic generalized Srivastava codes. The scheme is proved to be IND-CCA secure in both random oracle model and quantum random oracle model. We believe that DAGS will offer competitive performance, especially when compared with other existing code-based schemes, and represent a valid candidate for post-quantum standardization.
1 Introduction
The availability of large-scale quantum computers is getting ever closer to reality, and with it, all of the public-key cryptosystems currently in use, which rely on number theory problems (e.g., factorization) and discrete logarithm problems will become obsolete [41]. Therefore, it is of extreme importance to be able to offer a credible alternative that can resist attackers equipped with quantum technology. In this regard, NIST’s call for proposals for post-quantum standardization is a further reassurance about the need for solid post-quantum proposals. Furthermore, considering the desired life of the encrypted data, and the lengthy timeframe for such a complex standardization process, it is clear how convincing research work in post-quantum cryptography is not only necessary, but also urgent.
Code-based cryptography is one of the main candidates for this task. The area is generally based on the syndrome decoding problem [10], which has shown no vulnerabilities to quantum attacks over the years. Since McEliece’s seminal work [30] in 1978, many variants and modifications have been proposed, trying to balance security and efficiency and in particular dealing with inherent flaws such as the large size of the public keys. In fact, while the original McEliece’s cryptosystem (based on binary Goppa codes) is still formally unbroken, it features a key of several tenths of kilobytes, which has effectively prevented its use in many applications.
There are currently two main trends to deal with this issue, and they both involve structured matrices: the first, is based on “traditional” algebraic codes, and in particular alternant codes such as Goppa or generalized Srivastava codes; the second suggests to use sparse matrices as in LDPC/MDPC codes [3, 32]. This work builds on the former approach, initiated in 2009 by Berger et al. [9], who proposed Quasi-Cyclic (QC) codes, and Misoczki and Barreto [31], suggesting Quasi-Dyadic (QD) codes instead (later generalized to Quasi-Monoidic (QM) codes [8]). Both proposals feature very compact public keys due to the introduction of the extra algebraic structure, but unfortunately this also leads to a vulnerability. Indeed, Faugère et al. [22] devised a clever attack (known simply as FOPT) which exploits the algebraic structure to build a system of equations, which can successively be solved using Gröbner bases techniques. As a result, the QC proposal is heavily compromised, while the QD/QM approach needs to be treated with caution. In fact, for a proper choice of parameters, it is still possible to design secure schemes, using for instance binary Goppa codes, or Generalized Srivastava (GS) codes as suggested by Persichetti in [36].

Our contribution.
In this paper, we present DAGS[1], a key encapsulation mechanism that follows the QD approach using GS codes. KEMs are the primitive favored by NIST for key exchange schemes, and can be used to build encryption schemes, for example using the hybrid encryption paradigm introduced by Cramer and Shoup [18]. To the best of our knowledge, this is the first code-based KEM that uses quasi-dyadic codes. Another NIST submission, named BIG QUAKE [44], proposes a scheme based on quasi-cyclic codes.
Our KEM achieves IND-CCA security, following the recent framework by Kiltz et al. [27], and features compact public keys and efficient encapsulation and decapsulation algorithms. We modulate our parameters to achieve an efficient scheme, while at the same time keeping out of range of the FOPT attack. We provide an initial performance analysis of our scheme as well as access to our reference code; the team is currently working at several additional, optimized implementations, using C++, assembly language, and hardware (FPGA).
Related work.
We show that our proposal compares well with other post-quantum KEMs. These include the classic McEliece approach [47], as well as more recent proposals such as BIKE [45] and the aforementioned BIG QUAKE.
The “Classic McEliece” project is an evolution of the well-known McBits [12] (based on the work of Persichetti [37]), and benefits from a well-understood security assessment but suffers from the usual public key size issue. BIKE, a protocol based on QC-MDPC codes, is the result of a merge between two independently published works with similar background, namely CAKE [7] and Ouroboros [19]. The scheme possesses some very nice features like compact keys and an easy implementation approach, but has currently some potential drawbacks. In fact, the QC-MDPC encryption scheme on which it is based is susceptible to a reaction attack by Guo, Johansson and Stankovski (GJS) [25], and thus the protocol is forced to employ ephemeral keys. Moreover, due to its non-trivial Decoding Failure Rate (DFR), achieving IND-CCA security becomes very hard, so that the BIKE protocol only claims to be IND-CPA secure.
Finally, BIG QUAKE continues the line of work of [9] and proposes to use quasi-cyclic Goppa codes. Due to the particular nature of the FOPT attack and its successors [21], it seems harder to provide security with this approach, and the protocol chooses very large parameters in order to do so. We will discuss attack and parameters in Section 5.
More distantly related are lattice-based schemes like NewHope [2] and Frodo [14], based respectively on LWE and its ring variant. While these schemes are not necessarily a direct comparison term, it is nice to observe that DAGS offers comparable performance.
Organization of the paper.
The paper is organized as follows. We start by giving some preliminary notions in Section 2. We describe the DAGS protocol in Section 3, and we discuss its provable security in Section 4, showing that DAGS is IND-CCA secure in the random oracle model as well as the quantum random oracle model. Section 5 features a discussion about practical security and known attacks, which include general decoding attacks (information set decoding and the like) as well as algebraic attacks; we then present parameters for the scheme. Performance details are given in Section 6. Finally, we conclude in Section 7.
