 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Multiview Point Cloud Registration with Two-stage Candidate Retrieval
Jul 10, 2024Multiview point cloud registration serves as a cornerstone of various computer vision tasks. Previous approaches typically adhere to a global paradigm, where a pose graph is initially constructed followed by motion synchronization to determine the absolute pose. However, this separated approach may not fully leverage the characteristics of multiview registration and might struggle with low-overlap scenarios. In this paper, we propose an incremental multiview point cloud registration method that progressively registers all scans to a growing meta-shape. To determine the incremental ordering, we employ a two-stage coarse-to-fine strategy for point cloud candidate retrieval. The first stage involves the coarse selection of scans based on neighbor fusion-enhanced global aggregation features, while the second stage further reranks candidates through geometric-based matching. Additionally, we apply a transformation averaging technique to mitigate accumulated errors during the registration process. Finally, we utilize a Reservoir sampling-based technique to address density variance issues while reducing computational load. Comprehensive experimental results across various benchmarks validate the effectiveness and generalization of our approach.
Ultrasound Nodule Segmentation Using Asymmetric Learning with Simple Clinical Annotation
Apr 23, 2024


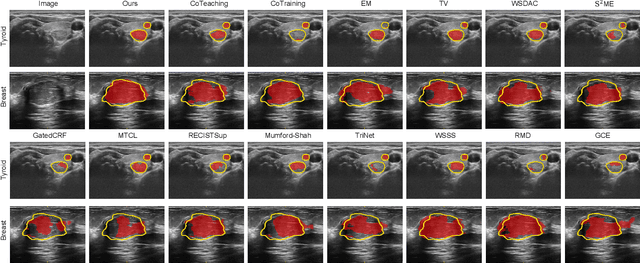
Recent advances in deep learning have greatly facilitated the automated segmentation of ultrasound images, which is essential for nodule morphological analysis. Nevertheless, most existing methods depend on extensive and precise annotations by domain experts, which are labor-intensive and time-consuming. In this study, we suggest using simple aspect ratio annotations directly from ultrasound clinical diagnoses for automated nodule segmentation. Especially, an asymmetric learning framework is developed by extending the aspect ratio annotations with two types of pseudo labels, i.e., conservative labels and radical labels, to train two asymmetric segmentation networks simultaneously. Subsequently, a conservative-radical-balance strategy (CRBS) strategy is proposed to complementally combine radical and conservative labels. An inconsistency-aware dynamically mixed pseudo-labels supervision (IDMPS) module is introduced to address the challenges of over-segmentation and under-segmentation caused by the two types of labels. To further leverage the spatial prior knowledge provided by clinical annotations, we also present a novel loss function namely the clinical anatomy prior loss. Extensive experiments on two clinically collected ultrasound datasets (thyroid and breast) demonstrate the superior performance of our proposed method, which can achieve comparable and even better performance than fully supervised methods using ground truth annotations.
Watch Your Head: Assembling Projection Heads to Save the Reliability of Federated Models
Feb 26, 2024Federated learning encounters substantial challenges with heterogeneous data, leading to performance degradation and convergence issues. While considerable progress has been achieved in mitigating such an impact, the reliability aspect of federated models has been largely disregarded. In this study, we conduct extensive experiments to investigate the reliability of both generic and personalized federated models. Our exploration uncovers a significant finding: \textbf{federated models exhibit unreliability when faced with heterogeneous data}, demonstrating poor calibration on in-distribution test data and low uncertainty levels on out-of-distribution data. This unreliability is primarily attributed to the presence of biased projection heads, which introduce miscalibration into the federated models. Inspired by this observation, we propose the "Assembled Projection Heads" (APH) method for enhancing the reliability of federated models. By treating the existing projection head parameters as priors, APH randomly samples multiple initialized parameters of projection heads from the prior and further performs targeted fine-tuning on locally available data under varying learning rates. Such a head ensemble introduces parameter diversity into the deterministic model, eliminating the bias and producing reliable predictions via head averaging. We evaluate the effectiveness of the proposed APH method across three prominent federated benchmarks. Experimental results validate the efficacy of APH in model calibration and uncertainty estimation. Notably, APH can be seamlessly integrated into various federated approaches but only requires less than 30\% additional computation cost for 100$\times$ inferences within large models.
