
DNA (biologie)

| Deel van een serie artikelen over Genetica | ||||
|---|---|---|---|---|
.jpg)
| ||||
| Stuifmeelcellen in meiose | ||||
| Algemeen | ||||
|
Chromosoom · DNA · Erfelijkheid · Genetische variatie · Genoom · Mutatie · Nucleotide · RNA | ||||
| Onderzoek | ||||
|
DNA-analyse · Gentechnologie · Genomica · Recombinant DNA · Sequencing | ||||
| Vakgebieden | ||||
|
Epigenetica · Klinische genetica · Mendel · Moleculaire genetica · Populatiegenetica | ||||
| ||||
Desoxyribonucleïnezuur, beter bekend als DNA,[a] is het biologische macromolecuul dat in alle levende cellen de basis vormt van erfelijkheid. DNA is een zeer lang polymeer, en bevat de genetische instructies voor de ontwikkeling, het functioneren, de groei en de voortplanting van alle bekende organismen en vele virussen.
DNA heeft een ingewikkelde chemische structuur. Het is opgebouwd uit twee ketens van nucleotiden, die in de vorm van een dubbele helix met elkaar vervlochten zijn. Een nucleotide bestaat uit een van de vier stikstofbasen (adenine, guanine, thymine of cytosine), een suikergroep genaamd desoxyribose, en een fosfaatgroep. De desoxyribose en de fosfaatgroep verbinden de nucleotiden in een keten aan elkaar en vormen de 'ruggengraat' van het DNA. De basen liggen tegenover elkaar, waarbij A altijd paart met T en G altijd met C.
De volgorde van de basen in het DNA vormt een code die het organisme informatie geeft hoe het eiwitten kan maken. Eiwitten bepalen op hun beurt alle verrichtingen en de structuur van de cel. Een stuk DNA dat voor een bepaalde eigenschap codeert, vormt een gen. De expressie van een gen, die via transcriptie en translatie verloopt, wordt zeer precies gereguleerd.
In de cellen van dieren, planten en andere eukaryoten is het DNA opgedeeld in een aantal losse strengen, de chromosomen. In een chromosoom is het DNA in hoge mate opgevouwen en opgerold rond eiwitten. Voorafgaand aan iedere celdeling zullen de chromosomen in hun geheel gekopieerd worden, een proces genaamd DNA-replicatie, en vervolgens verdeeld worden over iedere dochtercel. Bij eukaryoten ligt het DNA opgeslagen in de celkern, terwijl het bij bacteriën en archaea los in het cytoplasma voorkomt, vaak als een circulair chromosoom.
Biochemie
[bewerken | brontekst bewerken]Structuur
[bewerken | brontekst bewerken]
DNA bestaat in levende organismen uit twee lange, polymere ketens van vier verschillende bouwstenen, de nucleotiden. Nucleotiden zijn platte moleculen, opgebouwd uit twee delen: een suikerverbinding met een daaraan gebonden fosfaatgroep, en een stikstof-bevattende base.[1] In het geval van DNA is de suikergroep een desoxyribose (vandaar de naam desoxyribonucleïnezuur), en de stikstofbase is ofwel een adenine (A), een thymine (T), guanine (G) of een cytosine (C). De nucleotiden zijn covalent met elkaar verbonden in de keten via de suiker-fosfaatgroepen.[b] Deze vormen als het ware de 'ruggengraat' van het DNA.
In een normale situatie liggen de twee ketens van het DNA-molecuul tegenover elkaar, waarbij de basen van de ene keten zich door middel van waterstofbruggen hechten aan die van de andere keten. Daarbij ligt A telkens tegenover een T en C tegenover G. De twee ketens liggen gedraaid om elkaar (in de vorm van een dubbele helix), waarbij de basenparen de twee ketens verbinden als de treden van een wenteltrap. De ontdekking van de helixstructuur van DNA was een mijlpaal in de wetenschap en betekende een enorme stimulans voor de ontwikkeling van de moleculaire biologie.[2]
In het DNA draaien de twee nucleotideketens rond een gemeenschappelijke as. Eén volledige winding bestrijkt ongeveer tien nucleotiden en heeft een lengte van 34 ångström (3,4 nanometer).[3] De helix zelf heeft een breedte van 20 ångström. De stikstofbasen wijzen in de helix naar binnen; de fosfaatribose-ruggengraat vormt de buitenzijde van de helix en staat in contact met het waterige milieu. Omdat DNA in levende cellen uit twee strengen bestaat, wordt het dubbelstrengs genoemd.
Polariteit
[bewerken | brontekst bewerken]
De manier waarop nucleotiden aaneengeschakeld zijn, geeft de DNA-keten een bepaalde chemische polariteit (richting).[4] Binnen een DNA-streng zitten alle nucleotiden in dezelfde oriëntatie aan elkaar gekoppeld. Als men de koolstofatomen van de suikergroep telt, valt op dat de hydroxylgroep altijd aan het derde koolstofatoom vastzit, en de fosfaatgroep aan het vijfde koolstofatoom. De gehele DNA-streng krijgt zodoende twee verschillende uiteinden: een zogenaamd 3'-eind en een 5'-eind.[5] Genetici gebruiken deze aanduidingen om de leesrichting van een DNA-sequentie op een consistente manier aan te geven.
Om basenparing mogelijk te maken, moeten de twee nucleotideketens in omgekeerde richting tegenover elkaar liggen. Met andere woorden, de polariteit van de ene streng is tegengesteld aan die van de andere streng. Men zegt wel dat de strengen antiparallel tegenover elkaar liggen. In genetisch onderzoek, waarbij men vaak geïnteresseerd is in de coderende stukken in het DNA, worden de verwante termen sense en antisense gebruikt.[6] Een stuk DNA wordt sense genoemd als de nucleotidevolgorde hetzelfde is als die van het mRNA (en dus codeert voor eiwitten). De andere streng, die niet codeert, wordt antisense genoemd.
