

FF-HPINet: A Flipped Feature and Hierarchical Position Information Extraction Network for Lane Detection

Abstract
:1. Introduction
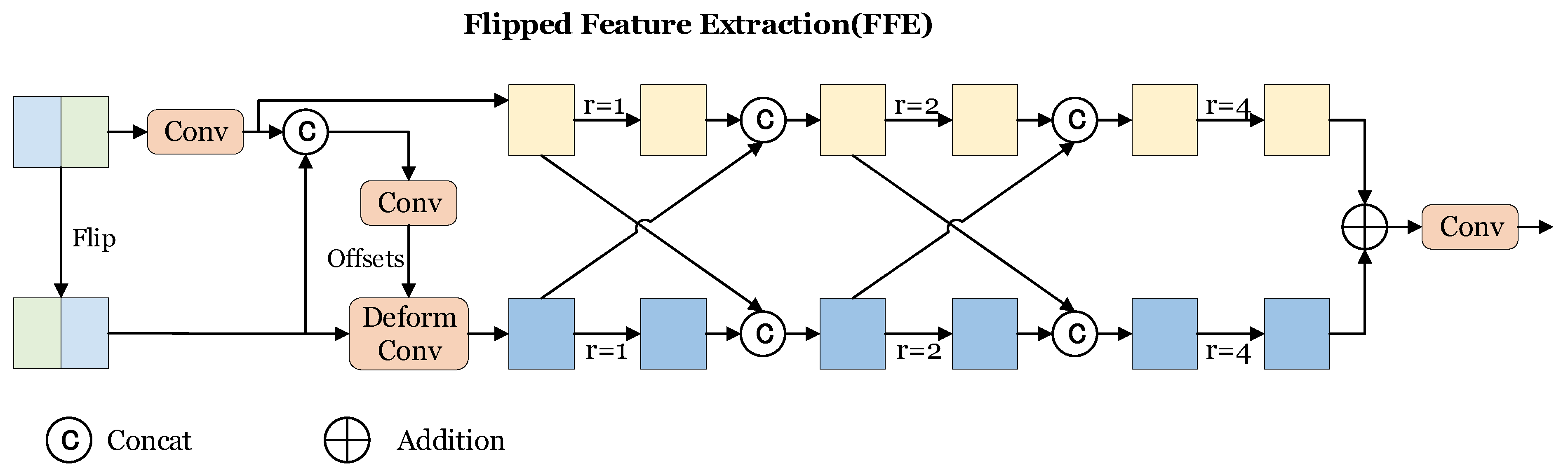
- We propose the Flipped Feature Extraction (FFE) module, which models the symmetric properties of lane lines and utilizes multi-scale receptive fields to collect contextual information, establishing effective interaction between flipped features and original features, enhancing the detection of target objects.
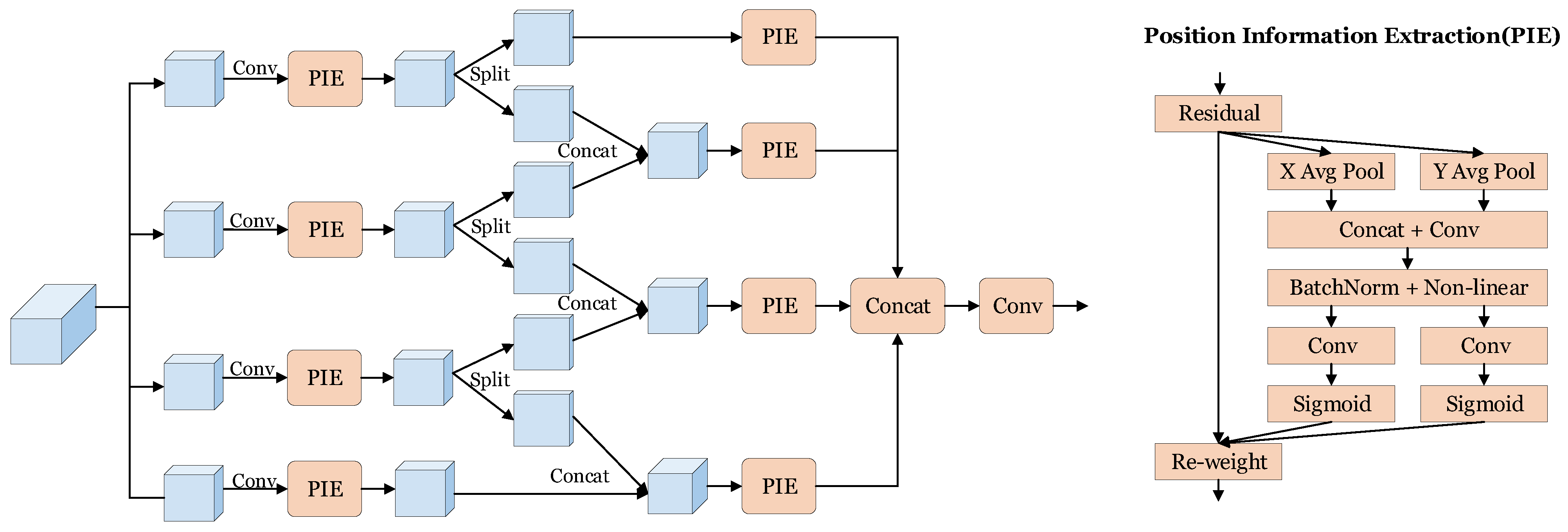
- We propose the Hierarchical Position Information Extraction (HPIE) module, which effectively aggregates positional information within feature maps, enhancing localization precision.