2 Preliminaries
2.1 Notation
We will use the following conventions throughout the rest of the paper:
a constant
a vector
a matrix
an algorithm or (hash) function
a set
the concatenation of vectors
the diagonal matrix formed by the vector
the
choosing a random element from a set or distribution
the length of a shared symmetric key
2.2 Linear codes
We briefly recall some fundamental notions from coding theory. The Hamming weight of a vector
Definition 2.1.
An
A linear code can be represented by means of a matrix
2.3 Structured matrices and GS codes
Definition 2.2.
Given a ring
If n is a power of 2, then every
where each block is a
Definition 2.3.
For
where each block is given by
The parameters for such a code are the length
3 Construction
The core idea of DAGS is to use GS codes which are defined by matrices in quasi-dyadic form. In particular, the public key of the scheme is the generator matrix of such a code, which, being quasi-dyadic, can be described using just the signature of each block. This allows to obtain a very compact public key. Now, it can be easily proved that every GS code with
Misoczki and Barreto showed in [31, Theorem 2] that the intersection of the set of Cauchy matrices with the set of dyadic matrices is not empty if the code is defined over a field of characteristic 2, and the dyadic signature
On the other hand, it is evident from Definition 2.3 that if we permute the rows of H to constitute
we obtain an equivalent parity-check matrix for a GS code, given by
The key generation process exploits first of all the fundamental equation to build a Cauchy matrix. The matrix is then successively powered (element by element) forming several blocks which are superimposed and then multiplied by a random diagonal matrix. Thanks to the observation above, we have now formed the matrix
3.1 Algorithms
We are now ready to introduce the three algorithms that form DAGS. System parameters are the code length n and dimension k, the values s and t which define a GS code, the cardinality of the base field q and the degree of the field extension m. In addition, we have
DAGS is a key encapsulation mechanism and as such it is composed of three algorithms – Key Generation, Encapsulation and Decapsulation – which will present below in the respective order.
Algorithm 1 (Key Generation).
Build the Cauchy support:
Choose a random[3] offset
Compute
Compute
Set
Form the Cauchy matrix
Build
Superimpose the blocks
Generate the vector
Set
Form
Project H onto
Write
The public key is the generator matrix
The private key is the pair
The encapsulation and decapsulation algorithms follow the paradigm of [27] to obtain an IND-CCA secure KEM from a PKE, and as such, they make use of two functions
Algorithm 2 (Encapsulation).
Choose
Compute
Parse
Generate the error vector
Compute
Compute
Output the ciphertext
The decapsulation algorithm consists mainly of decoding the noisy codeword received as part of the ciphertext. This is done using the alternant decoding algorithm described in [29, Chapter 12, Section 9] and requires the parity-check matrix to be in alternant form.
Algorithm 3 (Decapsulation).
Get the parity-check matrix
Use
Output
Recover
Compute
Parse
Generate the error vector
If
Else, compute
The decapsulated key is
DAGS is built upon the McEliece cryptosystem, with a notable exception. In fact, we incorporate the “randomized” version of McEliece by Nojima et al. [35] into our scheme. This is extremely beneficial for two distinct aspects: first of all, it allows us to use a much shorter vector
The selection of the parameters for the scheme will be discussed in Section 5.4.
4 KEM security
In this section, we discuss some aspects of provable security, and in particular we show that DAGS satisfies the notion of IND-CCA security for KEMs, as defined below.
Definition 4.1.
The adaptive chosen-ciphertext attack game for a KEM proceeds as follows:
Query a key generation oracle to obtain a public key pk.
Make a sequence of calls to a decryption oracle, submitting any string
Query an encryption oracle. The oracle runs
Keep performing decryption queries. If the submitted ciphertext is
Output
The adversary succeeds if
We say that a KEM is secure if the advantage
Before discussing the IND-CCA security of DAGS, we show that the underlying PKE (i.e. randomized McEliece, see [35]) satisfies a simple property. This will allow us to get better security bounds in our reduction.
Definition 4.2.
Consider a probabilistic PKE with randomness set
for a certain
The definition above is presented as in [27], but note that in fact this corresponds to the notion of γ-uniformity given by Fujisaki and Okamoto in [24], except for a change of constants. In other words, a scheme is γ-spread if it is
It was proved in [16] that a simple variant of the (classic) McEliece PKE is γ-uniform for
Lemma 4.3.
Randomized McEliece is γ-uniform for
Proof.
Let
We are now ready to present the security results.
Theorem 4.4.
Let
Proof.
The thesis is a consequence of the results presented in [27, Section 3.3]. In fact, our scheme follows the
The value d included in the KEM ciphertext does not contribute to the security result above, but it is a crucial factor to provide security in the Quantum Random Oracle Model (QROM). We present this in the next theorem.
Theorem 4.5.
Let
Proof.