Basenparen
[bewerken | brontekst bewerken]In het dubbelstrengse DNA ligt de stikstofbase adenine altijd tegenover thymine, en guanine altijd tegenover cytosine. Dit principe wordt complementaire basenparing genoemd. In beide gevallen ligt een grotere tweeringige base (een purine) tegenover een kleinere éénringige base (een pyrimidine).[1] Dit is de meest energiegunstige conformatie waarop de basen een interactie met elkaar kunnen aangaan binnen de helix. De basenparen A–T en G–C hebben bovendien een vergelijkbare breedte, waardoor de suiker-fosfaatruggengraat van beide partnerstrengen op constante afstand worden gehouden en dus op een vloeiende wijze om elkaar heen wentelen.[5]


Complementaire basenparing is een fundamentele eigenschap van het genetisch materiaal.[7] Het verklaart namelijk het principe waarmee de genetische informatie gekopieerd en doorgegeven kan worden aan het nageslacht. Omdat de volgorde van nucleotiden van de ene streng exact complementair is aan die van de andere streng, is het mogelijk dat elke streng kan fungeren als een matrijs (template) voor de synthese van een nieuwe complementaire streng.[5] Tijdens dit semiconservatieve proces van replicatie – waarbij DNA gekopieerd wordt – gaan de twee strengen uit elkaar, en dient elke streng als een matrijs voor de polymerisatie van een nieuwe complementaire streng die identiek is aan de vorige partnerstreng. Op deze manier wordt genetische informatie gericht in stand gehouden.
Groeven
[bewerken | brontekst bewerken]
Over het oppervlak van de dubbelstrengse DNA-helix lopen inkepingen, de zogenaamde groeven.[8] Omdat de twee nucleotideketens niet precies symmetrisch om elkaar heen draaien, is de ene groeve wat ruimer dan de andere. Men maakt onderscheid tussen een brede groeve (major groove) en een smalle groeve (minor groove). De brede groeve is 12 ångström breed, en de smalle groeve 6 ångström.
In de groeven kunnen DNA-bindende eiwitten, zoals transcriptiefactoren of endonucleases, contact maken met de stikstofbasen. Eiwitten die als taak hebben om bepaalde nucleotidesequenties te herkennen, kunnen via een groeve aan het DNA vasthechten. Aan de randen van de groeve bevinden zich namelijk patronen van waterstofbrug-vormende groepen die specifiek zijn voor bepaalde sequenties.[9] Op deze manier kan de sequentie-informatie van het DNA door eiwitten herkend en afgelezen worden zonder de helix te openen.
Lengte en hoeveelheid
[bewerken | brontekst bewerken]DNA-moleculen zijn extreem lang in vergelijking met hun diameter. Onder de elektronenmicroscoop zien ze er dan ook uit als langgerekte draden. Zelfs kleine DNA-moleculen van virussen, zoals die van bacteriofaag λ, zijn relatief lang. Er zijn verschillende manieren om de lengte van DNA-moleculen uit te drukken. De meest gebruikte lengtemaat is in het aantal basen waaruit de DNA-keten bestaat. In de praktijk zijn DNA-moleculen kilobasen (kb) tot vele megabasen (Mb) lang. Zo is het chromosoom van de laboratoriumbacterie E. coli ongeveer 6,4 Mb groot. Het DNA van de mens, en veel andere primaten, heeft een totale lengte van ongeveer 3,0 gigabasen (Gb).
- Elektronenmicroscopische opnamen van DNA
-
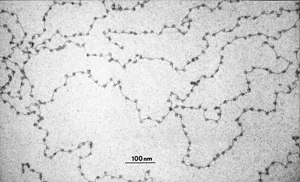 Gedespiraliseerd DNA, waarbij de DNA-keten rond eiwitten is gewonden als kralen aan een ketting
Gedespiraliseerd DNA, waarbij de DNA-keten rond eiwitten is gewonden als kralen aan een ketting -
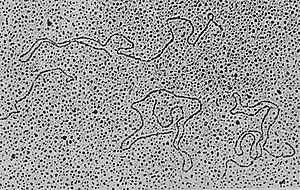 Enkele losse DNA-fragmenten, geïsoleerd uit een dubbelstrengs DNA-virus
Enkele losse DNA-fragmenten, geïsoleerd uit een dubbelstrengs DNA-virus
.jpg)
.jpg)
Een andere manier om de lengte van DNA aan te geven is de fysieke lengte van de dubbelstrengse helix. Wanneer het DNA van een diploïde menselijke cel volledig uitgerold zou worden, zou het theoretisch een lengte hebben van ruim twee meter.[10] Het is dus noodzakelijk dat de ruimtelijke structuur van DNA zeer compact is. In cellen van eukaryoten is het DNA dan ook in vergaande mate gespiraliseerd en opgerold rond eiwitten (histonen). Het gespiraliseerde DNA dat aanwezig is in de celkern, wordt ook wel chromatine genoemd. De structuur van het chromatine zorgt ervoor dat het DNA niet in de knoop raakt, en speelt een belangrijke rol tijdens genexpressie en celdeling. Bij mensen is er in een gemiddelde lichaamscel ongeveer 6,0 picogram DNA aanwezig.[4]
Alternatieve DNA-structuren
[bewerken | brontekst bewerken]Het ruimtelijk model dat in 1953 door Watson en Crick werd opgesteld, is in feite een gemiddelde structuur van het DNA, hetgeen tegenwoordig B-DNA wordt genoemd. Structuurbiologisch onderzoek aan zuivere DNA-kristallen heeft aangetoond dat er belangrijke lokale variaties op deze gemiddelde structuur kunnen optreden, waarbij de basen kunnen draaien en de groeven dieper of ondieper kunnen zijn.[11] Twee belangrijke variante structuren zijn A-DNA en Z-DNA. Deze treden bijvoorbeeld op bij het loswikkelen van de DNA-helix tijdens transcriptie. De biologische rol van de verschillende structuurvariaties is nog grotendeels onduidelijk, maar er zijn aanwijzingen dat ze een rol spelen in genregulatie, totstandkoming van segmentmutaties en genoomevolutie.[12]

