検索エンジンに優しいデザインの基本 - 『検索エンジン最適化の初心者ガイド』改訂版#4-1


この記事は、『検索エンジン最適化の初心者ガイド』をセクションごとに書き直していく過程のエントリだ。この構想については、概要を見てもらえば、もっとよくわかるだろう。
検索エンジンというものは、ウェブを巡回しながらコンテンツを解釈して抽出し、それを検索結果として表示するわけだが、前回指摘したとおり、その能力にはまだ限界がある。このセクションでは、検索エンジンにとっても人間の訪問者にとっても最適な構造を持つウェブページの制作(および修正)方法について、技術的側面に焦点を絞って解説しよう。
サイトの構築に関わるすべての人が検索エンジンに優しいサイトを立案し開発できるように、プログラマや情報アーキテクト、デザイナなどとこの情報を共有してほしい。
インデックス化可能なコンテンツ
検索エンジンのリストに取り入れられるには、コンテンツ、つまりサイトの訪問者に提供される素材がHTML形式のテキストでなければならない。クロール技術が進歩したとはいえ、検索エンジンのスパイダ(自動巡回ロボット)は、FlashファイルやJavaアプレットなどの非テキストコンテンツを、まず認識できない。訪問者が見ている言葉を検索エンジンにも見てもらうためには、ページのHTMLテキスト部分にその言葉を入れるのがいちばん簡単なやり方だ。しかし、洗練されたページレイアウトやビジュアルデザインが必要なら、もっと高度な手法がある。
- GIF、JPEG、PNG形式の画像は、HTMLで「alt属性」を指定すれば、検索エンジンに画像コンテンツの内容をテキストで伝えることができる。
- CSSによるスタイル指定を利用すると、検索エンジンにはテキストとして理解させ、人間の訪問者にはそれを画像に置き換えて見せることもできる。
- FlashやJavaプラグインに含まれているコンテンツは、同じ内容を同一ページ内にテキストとしても配置しておけば検索エンジンが理解できる。
- ビデオや音声コンテンツに含まれる語句を検索エンジンにインデックス化させたいなら、トランスクリプト(字幕テキスト)を添付しておこう。
インデックス化可能なコンテンツについて大きな問題を抱えているサイトはあまり多くないけれども、念のためチェックしておいた方がいいだろう。SEO-Browserのような、ウェブページが検索エンジンのスパイダーからどう見えるかを確認できるツールを使えば、検索エンジンにとってどの要素が認識可能でインデックス化できるか点検できる。
例を挙げてみよう。次の画像はSEOmozのホームページだ。