The thesis is a consequence of the results presented in Section 4.4 of [27]. In fact, our scheme follows the
5 Practical security and parameters
Having proved that DAGS satisfies the notion of IND-CCA security for KEMs, we now move onto a treatment of practical security issues. In particular, we will briefly present the hard problem on which DAGS is based, and then discuss the main attacks on the scheme and related security concerns.
5.1 Hard problems from coding theory
Most of the code-based cryptographic constructions are based on the hardness of the following problem, known as the (q-ary) Syndrome Decoding Problem (SDP).
Problem 5.1.
Given an
The corresponding decision problem was proved to be NP-complete in 1978 [10], but only for binary codes. In 1994, Barg proved that this result holds for codes over all finite fields ([5], in Russian, and [6, Theorem 4.1]).
In addition, many schemes (including the original McEliece proposal) require the following computational assumption.
Assumption 1.
The public matrix output by the key generation algorithm is computationally indistinguishable from a uniformly chosen matrix of the same size.
The assumption above is historically believed to be true, except for very particular cases. For instance, there exists a distinguisher (Faugère et al. [20]) for cryptographic protocols that make use of high-rate Goppa codes (like the CFS signature scheme [17]). Moreover, it is worth mentioning that the “classical” methods for obtaining an indistinguishable public matrix, such as the use of scrambling matrices S and P, are rather outdated and unpractical and can introduce vulnerabilities to the scheme as per the work of Strenzke et al. [42, 43]. Thus, traditionally, the safest method (Biswas and Sendrier, [13]) to obtain the public matrix is simply to compute the systematic form of the private matrix.
5.2 Decoding attacks
The main approach for solving SDP is the technique known as Information Set Decoding (ISD), first introduced by Prange [39], which targets directly the error vector and aims at decoding without knowing the underlying structure of the code (i.e. treating the code as truly random). Among several variants and generalizations, Peters showed [38] that it is possible to apply Prange’s approach to generic q-ary codes. Other approaches such as statistical decoding [1, 33] are usually considered less efficient. Thus, when choosing parameters, we will focus mainly on defeating attacks of the ISD family.
Hamdaoui and Sendrier in [26] provide non-asymptotic complexity estimates for ISD in the binary case. For codes over
Quantum speedup.
Bernstein in [11] shows that Grover’s algorithm applies to ISD-like algorithms, effectively halving the asymptotic exponent in the complexity estimates. Later, it was proved in [28] that several variants of ISD have the potential to achieve a better exponent, however the improvement was disappointingly away from the factor of 2 that could be expected. For this reason, we simply treat the best quantum attack on our scheme to be “traditional” ISD (Prange) combined with Grover search.
5.3 Algebraic attacks
While, as we discussed above, recovering a private matrix from a public one is in general a very difficult problem, the presence of special algebraic properties and additional structure in the code can have a considerable effect in lowering this difficulty. It turns out that, in the case of alternant codes for instance, there are indeed efficient methods that exploit this issue.
Solving systems of equations.
A very effective structural attack was introduced by Faugère et al. in [22]. The attack (for convenience referred to as FOPT) relies on the simple property
The attack was originally aimed at two variants of McEliece, introduced respectively in [9] and [31]. The first variant, using quasi-cyclic codes, was easily broken in all proposed parameters and falls out of the scope of this paper. The second variant, instead, only considered quasi-dyadic Goppa codes. In this case too, most of the parameters proposed have been broken, except for the binary case (i.e. base field
Attack complexity.
Following up on their own work, the authors in [23] produced a paper which analyzes the attack in detail, with the aim of evaluating its complexity at least somewhat rigorously. At the core of the attack, there is an affine bilinear system, which is derived from the initial system of equations by applying various algebraic relations due to the quasi-dyadic structure. This bilinear system has
Details of FOPT applied to quasi-dyadic Goppa codes [23].
| q | m | n | k | Time (s) / | Operations | ||||
| 2 | 16 | 3584 | 1536 | 56 | 60 | 15 | N/A | ||
| 8 | 3584 | 1536 | 56 | 60 | 7 | 1776.3 / | |||
| 4 | 2048 | 1024 | 32 | 36 | 3 | 0000.5 / | |||
| 2 | 1280 | 768 | 20 | 24 | 1 | 0000.03 / | |||
| 2 | 640 | 512 | 10 | 14 | 1 | 0000.03 / | |||
| 2 | 768 | 512 | 6 | 11 | 1 | 0000.02 / | |||
| 2 | 1024 | 512 | 4 | 10 | 1 | 0000.11 / | |||
| 2 | 512 | 256 | 4 | 9 | 1 | 0000.06 / | |||
| 2 | 640 | 384 | 5 | 10 | 1 | 0000.02 / | |||
| 2 | 768 | 512 | 6 | 11 | 1 | 0000.01 / | |||
| 2 | 1280 | 768 | 5 | 11 | 1 | 0000.05 / | |||
| 2 | 1536 | 1024 | 6 | 12 | 1 | 0000.06 / | |||
| 4 | 4096 | 3584 | 32 | 37 | 3 | 0007.1 / | |||
| 2 | 3072 | 2048 | 6 | 13 | 1 | 0000.15 / | |||
It is possible to observe several facts. In every set of parameters, for instance,
The first three groups of parameters are taken from the preliminary (unpublished) version of [31, Tables 2, 3 and 5, respectively], while the last group consists of some ad hoc parameters generated by the FOPT authors. It stands out the absence of parameters from [31, Table 4]. In fact, all of these parameters used
Towards the end of [23], the authors present a bound on the theoretical complexity of computing a Gröbner base of the affine bilinear system which is at the core of the attack. They then evaluate this bound and compare it with the number of operations required in practice (last column of Table 1). The bound is given by
where D is the degree of regularity of the system, i.e.