Een andere structurele eigenschap die inherent is aan de helixstructuur van DNA is een fenomeen genaamd supercoiling.[13] DNA-supercoiling vindt plaats wanneer er mechanische spanningen optreden als het DNA lokaal ontrold wordt, zodat er in naastgelegen DNA-gebieden 'superwindingen' ontstaan. Supercoiling treedt onder meer op tijdens de transcriptie en replicatie, voornamelijk wanneer de bewegingsvrijheid van het DNA klein is (bijvoorbeeld bij een DNA-ring zoals het chromosoom van bacteriën, of bij de hechte windingen rond histonen). Een groep van enzymen genaamd topo-isomerases kunnen de windingsspanningen opheffen door snel de fosfodi-esterbindingen in de nucleotideketens te verbreken en vernieuwen.[14]
Guaninerijk DNA, dat bijvoorbeeld voorkomt in de telomeren, kan een bijzondere secundaire structuur vormen, de zogenaamde G-quadruplex.[15] Een G-quadruplex is samengesteld uit vier guaninebasen die in het platte vlak gerangschikt zijn, en alle vier bij elkaar worden gehouden door waterstofbruggen. De structuur wordt gestabiliseerd door positieve tegenionen zoals kalium. DNA-vouwingstructuren als de G-quadruplex kunnen de genoominstabiliteit beïnvloeden, waardoor ze onder meer in de belangstelling zijn gekomen als target voor antikankermedicijnen.[16]
Fysiek voorkomen
[bewerken | brontekst bewerken].jpg)
Zuiver DNA heeft op macroscopisch niveau een witachtig, draderig uiterlijk. Een oplossing met geconcentreerd genomisch DNA is slijmerig, en heeft een relatief hoge viscositeit. In het laboratorium is DNA relatief eenvoudig te isoleren uit biologische materialen zoals bloed, cellen of weefsels van planten en dieren. Het zuiveren van DNA (DNA-extractie) vindt meestal plaats door cellen open te breken (te lyseren) met een mild detergens, eiwitten en andere cellulaire componenten te verwijderen, en het DNA te precipiteren door een zout en een alcohol toe te voegen.[17] Extractie van DNA en andere nucleïnezuren is een standaardprocedure in de moleculaire biologie en het forensisch onderzoek.
Biologische functies
[bewerken | brontekst bewerken]
Het DNA is de universele drager van genetische informatie. Al lang voor de ontdekking van de moleculaire basis van erfelijkheid was duidelijk dat overerfbare factoren (genen) instructies moeten bevatten voor de aanmaak van eiwitten. Eiwitten staan aan de basis van alle celactiviteit, en hun biologische functie wordt bepaald door hun specifieke ruimtelijke structuur. Deze structuur is afhankelijk van de volgorde van aminozuren waaruit het eiwit bestaat. De lineaire sequentie van nucleotiden moet dus op een bepaalde manier te vertalen zijn naar een sequentie van aminozuren. Hoe het vierletterige DNA-alfabet overeenkomt met het 20-letterige aminozuuralfabet – de genetische code – werd ongeveer een decennium na de ontdekking van de DNA-helix ontrafeld.[5]
Genen en genomen
[bewerken | brontekst bewerken]Levende wezens verschillen van elkaar door verschillen in de erfelijke aanleg. Het DNA van ieder individu is uniek en bepaalt voor een belangrijk deel hoe het individu zich ontwikkelt, gedraagt en functioneert. In de genetica bestudeert men hoe deze erfelijke instructies, die het organisme van zijn ouders heeft meegekregen (het genotype), tot uiting worden gebracht in de verzameling van waarneembare kenmerken (het fenotype).[18]
Organismen geven eigenschappen door in discrete eenheden van erfelijk materiaal: genen. Op moleculair niveau is een gen te beschrijven als een stuk DNA dat codeert voor een bepaald eiwit. Genen bevatten een open leesraam – een regio die overgeschreven kan worden naar een mRNA-molecuul – en zijn daarnaast voorzien van vele regulatoire sequenties zoals promotors en enhancers, die bepalen hoe vaak en onder welke omstandigheden het gen tot expressie komt.[19] De principes van genexpressie zijn voor alle bekende levensvormen in grote lijnen hetzelfde.[20]
De volledige genetische samenstelling van een organisme noemt men het genoom. Het genoom codeert voor alle eiwitten en RNA-moleculen die het organisme in zijn leven ooit zal aanmaken. De hoeveelheid informatie in het genoom is ontzagwekkend. Om bijvoorbeeld de complete nucleotidevolgorde in het menselijk genoom fysiek uit te schrijven, zijn duizenden boeken nodig. Bij de meeste organismen vormen eiwit-coderende genen slechts een kleine fractie van het totale genetisch materiaal. Bij de mens is dit bijvoorbeeld maar 1.5%. Het merendeel van het DNA is niet-coderend.[21]

Genexpressie
[bewerken | brontekst bewerken]
De genetische informatie die in het DNA vastligt, stuurt de synthese van de biomoleculen waaruit het organisme bestaat. Bij alle levende wezens verloopt deze expressie van genetische informatie volgens een aantal vaste stappen, die leiden tot de aanmaak van twee klassen van biologische polymeren: RNA-moleculen en eiwitmoleculen.