Iterative Feedback Network for Unsupervised Point Cloud Registration
Jan 09, 2024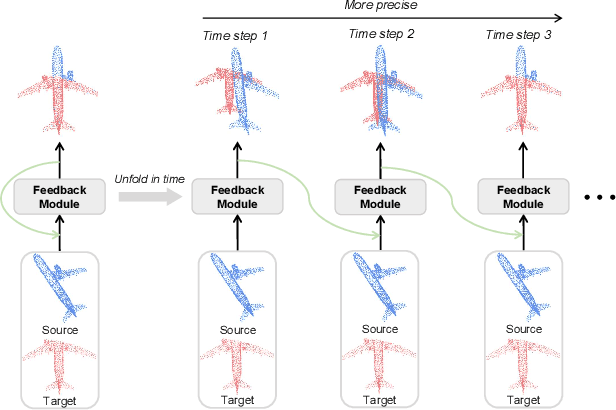
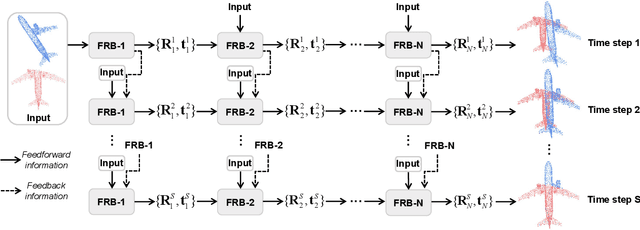
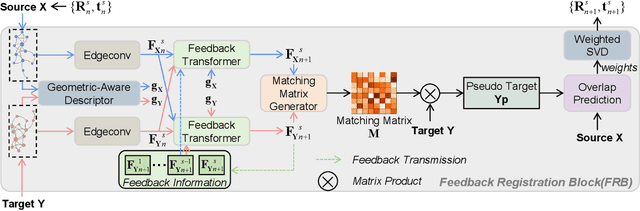
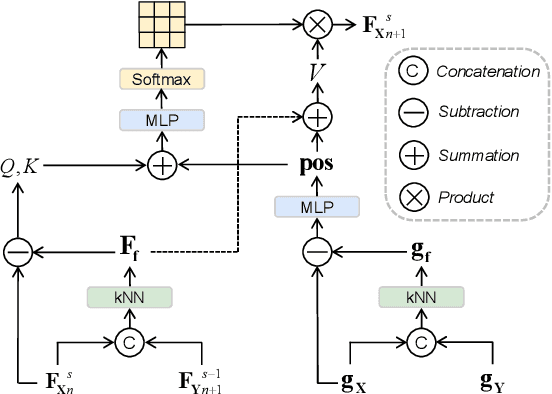
As a fundamental problem in computer vision, point cloud registration aims to seek the optimal transformation for aligning a pair of point clouds. In most existing methods, the information flows are usually forward transferring, thus lacking the guidance from high-level information to low-level information. Besides, excessive high-level information may be overly redundant, and directly using it may conflict with the original low-level information. In this paper, we propose a novel Iterative Feedback Network (IFNet) for unsupervised point cloud registration, in which the representation of low-level features is efficiently enriched by rerouting subsequent high-level features. Specifically, our IFNet is built upon a series of Feedback Registration Block (FRB) modules, with each module responsible for generating the feedforward rigid transformation and feedback high-level features. These FRB modules are cascaded and recurrently unfolded over time. Further, the Feedback Transformer is designed to efficiently select relevant information from feedback high-level features, which is utilized to refine the low-level features. What's more, we incorporate a geometry-awareness descriptor to empower the network for making full use of most geometric information, which leads to more precise registration results. Extensive experiments on various benchmark datasets demonstrate the superior registration performance of our IFNet.
Unsupervised Temporal Action Localization via Self-paced Incremental Learning
Dec 12, 2023Recently, temporal action localization (TAL) has garnered significant interest in information retrieval community. However, existing supervised/weakly supervised methods are heavily dependent on extensive labeled temporal boundaries and action categories, which is labor-intensive and time-consuming. Although some unsupervised methods have utilized the ``iteratively clustering and localization'' paradigm for TAL, they still suffer from two pivotal impediments: 1) unsatisfactory video clustering confidence, and 2) unreliable video pseudolabels for model training. To address these limitations, we present a novel self-paced incremental learning model to enhance clustering and localization training simultaneously, thereby facilitating more effective unsupervised TAL. Concretely, we improve the clustering confidence through exploring the contextual feature-robust visual information. Thereafter, we design two (constant- and variable- speed) incremental instance learning strategies for easy-to-hard model training, thus ensuring the reliability of these video pseudolabels and further improving overall localization performance. Extensive experiments on two public datasets have substantiated the superiority of our model over several state-of-the-art competitors.