and
As it turns out this bound is quite loose, being sometimes above and sometimes below the experimental results, depending on which set of parameters is considered. As such, it is to be read as a grossly approximate indication of the expected complexity of a parameter set, and it only allows to have a rough idea of the security provided for each set. Nevertheless, since are able to compute the bound for all DAGS proposed parameters, we will keep this number in mind when proposing parameters (Section 5.4), to make sure our choices are at least not obviously insecure.
As a bottom-line, it is clear that the complexity of the attack scales somewhat proportionally to the value
Since GS codes are also alternant codes, the attack can be applied to our proposal as well. There is, however, one very important difference to keep in mind. In fact, it is shown in [36] that, thanks to the particular structure of GS codes, the dimension of the solution space is defined by
Folded codes.
Recently, an extension of the FOPT attack appeared in [21]. In this work, the authors introduce a new technique called “folding”, and show that it is possible to reduce the complexity of the FOPT attack to the complexity of attacking a smaller code (the “folded” code). This is a consequence of the strong properties of the automorphism group that is present in the alternant codes used. The attack turns out to be very efficient against Goppa codes, as it is possible to recover a folded code which is also a Goppa code. As a consequence, it is possible to tweak the attack to solve a different, augmented system of equations (named
The paper concentrates on attacking several parameters that were proposed for signature schemes and encryption schemes in various follow-up works that build and expand on [9] and [31]. The latter includes, among others, some of the parameters presented in Table 1. It turns out that codes designed to work for signature schemes are very easy to attack (due to their particular nature); however, the situation for encryption is more complex. The authors are able to obtain a speedup in the attack times for previously investigated parameters, but some of the parameters could still not be solved in practice. We report the results in Table 2, where we indicate the type of system chosen to be solved, and we keep some of the previously-shown parameters for ease of comparison.
Details of folding attack applied to quasi-dyadic Goppa codes [23].
| q | m | n | k | System | New attack | FOPT | ||
| 4 | 2048 | 1024 | 32 | 00.01 s | 0000.5 s | |||
| 4 | 4096 | 3584 | 32 | 00.01 s | 0007.1 s | |||
| 8 | 3584 | 1536 | 56 | 00.04 s | 1776.3 s | |||
| 2 | 16 | 4864 | 4352 | 152 | 18 s | N/A | ||
| 2 | 12 | 3200 | 1664 | 25 | N/A | |||
| 2 | 14 | 5376 | 3584 | 42 | N/A | |||
| 2 | 15 | 11264 | 3584 | 22 | N/A | |||
| 2 | 16 | 6912 | 2816 | 27 | N/A | |||
| 2 | 16 | 8192 | 4096 | 32 | N/A |
The authors do not report timings for codes that were already broken with FOPT in negligible time (which is the case for all the parameter sets where
This table confirms our intuition that high values of m result in a high number of operations, and that complexity increases somewhat proportionally to this value. Note that the last five sets of parameters were not broken in practice and the estimated complexity is always quite high. It is not clear what the authors mean by
The fourth set of parameters seem to contradict our intuition, since it was broken in practice with relative ease even though
The authors did not present any explicit result against GS codes and, in particular, it is not known whether a folded GS code is still a GS code. Thus, the attack in this case is limited to solving the generic system
Norm-trace codes.
An attack based on norm-trace codes has been recently introduced by Barelli and Couvreur [4]. As the name suggests, these codes are the result of the application of both the trace and the norm operation to a certain support vector, and they are alternant codes. In particular, they are subfield subcodes of Reed–Solomon codes. The construction of these codes is given explicitly only for the specific case
where α is an element of trace 1.
The main idea of the attack is that there exists a specific norm-trace code that is the conductor of the secret subcode into the public code. By “conductor” the authors refer to the largest code for which the Schur product (i.e. the component-wise product of all codewords, denoted by
The authors present two strategies to determine the secret subcode. The first strategy is essentially an exhaustive search over all the codes of the proper co-dimension. This co-dimension is given by
The second strategy, instead, consists of solving a bilinear system, which is obtained using the parity-check matrix of the public code and treating as unknowns the elements of a generator matrix for the secret code (as well as the support vector
In any case, it is easy to deduce that the two parameters q and s are crucial in determining the cost of running this step of the attack, which dominates the overall cost. In fact, the authors are able to provide an accurate complexity analysis for the first strategy which confirms this intuition. The average number of iterations of the brute force search is given by
Early DAGS parameters. * Claimed.