Het proces van genexpressie begint met de transcriptie, waarbij langs een stuk DNA (een gen) een losse complementaire keten van RNA wordt gemaakt. Deze RNA-keten is in feite een kopie van het coderende stukje DNA en draagt de instructies voor de aanmaak van een specifiek eiwit. Vervolgens wordt in een proces genaamd translatie, de code in het mRNA omgezet in een specifieke volgorde van aminozuren: de bouwstenen van een eiwit.[20]
Hetzelfde stuk DNA kan herhaaldelijk worden afgeschreven naar vele complementaire RNA-kopieën. Het DNA is dus te beschouwen als het vaststaande archief, terwijl het RNA meer te vergelijken is met wegwerpbare boodschappenlijstjes die continu in grote hoeveelheden worden geproduceerd. De meeste RNA-moleculen die in de cel worden gemaakt, dienen als boodschappermolecuul voor de eiwitsynthese, en worden daarom messenger RNA (mRNA) genoemd.[22]
DNA-replicatie
[bewerken | brontekst bewerken]
Voordat een cel kan delen, moet het zijn genetisch materiaal volledig kopiëren. In planten en dieren betekent dit dat alle chromosomen worden verdubbeld, zodat iedere dochtercel een complete en identieke verzameling genen meekrijgt. Dit proces van verdubbeling, de DNA-replicatie, wordt in verschillende organismen op verschillende manieren gestart en gaande gehouden, maar de basisprincipes zijn altijd hetzelfde: de dubbelstrengse helix gaat uit elkaar, en iedere losse streng dient als een sjabloon voor de polymerisatie van een complementaire, nieuwe streng.[20]
Replicatie is een complex proces waarbij vele enzymen en andere eiwitten zijn betrokken. Het proces begint wanneer de waterstofbruggen tussen de basenparen verbroken worden door het enzym helicase. De helixstructuur verdwijnt en de twee strengen gaan uit elkaar. In het kernplasma bevinden zich onder andere de vrije nucleotiden dATP, dTTP, dGTP en dCTP: de bouwstenen van DNA-strengen. Het enzym DNA-polymerase schuift vervolgens langs de enkelvoudige ketens en bindt dATP, dTTP, dGTP en dCTP uit het kernplasma aan de vrijgekomen stikstofbasen.[23] Het kopiëren van DNA gebeurt met een precisie die aan het wonderbaarlijke grenst: niet meer dan één fout per miljoen toegevoegde nucleotiden.[24]
Het DNA-polymerase leest de DNA-streng af van het 3’-eind naar het 5’-eind, waardoor de nieuwe DNA-streng wordt gesynthetiseerd van het 5’-eind naar het 3’-eind. De reden hiervoor is dat een volgende nucleotide alleen kan aanhaken aan de hydroxylgroep van een nucleotide dat al is ingebouwd.[23] Langs beide nucleotideketens bewegen de DNA-polymerases zich dus in tegengestelde richting om een nieuwe keten te synthetiseren.
DNA-replicatie begint bij een vast startpunt (origin of replication). Bij eukaryoten bevat een DNA-molecuul veel replicatiestartpunten.[25] Een DNA-molecuul van een prokaryoot heeft er over het algemeen maar één. Meestal zijn deze startpunten AT-rijke sequenties, omdat de adenine-thymine basenparen maar via twee waterstofbruggen verbonden zijn en dus relatief makkelijk uit elkaar gaan.[25]
DNA-schade en -reparatie
[bewerken | brontekst bewerken]
Hoewel DNA een stabiel molecuul is – wat immers ook nodig is als drager van erfelijke informatie – kunnen er spontane willekeurige veranderingen optreden aan zijn chemische structuur. Deze veranderingen doen zich voortdurend voor, ook onder normale omstandigheden. Ze treden bijvoorbeeld op onder invloed van hitte, stofwisselingsprocessen, verschillende typen straling en chemicaliën uit de omgeving.[26] Wanneer de chemische verandering de nucleotidevolgorde treft, spreekt men van een genetische mutatie.
De manier waarop DNA schade oploopt verschilt per type mutageen. Ultraviolet licht veroorzaakt bijvoorbeeld zogenaamde thyminedimeren; twee naastgelegen thyminebasen raken daarbij covalent verbonden.[c] Als dit niet hersteld wordt, zal het leiden tot de vervanging of substitutie van een base in het dochter-DNA. Oxiderende stoffen en vrije radicalen kunnen het DNA op andere manieren beschadigen, bijvoorbeeld door de basen te deamineren.[27] Ook dit veroorzaakt een mutatie in de basenvolgorde.
Sommige chemische stoffen kunnen zich tussen de basenparen nestelen, een fenomeen dat intercalatie wordt genoemd. De meeste intercalerende stoffen hebben een aromatische ring, zoals ethidiumbromide, acridinen, of het dodelijke toxine benzo(a)pyreen.[28] Intercalerende stoffen verstoren de ruimtelijke structuur van de dubbele helix, waardoor processen als transcriptie en replicatie niet goed kunnen plaatsvinden. Het is dan ook geen verrassend gegeven dat veel intercalerende stoffen te boek staan als toxisch of kankerverwekkend.