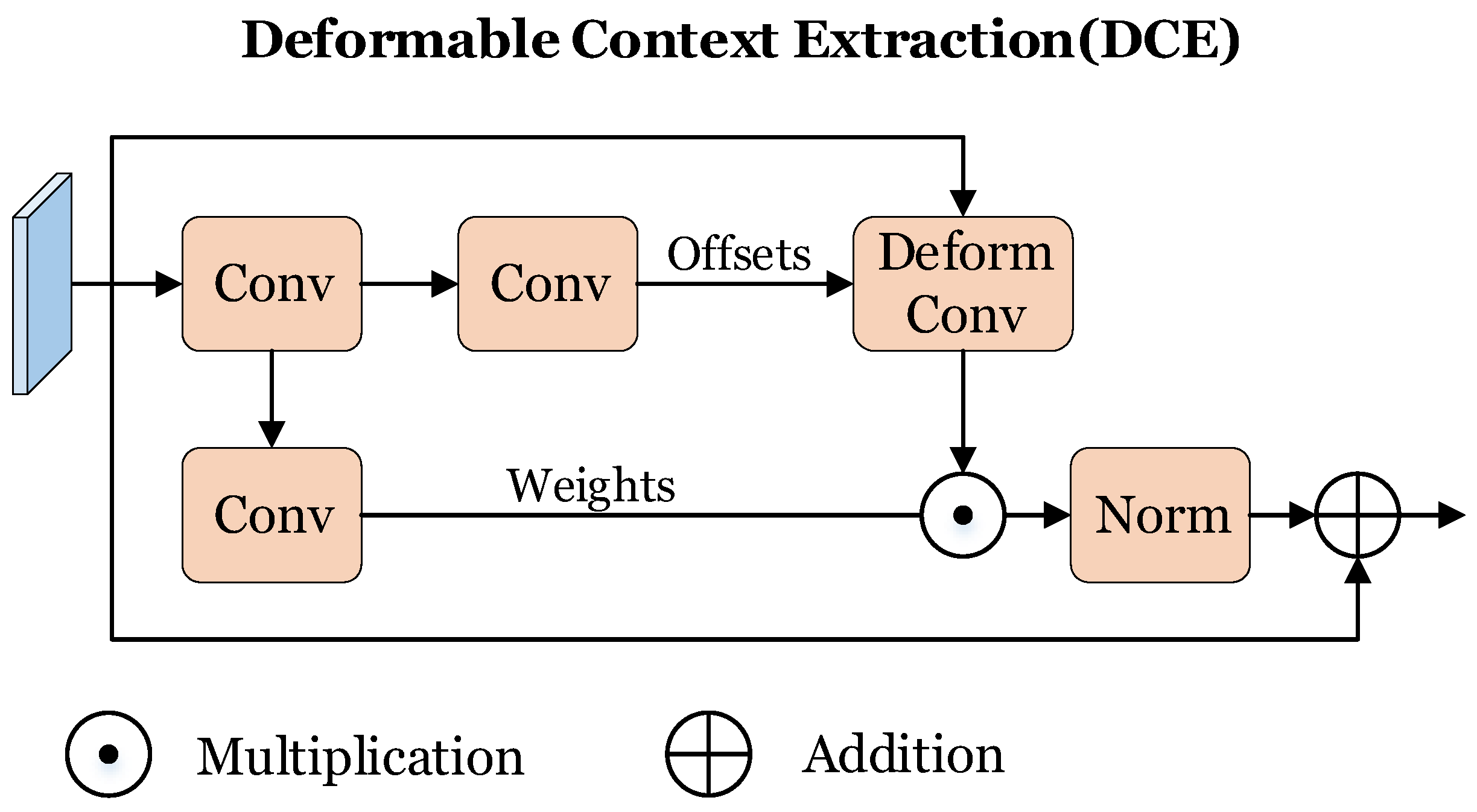
- We propose the Deformable Context Extraction (DCE) module, which meticulously extracts subtle and fine-grained information from the complex surrounding environment. It is adept at identifying and outputting relevant response features that are crucial for accurate lane line detection, boosting the overall performance and reliability of our proposed lane detection model.