| Security level* | q | m | n | k | s | t | w | Attack | |
| 1 | 2 | 832 | 416 | 43 | 13 | 104 | |||
| 3 | 2 | 1216 | 512 | 43 | 11 | 176 | |||
| 5 | 2 | 2112 | 704 | 43 | 11 | 352 |
As it is possible to observe, the attack complexity is especially low for the last set of parameters since the dyadic order s was chosen to be
Unfortunately, the attack authors were not able to provide a security analysis for the second strategy (bilinear system). This is due to the fact that the attack uses Gröbner based techniques, and it is very hard to evaluate the cost in this case (similarly to what happened for FOPT). In this case then, the only evidence the authors provide is experimental, and based on running the attack in practice on all the parameters. The authors report running times around 15 minutes for the first set and less than a minute for the last, while they admit they were not able to complete the execution in the middle case. This seems to match the evidence from the complexity results obtained for the first strategy, and suggests a speedup proportional to those. Further test runs are currently planned, but the fact that the attack already fails to run in practice for the middle set, gives us some confidence to believe that updated parameters will definitely make the attack infeasible.
5.4 Parameter selection
To choose our parameters, we keep in mind all the remarks from the previous sections about decoding attacks and structural attacks. As we have just seen, we need to respect the condition
In addition, we tune our parameters to optimize performance. In this regard, the best results are obtained when the extension degree m is as small as possible. This, however, requires the base field to be large enough to accommodate sufficiently big codes (against ISD attacks), since the maximum size for the code length n is capped by
Putting all the pieces together, we are able to present three sets of parameters, in Table 4. These correspond to three of the security levels indicated by NIST (first column), which are related to the hardness of performing a key search attack on three different variants of a block cipher, such as AES (with key length respectively 128, 192 and 256). As far as quantum attacks are concerned, we claim that ISD with Grover (see above) will usually require more resources than a Grover search attack on AES for the circuit depths suggested by NIST (parameter MAXDEPTH). Thus, classical security bits are the bottleneck in our case, and as such we choose our parameters to provide 128, 192 and 256 bits of classical security for security levels 1, 3 and 5 respectively. For practical reasons, during the rest of the paper we will refer to these parameters respectively as DAGS_1, DAGS_3 and DAGS_5.
Suggested DAGS parameters.
| Security level | q | m | n | k | s | t | w | BC | ||
| 1 | 2 | 832 | 416 | 43 | 13 | 104 | 25 | |||
| 3 | 2 | 1216 | 512 | 32 | 11 | 176 | 21 | |||
| 5 | 2 | 1600 | 896 | 32 | 11 | 176 | 21 |
For the above parameters, it is easy to observe that the value
6 Performance analysis
6.1 Components
DAGS operates on vectors of elements of the finite field
For DAGS_1, the finite field
6.2 Randomness generation
The randomness used in our implementation is provided by the NIST API. It uses AES as a PNGR, where NIST chooses the seed in order to have a controlled environment for tests. We use this random generator to obtain our input message
6.3 Efficient private key reconstruction and decoding
As mentioned in Section 3, in our scheme we use a standard alternant decoder (step (2) of Algorithm 3), which requires the input to be a matrix in alternant form, i.e.
Algorithm 4 (Alternant-Syndrome Computation).
Input received word
Compute the vector
Form intermediate matrix
Set first row equal to
Obtain row i, for
Sum elements in each row and output resulting vector.
6.4 Measurements
The implementation is in ANSI C, as requested for a generic reference implementation. For the measurements, we used an x64 Intel Core i5-5300U processor at 2.30 GHz, 16 GiB of RAM and GCC version 6.3.0 20170516 without any optimization, running on Debian 9.2.
We start by considering space requirements.
We recall the flow between two parties
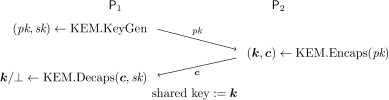
When instantiated with DAGS, the public key is given by the generator matrix G. The non-identity block
Memory requirements.
| Parameter set | Public key | Private key | Ciphertext |
| DAGS_1 | 8112 | 2496 | 656 |
| DAGS_3 | 11264 | 4864 | 1248 |
| DAGS_5 | 19712 | 6400 | 1632 |
Communication costs in protocol flow.
| Message flow | Transmitted message | Size | ||
| DAGS_1 | DAGS_3 | DAGS_5 | ||
| G | 8112 | 11264 | 19712 | |
| 656 | 1248 | 1632 | ||
We now move on to analyzing time measurements. We are using x64 architecture and our measurements use an assembly instruction to get the time counter. We do this by calling “rdtsc” before and after the instruction, which gives us the cycles used by each function. Table 7 gives the results of our measurements represented by the mean after running the code 50 times.
Timings.
| Cycles | |||
| Algorithm | DAGS_1 | DAGS_3 | DAGS_5 |
| Key Generation | 2540311986 | 4320206006 | 7371897084 |
| Encapsulation | 12108373 | 26048972 | 96929832 |
| Decapsulation | 215710551 | 463849016 | 1150831538 |
6.5 Comparison
We thought it useful to provide a comparison with other recently proposed code-based KEMs (and in particular, NIST submissions). In Table 8, we present data for Classic McEliece, BIKE and BIG QUAKE with regards to memory requirements, for the highest security level (256 bits classical). We did not deem necessary, on the other hand, to provide a comparison in terms of implementation timings, as reference implementations are designed for clarity, rather than performance.