Herstelmechanismen
[bewerken | brontekst bewerken]De meeste mutaties die optreden in het DNA zijn tijdelijk omdat ze snel worden gecorrigeerd door verschillende herstelmechanismen die ook wel DNA-reparatie worden genoemd. Van de tienduizenden mutaties die per dag optreden in een menselijke cel, raken slechts een zeer aantal (minder dan 0.02%) permanent ingesleten in de DNA-code. De rest wordt opmerkelijk efficiënt verholpen door reparatiemechanismen, waaronder base-excisie, nucleotide-excisie en homologe recombinatie.[29]
Tijdens base-excisie wordt een verkeerde stikstofbase uit het DNA geknipt door het enzym DNA-glycosylase, waarna de juiste base ingevoegd kan worden. Bij nucleotide-excisie wordt een klein deel van de DNA-streng rondom de mutatie weggeknipt uit de dubbelstrengse helix. Vervolgens vult DNA-polymerase het enkelstrengse gat op, waarbij het de onbeschadigde streng gebruikt als sjabloon.[29] Deze verschillende reparatiemechanismen zijn een belangrijk onderzoeksgebied in de moleculaire biologie, omdat ze van centraal belang zijn bij genetische manipulatie. Ook zijn de processen van DNA-reparatie een target bij chemotherapie tegen kanker.[30]
Aanpassing van DNA
[bewerken | brontekst bewerken]DNA kan kunstmatig aangepast worden, maar ook natuurlijk.
Kunstmatige aanpassing van DNA
[bewerken | brontekst bewerken]Tegenwoordig kan DNA kunstmatig aangepast worden door het te extraheren uit een cel en het op te kweken via PCR. Men kan dan proberen het DNA weer in te brengen. Dit wordt onder andere toegepast bij bacteriën en planten.
DNA kan ook in levende wezens aangepast worden door middel van gentherapie.
Natuurlijke aanpassing van DNA
[bewerken | brontekst bewerken]DNA wordt ook constant door de natuur aangepast, bijvoorbeeld door recombinatie/crossing-over. Een andere mogelijkheid waardoor het DNA aangepast kan worden is door mutatie, wat ook constant gebeurt in de natuur.
Individuele verschillen in het DNA
[bewerken | brontekst bewerken]
Hoewel individuen die tot één soort behoren in het algemeen hetzelfde aantal chromosomen hebben (er zijn uitzonderingen, zoals bij veldbeemdgras) en ook een zeer grote overeenkomst vertonen in hun exacte DNA-volgorde, zijn er tussen individuen van een soort naast de geslachtsverschillen ook altijd enige verschillen aantoonbaar, met name in bepaalde regionen van het chromosoom. Naast polymorfismen (de aan- of afwezigheid van bepaalde kenmerkende stukjes DNA) zijn er variabele regio's (microsatellieten) met lengtevariaties in repeterend DNA, ook wel junk-DNA genoemd, wat het een handig hulpmiddel maakt bij het identificeren van sporen (bijvoorbeeld bloed, sperma, haren) achtergelaten op delictplaatsen. Als men een verdachte heeft, kan men na onderzoek van het spoor en van het DNA van de verdachte nagenoeg met zekerheid zeggen of het spoor van de verdachte afkomstig was of niet.
Ook bij het bepalen van afstamming en bloedverwantschap kunnen deze variabele regio's van het DNA een grote rol spelen. De genetische vingerafdruk, een door mensen gemaakte analyse van de variabele regio's in het DNA, is voor ieder mens uniek mits er voldoende genetische merkers worden gebruikt. Klonen zijn met behulp van de DNA-techniek niet van elkaar te onderscheiden, voor eeneiige tweelingen kan er gekeken worden naar de minuscule verschillen in het DNA.[31][32]
Bij DNA-onderzoek wordt gewerkt met 11 variabele plekken op een genoom, 1 plek om te bepalen of het DNA-profiel van een man of een vrouw is en de overige 10 om het profiel te maken. Stel dat van elk van deze 10 plekken in het genoom er gemiddeld 10 varianten zijn in een populatie, dan is de kans om twee keer een willekeurig profiel aan te treffen 1 op 10 miljard. De kans dat twee willekeurige individuen hetzelfde DNA-profiel hebben, is daarmee dus verwaarloosbaar klein.
Geografische herkomst
[bewerken | brontekst bewerken]Voor het bepalen van geografische herkomst zijn verschillende methoden beschikbaar, die deels nog in ontwikkeling zijn. De eerste methode kijkt alleen naar het DNA van het Y-chromosoom (het mannelijk geslachtschromosoom). De tweede methode is gebaseerd op het mitochondriaal DNA. De derde en meest recente methode gaat uit van het autosomale DNA. Hierbij kijkt men naar eigenschappen van alle 22 niet geslachtsgebonden chromosomen. Daarbij wordt vooral gelet op specifieke eigenschappen van baseparen, zogenaamde SNP's (single nucleotide polymorphisms).[33] Via deze methode heeft men DNA-verschillen van bewoners van Europese landen in kaart kunnen brengen. Zo heeft de populatiegeneticus Spencer Wells[34] in zijn Genographic Project DNA van volken over de hele wereld verzameld. Dit project is een initiatief van computerbedrijf IBM en de National Geographic Society.[35] Hieraan kan een ieder deelnemen door zijn DNA met een wattenstaafje uit de wang te schrapen en naar het project op te sturen. Met deze methode probeert men menselijke migratiepatronen te reconstrueren op basis van het DNA van mensen die nu leven.[36]
DNA-databank
[bewerken | brontekst bewerken]Er zijn twee soorten DNA-databanken:
- Een bank waarin alle bekende sequenties (volgordes van basen in DNA) worden opgeslagen met de daarbij eventueel bekende functie. Hierdoor kunnen onderzoekers een door hen onderzocht stukje DNA vergelijken met alle reeds bekende sequenties.