シアトルのシルエット画像をはじめとするグラフィックスのおかげで見た目がグッと良くなっているけど、検索エンジンはこのページをどう見ているんだろう。

SEO-Browserのサイトで見ると、検索エンジンにとって、SEOmozのホームページはただのテキストとリンクの集まりだ(僕らの狙いどおりだ)。
では次に、僕の好きなウェブサイトから、かっこよくデザインされたFlashベースのゲームを集めたOrisinalというページを調べてみよう。
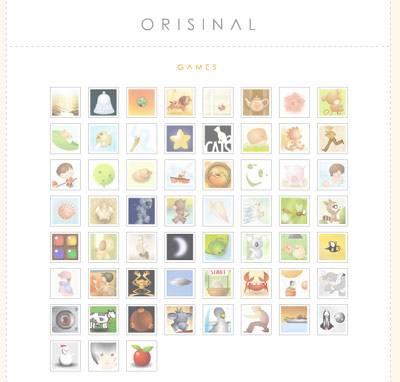
グラフィックスはすごいけど、ページにテキストはあまりない。「Orisinal games」とあるだけだ。ページのランクに反映させたいのはこれだけなのだろうか?
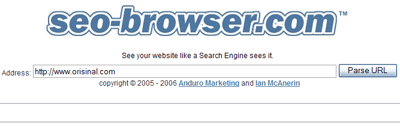
う〜ん……。SEO-Browserで見ると、このページは、何も内容がない不毛な荒野じゃないか。ここには、Orisinalのゲームがあるということを伝えるテキストもない。残念なことに、サイトが全部Flashでできているせいで、検索エンジンがインデックス化できるテキストコンテンツはない。それどころか、個々のゲームへのリンクをインデックス化することさえできない。
検索エンジンがウェブページ内のどんな語句に注目しているのか正確に知りたければ、SEOmozで「Term Extractor」という便利なツールを提供している。これは出現頻度別に語句を表示させるツールだ。ただし、テキストコンテンツをチェックするだけじゃなく、SEO-Browserなどのツールで制作中のページが検索エンジンからもきちんと見えることをダブルチェックしておく方が賢明だ。キーワードのデータベースに載ってないんじゃあ、ランクに入るのは夢のまた夢だからね(笑)。
クロール可能なリンク構造
ページを膨大なキーワードベースのインデックスに登録するために、検索エンジンは各ページのコンテンツを認識する必要がある。加えて、ウェブサイト内にあるすべてのページを見つけ出すために、各ページ間のつながりが明確にわかる、クロール可能なリンク構造も必要だ。サイトのナビゲーションが隠れていたりわかりにくかったりして、検索エンジンにアクセスしてもらえず、そのせいで検索エンジンのインデックスに登録されていないサイトが数知れずある。これは致命的な過ちだ。どうしてそうなってしまうのか、解説しよう。

上の図では、Googleのカラフルなスパイダがページ「A」まで来て、ページ「B」と「E」へのリンクを発見している。ところが、「C」と「D」は、サイト内で重要なページかもしれないのに、スパイダにアクセスしてもらえない(というか、その存在すら認識されていない)。このページに直接つながるクロール可能なリンクがないからだ。Googleにとって、このページはないも同然だ。すばらしいコンテンツも、キーワードへの的確なターゲッティングも巧みなマーケティングも、そもそもスパイダがそのページにアクセスできなければ、何の意味もない。
まず、通常のHTMLリンクの構成をさっと見ておこう。