It is easy to see that the public key is much smaller than Classic McEliece and BIG QUAKE, and similar to that of BIKE. With regards to the latter, note that, for the same security level, the total communication bandwidth is of the same order of magnitude. This is because DAGS uses much shorter codes, and as a consequence the ciphertext is considerably smaller than a BIKE ciphertext. Moreover, for the purposes of a fair comparison, we remark that BIKE uses ephemeral keys, has a non-negligible decoding failure rate and only claims IND-CPA security – all factors that can restrict its use in various applications.
Comparison of code-based KEMs (bytes).
| Parameter set | Public key | Private key | Ciphertext |
| Classic McEliece | 1047319 | 13908 | 226 |
| BIKE-1 | 8187 | 548 | 8187 |
| BIKE-2 | 4093 | 548 | 4093 |
| BIKE-3 | 9032 | 565 | 9032 |
| BIG QUAKE | 149800 | 41804 | 492 |
| DAGS_5 | 19712 | 6400 | 1632 |
7 Conclusion
In this paper, we presented DAGS, a key encapsulation mechanism based on quasi-dyadic generalized Srivastava codes. We proved that DAGS is IND-CCA secure in the random oracle model, and in the quantum random oracle model. Thanks to this feature, it is possible to employ DAGS not only as a key exchange protocol (for which IND-CPA would be a sufficient requirement), but also in other contexts such as hybrid encryption, where IND-CCA is of paramount importance.
In terms of performance, DAGS compares well with other code-based protocols, as shown by Table 8 and the related discussion (above). Another advantage of our proposal is that it does not involve any decoding error. This is particularly favorable in a comparison with some lattice-based schemes like [15], [2] and [14], as well as BIKE. No decoding error allows for a simpler formulation and better security bounds in the IND-CCA security proof.
Unlike traditional code-based protocols, DAGS features small sizes for all components, that is ciphertexts, private keys (thanks to our improved computation idea) and public keys. All the objects involved in the computations are vectors of finite fields elements, which in turn are represented as binary strings; thus computations are fast. The cost of computing the hash functions is minimized thanks to the parameter choice that makes sure the input
The current reference code for the scheme is available at the repository https://git.dags-project.org/dags/dags. Our team is currently at work to complete various implementations that can better showcase the potential of DAGS in terms of performance. These include code prepared with x86 assembly instructions (AVX) as well as a hardware implementation (FPGA) etc. A hint at the effectiveness of DAGS can be had by looking at the performance of the scheme presented in [16], which also features an implementation for embedded devices. In particular, we expect DAGS to perform especially well in hardware, due to the nature of the computations of the McEliece framework.
Finally, we would like to highlight that a DAGS-based key exchange features an “asymmetric” structure, where the bandwidth cost and computational effort of the two parties are considerably different. In particular, in the flow described in (6.1), the party
In light of all these aspects, we believe that DAGS is a promising candidate for post-quantum cryptography standardization as a key encapsulation mechanism.
A Note on the choice of ω
As discussed in Section 6.3, in our scheme we use a standard alternant decoder. After computing the syndrome of the word to be decoded, the next step is to recover the error locator polynomial
Of course, if one of the
Now, the generation of the error vector is random, hence we can assume the probability of having an error in position i to be around
As part of the key generation algorithm we assign to each
References
[1] A. Al Jabri, A statistical decoding algorithm for general linear block codes, Cryptography and Coding, Lecture Notes in Comput. Sci. 2260, Springer, Berlin (2001), 1–8. 10.1007/3-540-45325-3_1Search in Google Scholar
[2] E. Alkim, L. Ducas, T. Pöppelmann and P. Schwabe, Post-quantum key exchange - a new hope, Cryptology ePrint Archive Report 2015/1092 (2015), http://eprint.iacr.org/2015/1092. Search in Google Scholar
[3] M. Baldi, F. Chiaraluce, R. Garello and F. Mininni, Quasi-cyclic low-density parity-check codes in the McEliece cryptosystem, IEEE International Conference on Communications—ICC’07, IEEE Press, Piscataway (2007), 951–956. 10.1109/ICC.2007.161Search in Google Scholar
[4] E. Barelli and A. Couvreur, An efficient structural attack on nist submission dags, preprint (2018), https://arxiv.org/abs/1805.05429. 10.1007/978-3-030-03326-2_4Search in Google Scholar