- Databanken waarin DNA-profielen zijn opgeborgen om daders van misdrijven te kunnen identificeren, waaronder de DNA-databank voor strafzaken in Nederland.
DNA in de taxonomie
[bewerken | brontekst bewerken]DNA wordt tegenwoordig veel gebruikt in de systematiek. Het gaat dan in de eerste plaats om chloroplast-DNA bij planten en mitochondriaal DNA bij dieren. Volgens de endosymbiontentheorie is dit in beide gevallen afkomstig van prokaryoot DNA. Een praktische consequentie van deze nieuwe aanpak is het APG III-systeem (2009). Op grond van DNA-sequenties komt men vaak tot andere taxonomische indelingen dan op grond van uiterlijke kenmerken.
Maatschappelijke consequenties van DNA-onderzoek
[bewerken | brontekst bewerken]Het DNA-onderzoek heeft maatschappelijke consequenties, zowel op medisch vlak als op juridisch gebied.
Bij het forensisch onderzoek vormt het DNA-onderzoek een aanvulling op de vingerafdruk. DNA wordt onder andere aangetroffen in bloedsporen en in sperma. Met DNA is het ook mogelijk verwantschap en de etniciteit van de dader vast te stellen, wat met vingerafdrukken niet kan.
Soms wordt aan een groot aantal mensen gevraagd vrijwillig DNA af te staan om te helpen bij het vinden van de dader van een misdrijf. Ook als de dader zelf geen DNA heeft afgestaan, kan men vaststellen of de dader nauw verwant is met iemand die wel DNA heeft afgestaan.
Op die manier kunnen tegenwoordig cold cases alsnog worden opgelost en kunnen rechterlijke dwalingen ontdekt worden, waarbij onschuldigen werden veroordeeld.
Het aantreffen van DNA-materiaal levert niet zonder meer het bewijs van daderschap van degene van wie het DNA is aangetroffen, maar kan een duidelijke indicatie zijn.
Het gaat hier niet alleen om menselijk DNA. Als aan de kleding van een verdachte een boomblad is blijven hangen, dan kan wellicht worden vastgesteld dat dat blad afkomstig is van een boom die staat op de plek waar het delict is gepleegd, en dat is dan een indicatie dat de verdachte daar geweest is.
Doordat DNA-onderzoek steeds goedkoper wordt is het voor meer mensen mogelijk om verwantschappen vast te stellen, in het bijzonder door het vaststellen van vaderschap.
Synthetisch DNA
[bewerken | brontekst bewerken]Synthetisch DNA (SDNA) wordt toegepast in DNA-spray dat gebruikt wordt om voorwerpen te merken of om bij een misdrijf de dader te besproeien en daardoor herkenbaar te maken. Zo wordt bijvoorbeeld koper gemerkt om het na koperdiefstal, zelfs na omsmelten, nog te kunnen herkennen.[37]
Dit DNA wordt in een laboratorium gemaakt uit precies dezelfde bouwstenen A, T, G en C die ook in natuurlijk DNA voorkomen (zie boven). Een fragment synthetisch DNA bestaat uit tientallen baseparen in een bepaalde combinatie.
Geschiedenis
[bewerken | brontekst bewerken]DNA werd in 1869 ontdekt door de Zwitserse biochemicus Johann Friedrich Miescher (1844-1895). Hij wist de stof te zuiveren uit leukocyten (witte bloedcellen), die hij verkreeg uit pus, afkomstig van ziekenhuisafval.[38] De chemische structuur van DNA bleef nog lange tijd onbekend. In 1909 had Phoebus Levene de theorie opgesteld dat DNA uit vier nucleotiden bestond, en in 1919 publiceerde hij een hypothese voor de wijze waarop de nucleotiden onderling verbonden zijn in een nucleïnezuur.[39]
De natuurkundige Erwin Schrödinger publiceerde in 1944 een invloedrijk boek met de titel Was ist Leben? (Wat is leven?). In dit boek beredeneerde hij dat het erfelijke materiaal moest bestaan uit een aperiodiek kristal: een vaste stof met een regelmatige maar variabele structuur, die de code zou bevatten voor de ontwikkeling van organismen.[40]
Dat het DNA de drager van erfelijke eigenschappen is, werd duidelijk in 1952 door onderzoek van Alfred Hershey en Martha Chase. Zij toonden aan dat een virus, dat bestaat uit DNA (of het verwante RNA) en een eiwitmantel, alleen door middel van DNA een cel kon besmetten. Virussen worden niet gerekend tot de levende organismen. Een virus wordt vermenigvuldigd in een cel.
In 1951 stelde de scheikundige Linus Pauling een model op voor de structuur van DNA. Dit model ging ervan uit dat DNA de structuur had van een helix, maar bevatte op andere punten belangrijke onjuistheden.
In 1952 publiceerde de biochemicus Erwin Chargaff een belangrijke stelregel over de samenstelling van het DNA: dubbelstrengs DNA bevat evenveel adenine als thymine en evenveel cytosine als guanine. Deze regel werd een jaar later verklaard door het concept dat de dubbele helix is opgebouwd uit baseparen van enerzijds adenine en thymine, en anderzijds cytosine en guanine.