上の図の各パーツを解説しよう。
- 「<a」というタグがリンクの始点を示している。リンクタグは、画像やテキストなどのオブジェクトを要素として含むことができるが、どの場合でも、訪問者を別のページに導く「クリック可能な」領域がページ上に生じることになる。これがインターネット独自の概念「ハイパーリンク」だ。
- リンク参照先の場所はブラウザ(および検索エンジン)にリンクの飛び先を示すものだ。この例では、URLのhttp://www.jonwye.comを参照している。
- 次に来るのは訪問者に見える部分で、SEO業界では「アンカーテキスト」と呼ばれており、リンク先を説明するテキストになっている。ここでは、リンク先はワシントンD.C.に住む僕の友人Jon Wyeが運営しているサイトで、オリジナルのベルトを販売している。だから、「Jon Wye's Custom Designed Belts(Jon Wyeのオリジナルベルト)」というアンカーテキストにした。
- </a>というタグでリンクを終了、これ以降のページ内要素にリンク属性が及ばないようにしている。
これはリンクのもっとも基本的な形式で、検索エンジンにもたやすく理解できる。スパイダーは、このリンクを検索エンジンが持っているウェブのリンクグラフに追加すべきであると判断するとともに、(GoogleのPageRankのような)検索に依存しない変数を算出するのに使用し、さらにこのリンクをたどって参照先のコンテンツをインデックス化する。
では、どうして検索エンジンがページに到達できなくなるか、よくある理由を見てみよう。
- フォームの送信が必要なリンク
フォームには、ドロップダウンメニューだけの基本的なものから本格的な調査に使える複雑なものまでさまざまある。どちらにしても、検索スパイダーはフォームを「送信」しようとはしないため、検索エンジンはフォーム経由でアクセスするコンテンツやリンクを認識しない。 - 検索しないとアクセスできないリンク
前述のフォームに関する注意にも直接関連しているが、非常によくある問題点なので、ここでも指摘させてもらう。スパイダーは自分で検索してコンテンツを探そうとはしない。そのせいで、まったくアクセス不能な壁の向こうに隠れてしまっているページは膨大な数にのぼると予想される。こういったページは、スパイダーがそのページにリンクしているページを発見しない限り、そのまま埋もれてしまう運命にある。 - 解析不能なJavaScript内のリンク
JavaScriptを利用してリンクを生成している場合、検索エンジンは埋め込まれたリンクをクロールしないか、またはそのリンクにほんの少ししかウェイトを与えない。スパイダーにクロールさせるためのページを1つ用意して、そのページ内ではJavaScriptの代わりに標準のHTMLリンクを使用(あるいは両者を併用)すべきだ。 - FlashやJavaなどのプラグインに埋め込まれたリンク
さっき例にあげたOrisinalのサイトに埋め込まれたリンクがいい例だ。Orisinalのページには何十個ものゲームが並び、リンクも貼られているが、このサイトのリンク構造では、スパイダーがゲームに到達できないので、検索エンジンから認識してもらえない(だから検索結果に表れることもない)。 - meta robotsタグやrobots.txtでブロックされたページを参照しているリンク
サイトオーナーはmeta robotsタグ(Google Webmaster Centralブログの詳しい解説(英語)、英語ほど詳しくないが日本語のGoogleヘルプ)とrobots.txtファイル(詳しくはGoogleサイトマップブログのrobots.txtの記事を参照、英語ほど詳しくないがこちらも日本語のGoogleヘルプがある)を利用して、スパイダーがページにアクセスするのを制限できる。1つ警告しておこう。好ましくないロボットのアクセスをブロックするために、多くのウェブマスターが両者を使っているが、意図せずして検索エンジンのクロールを止めてしまうという結果になっている。 - 大量のリンクを詰め込んだページ内のリンク
どの検索エンジンも、リンクは1ページあたり100件までというおおまかな制限があり、それを超えた分については、リンク先のページをクロールしない可能性がある。この制限にはある程度の柔軟性があって、非常に重要なページならリンクが150〜200件あってもちゃんとたどってくれる。しかし、一般的なやり方としては、1ページあたりのリンクを100件以下に抑えるのが賢明だ。そうしないと101件目以降のページはクロールされなくなってしまう危険がある。 - フレームまたはインラインフレーム内のリンク
技術的には、フレームやインラインフレーム内部のリンクもクロール可能だが、どちらもリンクをインデックス化したりたどったりする際に、検索エンジンにとって構造的な問題を生じる。検索エンジンがフレーム内リンクをどうインデックス化してたどっていくか、技術的によく理解している上級ユーザーでなければ、クロール目的のリンクをフレーム内に置くのは避ける方が無難だ。
こういった落とし穴を避ければ、HTMLリンクがすっきりしたクロール可能なものになり、スパイダーがコンテンツのあるページにたやすくアクセスできるようになる。リンクタグにはいろいろな属性を加えることもできるが、検索エンジンは「rel="nofollow"」という重要な属性を除いて、すべてを無視する。
「rel="nofollow"」は次のような書式で使用する。
<a href="http://www.seomoz.org" rel="nofollow">最低なたわごと!</a>
この例では、リンクタグに「rel="nofollow"」という属性を付け加えることで、サイト所有者である僕は、検索エンジンにこのリンクを通常の「支持票」として解釈してもらいたくないことを伝えている。nofollowは、ブログコメントやゲストブックへの自動入力やリンクスパムを防ぐ手段として生まれた(誕生についてはSEWの記事を参照、日本語の記事はINTERNET Watchにあった)が、時が経つとともに、通常なら渡されるリンクの価値を検索エンジンに少なく評価させる方法として使われるようになった。nofollowのあるリンクタグは、検索エンジンによって解釈が微妙に違う。
- Google――nofollowの付いたリンクはウェイトや影響力がなくなり、HTMLテキストとして(リンクが存在しないかのごとく)解釈される。Googleの関係者によると、nofollowのあるリンクはウェブのリンクグラフにも登録されないという。
- Yahoo!とMSN/Live――双方ともnofollowの付いたリンクについて、検索結果やランキングには影響しないが、新規ページを見つける手段としてスパイダーが使うこともある、と言っている。つまり、リンクはたどる「かもしれない」けど、ランキングを上げる要素にはならない。
- Ask.com――Askの見解は独特だ。nofollowのリンクの扱いは他のリンクと違わない。Askは、(大域的な人気ではなく局所的な人気をベースとする)Askのアルゴリズムにとって、nofollowで解決しようとしている問題のほとんどはすでに解決済みだという立場を明らかにしている。
キーワードの使用法とターゲティング
これは次回にとっておこうか……。
注:Flash内のリンクを検索エンジンにクロールさせることも可能だが、そのためにはsIFR(Scalable Inman Flash Replacement)と呼ばれる独創的なコード置換技術が必要になる。この技術はFlash内のテキストを訪問者に見えるようにすると同時に、検索エンジンにはHTMLを認識させるためのものだ。
」とは?(後編)")