[5] S. Barg, Some new NP-complete coding problems (in Russian), Problemy Peredachi Informatsii 30 (1994), no. 3, 23–28. Search in Google Scholar
[6] A. Barg, Complexity issues in coding theory, Handbook of Coding Theory. Vol. 1. Part 1: Algebraic Coding, Elsevier, Amsterdam (1998), 649–754. Search in Google Scholar
[7] P. S. L. M. Barreto, S. Gueron, T. Gueneysu, R. Misoczki, E. Persichetti, N. Sendrier and J.-P. Tillich, Cake: Code-based algorithm for key encapsulation, Cryptography and Coding—IMACC 2017, Springer, Cham (2017), 207–226. 10.1007/978-3-319-71045-7_11Search in Google Scholar
[8] P. S. L. M. Barreto, R. Lindner and R. Misoczki, Monoidic codes in cryptography, Post-quantum Cryptography, Lecture Notes in Comput. Sci. 7071, Springer, Heidelberg (2011), 179–199. 10.1007/978-3-642-25405-5_12Search in Google Scholar
[9] T. P. Berger, P.-L. Cayrel, P. Gaborit and A. Otmani, Reducing key length of the McEliece cryptosystem, Progress in Cryptology—AFRICACRYPT 2009, Lecture Notes in Comput. Sci. 5580, Springer, Berlin (2009), 77–97. 10.1007/978-3-642-02384-2_6Search in Google Scholar
[10] E. R. Berlekamp, R. J. McEliece and H. C. A. van Tilborg, On the inherent intractability of certain coding problems, IEEE Trans. Inform. Theory IT-24 (1978), no. 3, 384–386. 10.1109/TIT.1978.1055873Search in Google Scholar
[11] D. J. Bernstein, Grover vs. McEliece, Post-Quantum Cryptography, Lecture Notes in Comput. Sci. 6061, Springer, Berlin (2010), 73–80. 10.1007/978-3-642-12929-2_6Search in Google Scholar
[12] D. J. Bernstein, T. Chou and P. Schwabe, Mcbits: Fast constant-time code-based cryptography, Cryptographic Hardware and Embedded Systems—CHES 2013, Lecture Notes in Comput. Sci. 8086, Springer, Berlin (2013), 250–272. 10.1007/978-3-642-40349-1_15Search in Google Scholar
[13] B. Biswas and N. Sendrier, McEliece cryptosystem implementation: Theory and practice, Post-quantum Cryptography, Lecture Notes in Comput. Sci. 5299, Springer, Berlin (2008), 47–62. 10.1007/978-3-540-88403-3_4Search in Google Scholar
[14] J. Bos, C. Costello, L. Ducas, I. Mironov, M. Naehrig, V. Nikolaenko, A. Raghunathan and D. Stebila, Frodo: Take off the ring! Practical, quantum-secure key exchange from LWE, Cryptology ePrint Archive Report 2016/659 (2016), http://eprint.iacr.org/2016/659. 10.1145/2976749.2978425Search in Google Scholar
[15] J. W. Bos, C. Costello, M. Naehrig and D. Stebila, Post-quantum key exchange for the tls protocol from the ring learning with errors problem, IEEE Symposium on Security and Privacy, IEEE Press, Piscataway (2015), 553–570. 10.1109/SP.2015.40Search in Google Scholar
[16] P.-L. Cayrel, G. Hoffmann and E. Persichetti, Efficient implementation of a CCA2-secure variant of McEliece using generalized Srivastava codes, Public Key Cryptography—PKC 2012, Lecture Notes in Comput. Sci. 7293, Springer, Heidelberg (2012), 138–155. 10.1007/978-3-642-30057-8_9Search in Google Scholar
[17] N. T. Courtois, M. Finiasz and N. Sendrier, How to achieve a McEliece-based digital signature scheme, Advances in Cryptology—ASIACRYPT 2001, Lecture Notes in Comput. Sci. 2248, Springer, Berlin (2001), 157–174. 10.1007/3-540-45682-1_10Search in Google Scholar
[18] R. Cramer and V. Shoup, Design and analysis of practical public-key encryption schemes secure against adaptive chosen ciphertext attack, SIAM J. Comput. 33 (2003), no. 1, 167–226. 10.1137/S0097539702403773Search in Google Scholar
[19] J.-C. Deneuville, P. Gaborit and G. Zémor, Ouroboros: A simple, secure and efficient key exchange protocol based on coding theory, Post-quantum Cryptography, Lecture Notes in Comput. Sci. 10346, Springer, Cham (2017), 18–34. 10.1007/978-3-319-59879-6_2Search in Google Scholar
[20] J.-C. Faugère, V. Gauthier-Umaña, A. Otmani, L. Perret and J.-P. Tillich, A distinguisher for high-rate McEliece cryptosystems, IEEE Trans. Inform. Theory 59 (2013), no. 10, 6830–6844. 10.1109/TIT.2013.2272036Search in Google Scholar
[21] J.-C. Faugère, A. Otmani, L. Perret, F. de Portzamparc and J.-P. Tillich, Structural cryptanalysis of McEliece schemes with compact keys, Des. Codes Cryptogr. 79 (2016), no. 1, 87–112. 10.1007/s10623-015-0036-zSearch in Google Scholar
[22] J.-C. Faugère, A. Otmani, L. Perret and J.-P. Tillich, Algebraic cryptanalysis of McEliece variants with compact keys, Advances in Cryptology—EUROCRYPT 2010, Lecture Notes in Comput. Sci. 6110, Springer, Berlin (2010), 279–298. 10.1007/978-3-642-13190-5_14Search in Google Scholar