- Our proposed FF-HPINet has demonstrated excellent performance on TuSimple and CULane datasets, achieving remarkable results in the field of lane detection.
2. Related Work
2.1. Lane Detection
2.2. Context Information
3. Method
3.1. Network Overview
3.2. Flipped Feature Extraction
3.3. Hierarchical Position Information Extraction
3.4. Deformable Context Extraction
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Comparison Results
4.5. Ablation Study
4.5.1. Effectiveness of FFE
4.5.2. Effectiveness of HPIE
4.5.3. Effectiveness of DCE
4.6. Analysis
4.7. Limitation and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Assidiq, A.A.; Khalifa, O.O.; Islam, M.R.; Khan, S. Real time lane detection for autonomous vehicles. In Proceedings of the 2008 International Conference on Computer and Communication Engineering, Kuala Lumpur, Malaysia, 13–15 May 2008; pp. 82–88. [Google Scholar]
- Berriel, R.F.; de Aguiar, E.; De Souza, A.F.; Oliveira-Santos, T. Ego-lane analysis system (elas): Dataset and algorithms. Image Vis. Comput. 2017, 68, 64–75. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.; Yang, Z.; Liu, H.; Cai, D. Resa: Recurrent feature-shift aggregator for lane detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3547–3554. [Google Scholar]
- Feng, Z.; Guo, S.; Tan, X.; Xu, K.; Wang, M.; Ma, L. Rethinking efficient lane detection via curve modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17062–17070. [Google Scholar]
- Qin, Z.; Zhang, P.; Li, X. Ultra fast deep lane detection with hybrid anchor driven ordinal classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 2555–2568. [Google Scholar] [CrossRef] [PubMed]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXIV 16. Springer: Cham, Switzerland, 2020; pp. 276–291. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Keep your eyes on the lane: Real-time attention-guided lane detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 294–302. [Google Scholar]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 286–291. [Google Scholar]
- Wang, Z.; Ren, W.; Qiu, Q. Lanenet: Real-time lane detection networks for autonomous driving. arXiv 2018, arXiv:1807.01726. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Hsu, Y.C.; Xu, Z.; Kira, Z.; Huang, J. Learning to cluster for proposal-free instance segmentation. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Lee, S.; Kim, J.; Shin Yoon, J.; Shin, S.; Bailo, O.; Kim, N.; Lee, T.H.; Seok Hong, H.; Han, S.H.; So Kweon, I. Vpgnet: Vanishing point guided network for lane and road marking detection and recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1947–1955. [Google Scholar]
- Yoo, S.; Lee, H.S.; Myeong, H.; Yun, S.; Park, H.; Cho, J.; Kim, D.H. End-to-end lane marker detection via row-wise classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1006–1007. [Google Scholar]
- Yu, Z.; Ren, X.; Huang, Y.; Tian, W.; Zhao, J. Detecting lane and road markings at a distance with perspective transformer layers. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Xu, H.; Wang, S.; Cai, X.; Zhang, W.; Liang, X.; Li, Z. Curvelane-nas: Unifying lane-sensitive architecture search and adaptive point blending. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XV 16. Springer: Cham, Switzerland, 2020; pp. 689–704. [Google Scholar]
- Li, X.; Li, J.; Hu, X.; Yang, J. Line-cnn: End-to-end traffic line detection with line proposal unit. IEEE Trans. Intell. Transp. Syst. 2019, 21, 248–258. [Google Scholar] [CrossRef]