この記事は、Daily SEOmoz Blog に掲載された以下の記事を日本語訳したものです。
原文:「Rewriting the Beginner's Guide: Part 4 - The Basics of Search Engine Friendly Design & Development」 by randfish (2007/12/13 01:58 PST)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

コメント
こちらというアンカーテキストがたくさんあ...
>(ここに詳しい解説がある。英語ほど詳しくないがこちらに日本語がある)とrobots.txtファイル(詳しくはここを参照。英語ほど詳しくないがこちらに日本語がある)
こういうリンクがユーザビリティ、アクセシビリティのうえで問題であることは、このコメントで自明(テキストをコピペしただけ、あるいは印刷した場合などに意味不明になる)ですが、SEOのうえでも問題ではないですか?検索エンジンはアンカーテキストを重視するのでしょう?
それだけでなく、文章の質までも落とすことになると思います。
>この例では、リンクタグに「rel="nofollow"」という属性を付け加えることで、サイト所有者である僕は、検索エンジンにこのリンクを通常の「支持票」として解釈してもらいたくないことを伝えている。nofollowは、ブログコメントやゲストブックへの自動入力やリンクスパムを防ぐ手段として生まれた(誕生についてはこちらを参照、日本語はこちら)
上記引用箇所には「この例」「このリンク」「こちら」「日本語はこちら」という、いわゆる「こちらリンク」に見える箇所がありますが、実際にリンクになっているのは最後の2つだけです。こちらリンクを使ってしまうと、文章中に自然と出てくるこれらの指示代名詞の信頼が低下します。その「こちら」は本来リンクだったのか、単なる指示代名詞なのか。
なぜ素直にリンク先のtitle要素をアンカーテキストにしないのですか?
Re: こちらというアンカーテキストがたくさん...
編集部の安田です。
ご指摘に感謝。おっしゃることはそのとおりなので、記事本文の「こちら」などのアンカーテキストを修正しました。
ちなみに、なぜ元のようになったか、それは原文がブログ記事だからです。RandはSEOのために文章を書いているのではなく、ブラウザでSEOmozのブログを読む読者のために記事を書いているので、「こちら(here)」のようなアンカーテキストでも見てわかるからですね。そういう意味では、HTML validatorの類はあの表記を指摘しますが、実際にはブラウザでみるぶんには問題ないと思っています。
また、この場合、「アンカーテキストがSEOに関係する」というのは、筆者にとってテキストを綴るうえでまったく考慮すべき要因ではありません。外部リンクのアンカーテキストであることもそうですし、そもそもSEOのために書いている記事ではないので。
ちなみに、現時点では編集部でもテキストをコピー&ペーストした場合や印刷ビューのための編集はしていないことはご承知ください。あくまでも記事をブラウザで読む読者のための編集をしています(雑誌に掲載される場合は雑誌向け編集をしていますが)。そのためのサイトですし、そのために記事を作っていますので(印刷ビューはその次の段階として考慮すべきだとは思っています)。