-
 Friedrich Miescher
Friedrich Miescher -
 Erwin Schrödinger
Erwin Schrödinger -
 Linus Carl Pauling
Linus Carl Pauling -
 Francis Crick
Francis Crick -
 James Dewey Watson
James Dewey Watson -
 Rosalind Elsie Franklin
Rosalind Elsie Franklin -
 Maurice Wilkins
Maurice Wilkins -
 Frederick Sanger
Frederick Sanger

.jpg)






De correcte chemische structuur van DNA is in 1953 bepaald door het onderzoek van James D. Watson, Francis Crick, Maurice Wilkins en Rosalind Franklin. Franklin deed onderzoek naar de structuur van DNA met behulp van de röntgendiffractietechniek. Een van haar opnamen kwam zonder haar medeweten via Wilkins onder ogen van Watson en Crick. De gegevens van Franklin hielpen Watson en Crick om de structuur van de dubbele helix te bepalen. Wilkins hielp Watson en Crick bij de verificatie van hun model. Watson en Crick publiceerden het artikel over de structuur van het DNA in het tijdschrift Nature op 25 april 1953. In hetzelfde nummer verschenen publicaties van Franklin en Wilkins over de structuur van het DNA. Een maand later publiceerden Watson en Crick op basis van deze structuur een model voor het mechanisme van de replicatie van DNA.[41] Watson, Crick en Wilkins kregen hiervoor in 1962 een Nobelprijs.[42] Franklin was toen al overleden aan kanker.
Francis Crick stelde in 1958 het centrale dogma van de moleculaire biologie op. Dit centrale dogma stelt dat informatie uit genen wél vertaald kan worden naar eiwitten, maar informatie van eiwitten nooit vertaald kan worden naar genen. Het vormde het kader voor de processen van transcriptie en translatie.
In 1975 publiceerde Frederick Sanger een methode voor het bepalen van de volgorde van nucleotiden in DNA. Deze methode, die sequencing wordt genoemd, werd een standaardmethode in de moleculaire biologie. DNA-sequenties werden steeds meer gebruikt om de verwantschap tussen organismen te bepalen. Van steeds meer organismen werd het gehele genoom gesequencet. Alec John Jeffreys ontdekte bij een onderzoek in september 1984 dat er kleine verschillen zichtbaar waren in het DNA van personen van eenzelfde familie en legde hiermee de basis voor DNA-fingerprinting. De techniek van de genetische vingerafdruk is een hulp bij forensisch onderzoek en DNA-onderzoek voor ouderschapstesten en afstammingsbepaling.
In 2001 werden de DNA-sequenties van het humane genoom gepubliceerd.
Zie ook
[bewerken | brontekst bewerken]- Archeogenetica
- Biofoton
- cDNA
- Chromatine-immunoprecipitatie
- DNA-extractie
- DNA-DNA-hybridisatie
- DNA-microarray
- DNA-polymerase
- Replicatie (DNA)
- Springend gen
- Matrijs (biologie)
- Urinezuur
Noten
- ↑ DNA is een afkorting van het Engelse deoxyribonucleic acid.
- ↑ Desoxyribose en fosfaat zijn verbonden via een zogeheten fosfodi-esterbinding. Onder fysiologische pH zijn de fosfodi-esters negatief geladen, waardoor het DNA een uitgesproken anionisch karakter heeft.
- ↑ Met name huidcellen die blootstaan aan zonlicht zijn gevoelig voor deze vorm van DNA-schade.
Referenties
- ↑ a b (en) Neidle S, Sanderson M. (2021). Principles of Nucleic Acid Structure, 2nd. Academic Press, "The building blocks of DNA and RNA", pp. 29-51. ISBN 978-0-12-819677-9.
- ↑ (en) Klug, A. (2004). The Discovery of the DNA Double Helix. Journal of Molecular Biology 335: 3-26. ISSN: 0022-2836. DOI: 10.1016/j.jmb.2003.11.015.
- ↑ (en) Kuryian et al, pp. 60–62.
- ↑ a b (en) Blanco A, Blanco G. (2022). Medical Biochemistry, 2nd. Academic Press, "Nucleic acids", pp. 131-152. ISBN 978-0-323-91599-1.
- ↑ a b c d (en) Alberts et al, pp. 175–179.
- ↑ (en) Forsdyke DR. (1995). Sense in antisense?. Journal of Molecular Evolution 41: 582-586. DOI: 10.1007/BF00175816. Gearchiveerd van origineel op 22 maart 2023.
- ↑ (en) Seeman NC. (2003). DNA in a material world. Nature 421: 427-431. DOI: 10.1038/nature01406.
- ↑ (nl) Schuit F, pp. 158–161.
- ↑ (en) Privalov PL, Dragan AI, Crane-Robinson C, Remeta DP. (2007). What Drives Proteins into the Major or Minor Grooves of DNA?. Journal of Molecular Biology: 1–9. DOI: 10.1016/j.jmb.2006.09.059. Gearchiveerd van origineel op 12 oktober 2022.
- ↑ (en) Piovesan A, Pelleri MC, Antonaros F, Vitale L. (2019). On the length, weight and GC content of the human genome. BMC Research Notes 12 (106). DOI: 10.1186/s13104-019-4137-z.
- ↑ (en) Travers A, Muskhelishvili G. (2015). DNA structure and function. The FEBS journal 282 (12): 2279-2295. DOI: 10.1111/febs.13307.
- ↑ (en) Zhao J, Bacolla A, Wang G, Vasquez KM. (2010). Non-B DNA structure-induced genetic instability and evolution. Cellular and Molecular Life Sciences: 43–62. DOI: 10.1007/s00018-009-0131-2.
- ↑ (en) Ma J, Wang MD. (2016). DNA supercoiling during transcription. Biophysical Reviews 8: 75–87. DOI: 10.1007/s12551-016-0215-9.
- ↑ (en) Bush NG, Evan-Roberts K, Maxwell A. (2015). DNA Topoisomerases. EcoSal Plus 6: ecosalplus.ESP–0010–2014. DOI: 10.1128/ecosalplus.ESP-0010-2014.