- Van Gansbeke, W.; De Brabandere, B.; Neven, D.; Proesmans, M.; Van Gool, L. End-to-end lane detection through differentiable least-squares fitting. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–9. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Polylanenet: Lane estimation via deep polynomial regression. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6150–6156. [Google Scholar]
- Liu, R.; Yuan, Z.; Liu, T.; Xiong, Z. End-to-end lane shape prediction with transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3694–3702. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Oliva, A.; Torralba, A. The role of context in object recognition. Trends Cogn. Sci. 2007, 11, 520–527. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for small object detection. In Proceedings of the Computer Vision—ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part V 13. Springer: Cham, Switzerland, 2017; pp. 214–230. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Chen, Z.; Huang, S.; Tao, D. Context refinement for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 71–86. [Google Scholar]
- Chen, X.; Li, L.J.; Fei-Fei, L.; Gupta, A. Iterative visual reasoning beyond convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7239–7248. [Google Scholar]
- Yuan, Y.; Xiong, Z.; Wang, Q. VSSA-NET: Vertical spatial sequence attention network for traffic sign detection. IEEE Trans. Image Process. 2019, 28, 3423–3434. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Meng, L.; Li, H.; Chen, B.C.; Lan, S.; Wu, Z.; Jiang, Y.G.; Lim, S.N. Adavit: Adaptive vision transformers for efficient image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12309–12318. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Zheng, Y.; Jiang, W. Evaluation of vision transformers for traffic sign classification. Wirel. Commun. Mob. Comput. 2022, 2022, 3041117. [Google Scholar] [CrossRef]
- Tummala, S.; Kadry, S.; Bukhari, S.A.C.; Rauf, H.T. Classification of brain tumor from magnetic resonance imaging using vision transformers ensembling. Curr. Oncol. 2022, 29, 7498–7511. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Chen, Q.; Guo, J.; Shi, R. Attention-guided context feature pyramid network for object detection. arXiv 2020, arXiv:2005.11475. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE Onternational Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Ke, Q.; Zhang, P. CS-HSNet: A cross-siamese change detection network based on hierarchical-split attention. IEEE J. Sel. Top. Appl. Earth Obs. Remot. Sens. 2021, 14, 9987–10002. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- TuSimple. Tusimple Benchmark. 2022. Available online: https://github.com/TuSimple/tusimple-benchmark (accessed on 1 September 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Jin, D.; Park, W.; Jeong, S.G.; Kwon, H.; Kim, C.S. Eigenlanes: Data-driven lane descriptors for structurally diverse lanes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17163–17171. [Google Scholar]
- Abualsaud, H.; Liu, S.; Lu, D.B.; Situ, K.; Rangesh, A.; Trivedi, M.M. Laneaf: Robust multi-lane detection with affinity fields. IEEE Robot. Autom. Lett. 2021, 6, 7477–7484. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | F1 | Accuracy | FP | FN |
|---|---|---|---|---|
| SCNN [3] | 95.97 | 96.53 | 6.17 | 1.80 |
| LaneNet [9] | 94.80 | 96.40 | 7.80 | 2.44 |
| SAD-R18 [11] | 93.79 | 96.02 | 7.86 | 4.51 |
| SAD-R34 [11] | 94.68 | 96.24 | 7.12 | 3.44 |