[23] J.-C. Faugère, A. Otmani, L. Perret and J.-P. Tillich, Algebraic cryptanalysis of McEliece variants with compact keys – towards a complexity analysis, Proceedings of the 2nd International Conference on Symbolic Computation and Cryptography—SCC’10, Laboratoire d’Informatique de Paris 6, Paris (2010), 45–55. Search in Google Scholar
[24] E. Fujisaki and T. Okamoto, Secure integration of asymmetric and symmetric encryption schemes, J. Cryptology 26 (2013), no. 1, 80–101. 10.1007/s00145-011-9114-1Search in Google Scholar
[25] Q. Guo, T. Johansson and P. Stankovski, A key recovery attack on MDPC with CCA security using decoding errors, Advances in Cryptology—ASIACRYPT 2016. Part I, Lecture Notes in Comput. Sci. 10031, Springer, Berlin (2016), 789–815. 10.1007/978-3-662-53887-6_29Search in Google Scholar
[26] Y. Hamdaoui and N. Sendrier, A non asymptotic analysis of information set decoding, Cryptology ePrint Archive Report 2013/162 (2013), http://eprint.iacr.org/2013/162. Search in Google Scholar
[27] D. Hofheinz, K. Hövelmanns and E. Kiltz, A modular analysis of the Fujisaki–Okamoto transformation, Theory of Cryptography. Part I, Lecture Notes in Comput. Sci. 10677, Springer, Cham (2017), 341–371. 10.1007/978-3-319-70500-2_12Search in Google Scholar
[28] G. Kachigar and J.-P. Tillich, Quantum information set decoding algorithms, Post-quantum Cryptography, Lecture Notes in Comput. Sci. 10346, Springer, Cham (2017), 69–89. 10.1007/978-3-319-59879-6_5Search in Google Scholar
[29] F. J. MacWilliams and N. J. A. Sloane, The Theory of Error-Correcting Codes. I, North-Holland Math. Libr. 16, North-Holland, Amsterdam, 1977, Search in Google Scholar
[30] R. J. McEliece, A public-key cryptosystem based on algebraic coding theory, Deep Space Netw. Prog. Rep. 44 (1978), 114–116. Search in Google Scholar
[31] R. Misoczki and P. S. L. M. Barreto, Compact mceliece keys from goppa codes, Selected Areas in Cryptography, Springer, Berlin (2009), 376–392. 10.1007/978-3-642-05445-7_24Search in Google Scholar
[32] R. Misoczki, J.-P. Tillich, N. Sendrier and P. L. S. M. Barreto, MDPC-McEliece: New McEliece variants from moderate density parity-check codes, International Symposium on Information Theory—ISIT 2013, IEEE Press, Piscataway (2013), 2069–2073. 10.1109/ISIT.2013.6620590Search in Google Scholar
[33]
R. Niebuhr,
Statistical decoding of codes over
[34]
R. Niebuhr, E. Persichetti, P.-L. Cayrel, S. Bulygin and J. Buchmann,
On lower bounds for information set decoding over
[35] R. Nojima, H. Imai, K. Kobara and K. Morozov, Semantic security for the McEliece cryptosystem without random oracles, Des. Codes Cryptogr. 49 (2008), no. 1–3, 289–305. 10.1007/s10623-008-9175-9Search in Google Scholar
[36] E. Persichetti, Compact McEliece keys based on quasi-dyadic Srivastava codes, J. Math. Cryptol. 6 (2012), no. 2, 149–169. 10.1515/jmc-2011-0099Search in Google Scholar
[37] E. Persichetti, Secure and anonymous hybrid encryption from coding theory, Post-Quantum Cryptography—PQCrypto 2013, Berlin, Heidelberg (2013), 174–187. 10.1007/978-3-642-38616-9_12Search in Google Scholar
[38]
C. Peters,
Information-set decoding for linear codes over
[39] E. Prange, The use of information sets in decoding cyclic codes, IRE Trans. IT-8 (1962), S5–S9. 10.1109/TIT.1962.1057777Search in Google Scholar
[40] D. V. Sarwate, On the complexity of decoding Goppa codes, IEEE Trans. Inform. Theory IT-23 (1977), no. 4, 515–516. 10.1109/TIT.1977.1055732Search in Google Scholar
[41] P. W. Shor, Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer, SIAM J. Comput. 26 (1997), no. 5, 1484–1509. 10.1137/S0097539795293172Search in Google Scholar
[42] F. Strenzke, A timing attack against the secret permutation in the McEliece PKC, Post-quantum Cryptography, Lecture Notes in Comput. Sci. 6061, Springer, Berlin (2010), 95–107. 10.1007/978-3-642-12929-2_8Search in Google Scholar
[43] F. Strenzke, E. Tews, H. G. Molter, R. Overbeck and A. Shoufan, Side channels in the McEliece PKC, Post-quantum Cryptography, Lecture Notes in Comput. Sci. 5299, Springer, Berlin (2008), 216–229. 10.1007/978-3-540-88403-3_15Search in Google Scholar
[44] https://bigquake.inria.fr/. Search in Google Scholar
[45] https://bikesuite.org. Search in Google Scholar
[46] http://christianepeters.wordpress.com/publications/tools/. Search in Google Scholar
[47] https://classic.mceliece.org/. Search in Google Scholar
[48] https://keccak.team/kangarootwelve.html. Search in Google Scholar
© 2018 Walter de Gruyter GmbH, Berlin/Boston
This article is distributed under the terms of the Creative Commons Attribution Non-Commercial License, which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.