- ↑ (en) Burge S, Parkinson GN, Hazel P, Todd AK, Neidle S (2006). Quadruplex DNA: sequence, topology and structure. Nucleic Acids Research 34 (19): 5402–15. DOI: 10.1093/nar/gkl655.
- ↑ (en) Kosiol N, Juranek S, Brossart P, Heine A, Paeschke K. (2021). G-quadruplexes: a promising target for cancer therapy. Molecular Cancer 20 (40). DOI: 10.1186/s12943-021-01328-4.
- ↑ (en) Hearn RP, Arblaster KE. (2010). DNA extraction techniques for use in education. Biochemistry and Molecular Biology Education 38 (3): 161-166. DOI: 10.1002/bmb.20351.
- ↑ (en) Lesk AM. (2012). Introduction to genomics, 2nd. Oxford University Press, "Chapter 1: Introduction to Genomics". ISBN 978-0-19-956435-4.
- ↑ (en) Wittkopp PJ, Kalay G. (2012). Cis-regulatory elements: molecular mechanisms and evolutionary processes underlying divergence. Nature Reviews Genetics: 59–69. DOI: 10.1038/nrg3095.
- ↑ a b c (en) Alberts et al, pp. 4–7
- ↑ (en) Alexander RP, Fang G, Rozowsky J, Snyder M, Gerstein MB. (2010). Annotating non-coding regions of the genome. Nature Reviews Genetics: 559–571. DOI: 10.1038/nrg2814.
- ↑ (en) Shyu A, Wilkinson MF, Hoof A. (2008). Messenger RNA regulation: to translate or to degrade. The EMBO Journal: 471–481. DOI: 10.1038/sj.emboj.7601977.
- ↑ a b (en) Bell SP, Dutta A. (2002). DNA Replication in Eukaryotic Cells. Annual Review of Biochemistry 71: 333-374.
- ↑ (en) Beard WA, Wilson SH. (2003). Structural Insights into the Origins of DNA Polymerase Fidelity. Structure 11 (5): 489-496. DOI: 10.1016/S0969-2126(03)00051-0.
- ↑ a b (en) Leonard AC, Méchali M. (2013). DNA Replication Origins. Cold Spring Harbor 5 (10). DOI: 10.1101/cshperspect.a010116.
- ↑ (en) Alberts et al, pp. 284–295.
- ↑ (en) Dizdaroglu M, Jaruga P. (2012). Mechanisms of free radical-induced damage to DNA. Free Radical Research 46 (4): 382-419. DOI: 10.3109/10715762.2011.653969.
- ↑ (en) Strekowski L, Wilson B. (2007). Noncovalent interactions with DNA: An overview. Mutation Research. DOI: 10.1016/j.mrfmmm.2007.03.008.
- ↑ a b (en) Alberts et al. pp. 284–295.
- ↑ (en) Li L, Guan Y, Cheng Y. (2021). DNA Repair Pathways in Cancer Therapy and Resistance. Frontiers in Pharmacology 11. DOI: 10.3389/fphar.2020.629266.
- ↑ (en) Jonsson, Hakon, Magnusdottir, Erna, Eggertsson, Hannes P., Stefansson, Olafur A., Arnadottir, Gudny A. (2021-01). Differences between germline genomes of monozygotic twins. Nature Genetics 53 (1): 27–34. ISSN:1546-1718. DOI:10.1038/s41588-020-00755-1.
- ↑ Uniek dna-onderzoek naar tweeling moet verdachte in zedenzaak aanwijzen. nos.nl (10 oktober 2022). Geraadpleegd op 21 juli 2023.
- ↑ NRC Wetenschap, 9-10 Augustus 2008, Current Biology 18, 1–8, 26 augustus 2008
- ↑ Spencer Wells, The Journey of Man: A Genetic Odyssey, (2002). Random House, ISBN 0-8129-7146-9
- ↑ https://web.archive.org/web/20110217214203/http://www.nationalgeographic.com/xpeditions/lessons/09/g912/genographic2.html
- ↑ The Genographic Project Public Participation Mitochondrial DNA Database. PloS Genetics. June 2007 | Volume 3 | Issue 6
- ↑ SDNA
- ↑ Friedrich Miescher and the discovery of DNA. Dahm R. Developmental Biology, 15 feb 2005; 278(2):274-88 (Pubmed). Gearchiveerd op 2 mei 2019.
- ↑ The structure of yeast nucleic acid Levene P.A. Journal of Biological Chemistry, 1919; 40 (2): 415 (gearchiveerd)
- ↑ De tekst van What is Life?
- ↑ de publicaties van Watson, Crick, Wilkins en Franklin
- ↑ Vermelding op nobelprize.org
Literatuur
- (en) Alberts, B. (2015). Molecular Biology of The Cell, 6th edition. Garland Science, "Chapter 4: DNA, Chromosomes and Genomes". ISBN 978-0-8153-4464-3.
- (nl) Prinsen J, Van der Leij F.. De bouwstenen van het leven. Wageningen Academic Publishers. ISBN 978-90-8686-270-2.
- (en) Campbell, N. (2017). Biology: A Global Approach, 11th edition. Pearson Education, "Chapter 16: Nucleic Acids and Inheritance". ISBN 978-1-292-17043-5.
- (nl) Schuit, F.C (2000). Medische biochemie. Bohn Stafleu Van Loghum, Houten, "Hoofdstuk 6: Nucleïnezuren". ISBN 90-313-3020-5.
- (en) Kuriyan, J. Konforti, B. & Wemmer, D. (2013). The Molecules of Life. Garland Science, "Chapter 2: Nucleic Acid Structure". ISBN 978-0-8153-4188-8.
- (en) Berg, J. (2015). Biochemistry, 8th edition. W. H. Freeman and Company. ISBN 978-1-4641-2610-9.