| E2E-R18 [14] | 96.40 | 96.04 | 3.11 | 4.09 |
| E2E-R34 [14] | 96.58 | 96.22 | 3.08 | 3.76 |
| LSTR [20] | 96.85 | 96.18 | 2.91 | 3.38 |
| LaneATT-R18 [8] | 96.71 | 95.57 | 3.56 | 3.01 |
| LaneATT-R34 [8] | 96.77 | 95.63 | 3.53 | 2.92 |
| RESA-R18 [4] | 96.61 | 96.70 | 3.95 | 2.83 |
| RESA-R34 [4] | 96.94 | 96.82 | 3.63 | 2.48 |
| Eigenlanes [41] | 96.40 | 95.62 | 3.20 | 3.99 |
| UFLDv2-R18 [6] | 96.16 | 95.65 | 3.06 | 4.61 |
| UFLDv2-R34 [6] | 96.22 | 95.56 | 3.18 | 4.37 |
| BézierLaneNet-R18 [5] | 95.05 | 95.41 | 5.30 | 4.60 |
| BézierLaneNet-R34 [5] | 95.50 | 96.65 | 5.10 | 3.90 |
| FF-HPINet-R18 | 96.84 | 95.63 | 3.50 | 2.81 |
| FF-HPINet-R34 | 97.00 | 95.67 | 3.12 | 2.88 |
| Method | Total | Normal | Crowd | Dazzle | Shadow | No Line | Arrow | Curve | Cross | Night |
|---|---|---|---|---|---|---|---|---|---|---|
| SCNN [3] | 71.60 | 90.60 | 69.70 | 58.50 | 66.90 | 43.40 | 84.10 | 64.40 | 1990 | 66.10 |
| SAD-R18 [11] | 70.50 | 89.80 | 68.10 | 59.80 | 67.50 | 42.50 | 83.90 | 65.50 | 1995 | 64.20 |
| SAD-R34 [11] | 70.70 | 89.90 | 68.50 | 59.90 | 67.70 | 42.20 | 83.80 | 66.00 | 1960 | 64.60 |
| CurveLane-L [16] | 74.80 | 90.70 | 72.30 | 67.70 | 70.10 | 49.40 | 85.80 | 68.40 | 1746 | 68.90 |
| E2E-R18 [14] | 70.80 | 90.00 | 69.70 | 60.20 | 62.50 | 43.20 | 83.20 | 70.30 | 2296 | 63.30 |
| E2E-R34 [14] | 71.50 | 90.40 | 69.90 | 61.50 | 68.10 | 45.00 | 83.70 | 69.80 | 2077 | 63.20 |
| LaneATT-R18 * [8] | 74.81 | 90.91 | 72.66 | 65.28 | 70.59 | 47.89 | 85.16 | 62.72 | 1193 | 68.84 |
| LaneATT-R34 * [8] | 76.60 | 92.12 | 74.91 | 66.97 | 77.75 | 49.24 | 88.24 | 67.54 | 1313 | 70.55 |
| RESA-R34 [4] | 74.50 | 91.90 | 72.40 | 66.50 | 72.00 | 46.30 | 88.10 | 68.60 | 1896 | 69.80 |
| LaneAF-ENet [42] | 74.24 | 90.12 | 72.19 | 68.70 | 76.34 | 49.13 | 85.13 | 64.40 | 1934 | 68.67 |
| UFLDv2-R18 [6] | 75.00 | 91.80 | 73.30 | 65.30 | 75.10 | 47.60 | 87.90 | 68.50 | 2075 | 70.70 |
| UFLDv2-R34 [6] | 76.00 | 92.50 | 74.80 | 65.50 | 75.50 | 49.20 | 88.80 | 70.10 | 1910 | 70.80 |
| BézierLaneNet-R18 [5] | 73.67 | 90.22 | 71.55 | 62.49 | 70.91 | 45.30 | 84.09 | 58.98 | 996 | 68.70 |
| BézierLaneNet-R34 [5] | 75.57 | 91.59 | 73.20 | 69.20 | 76.74 | 48.05 | 87.16 | 62.45 | 888 | 69.90 |
| FF-HPINet-R18 | 75.85 | 91.45 | 73.36 | 67.20 | 72.48 | 49.12 | 86.78 | 64.39 | 1002 | 70.35 |
| FF-HPINet-R34 | 76.84 | 91.92 | 75.05 | 66.80 | 76.18 | 49.55 | 87.76 | 68.06 | 1061 | 71.69 |
| Model | FFE | HPIE | DCE | F1 |
|---|---|---|---|---|
| 1 | ✓ | 75.36 | ||
| 2 | ✓ | 75.44 | ||
| 3 | ✓ | 75.16 | ||
| 4 | ✓ | ✓ | 75.61 | |
| 5 | ✓ | ✓ | 75.62 | |
| FF-HPINet | ✓ | ✓ | ✓ | 75.85 |
| r | F1 | FPS |
|---|---|---|
| r = 1, 2, 4 | 75.85 | 144 |
| r = 1, 2, 8 | 75.56 | 144 |
| r = 1, 4, 8 | 75.63 | 144 |
| r = 2, 4, 8 | 75.45 | 144 |
| m | F1 | FPS |
|---|---|---|
| m = 2 | 75.36 | 165 |
| m = 4 | 75.85 | 144 |
| m = 8 | 75.66 | 128 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Zhang, P. FF-HPINet: A Flipped Feature and Hierarchical Position Information Extraction Network for Lane Detection. Sensors 2024, 24, 3502. https://doi.org/10.3390/s24113502
Zhou X, Zhang P. FF-HPINet: A Flipped Feature and Hierarchical Position Information Extraction Network for Lane Detection. Sensors. 2024; 24(11):3502. https://doi.org/10.3390/s24113502
Chicago/Turabian StyleZhou, Xiaofeng, and Peng Zhang. 2024. "FF-HPINet: A Flipped Feature and Hierarchical Position Information Extraction Network for Lane Detection" Sensors 24, no. 11: 3502. https://doi.org/10.3390/s24113502