Towards Fast and Stable Federated Learning: Confronting Heterogeneity via Knowledge Anchor
Dec 05, 2023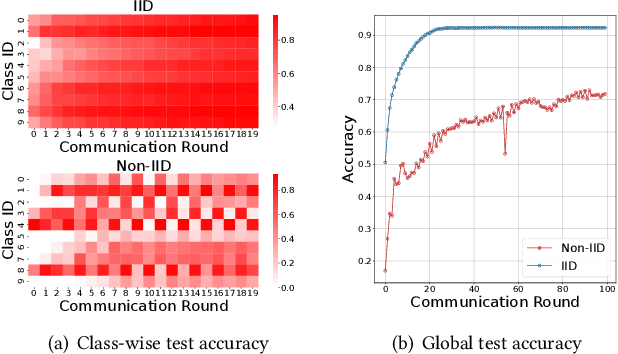
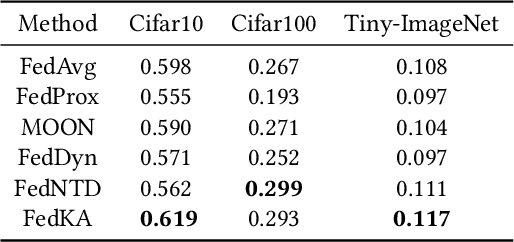
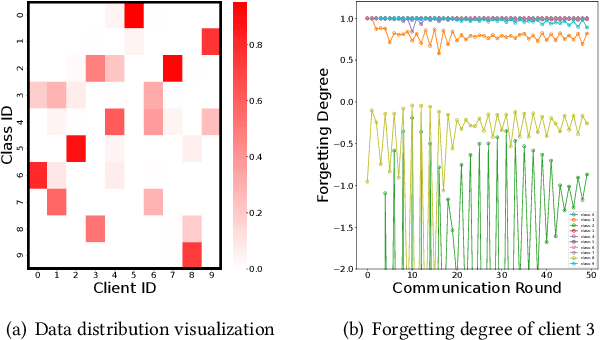
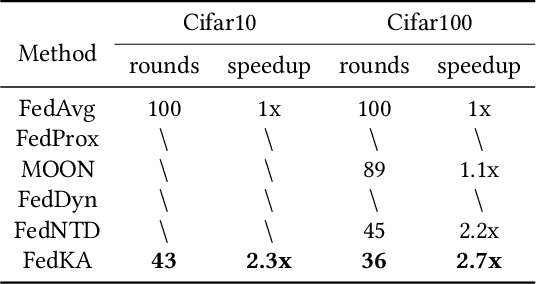
Federated learning encounters a critical challenge of data heterogeneity, adversely affecting the performance and convergence of the federated model. Various approaches have been proposed to address this issue, yet their effectiveness is still limited. Recent studies have revealed that the federated model suffers severe forgetting in local training, leading to global forgetting and performance degradation. Although the analysis provides valuable insights, a comprehensive understanding of the vulnerable classes and their impact factors is yet to be established. In this paper, we aim to bridge this gap by systematically analyzing the forgetting degree of each class during local training across different communication rounds. Our observations are: (1) Both missing and non-dominant classes suffer similar severe forgetting during local training, while dominant classes show improvement in performance. (2) When dynamically reducing the sample size of a dominant class, catastrophic forgetting occurs abruptly when the proportion of its samples is below a certain threshold, indicating that the local model struggles to leverage a few samples of a specific class effectively to prevent forgetting. Motivated by these findings, we propose a novel and straightforward algorithm called Federated Knowledge Anchor (FedKA). Assuming that all clients have a single shared sample for each class, the knowledge anchor is constructed before each local training stage by extracting shared samples for missing classes and randomly selecting one sample per class for non-dominant classes. The knowledge anchor is then utilized to correct the gradient of each mini-batch towards the direction of preserving the knowledge of the missing and non-dominant classes. Extensive experimental results demonstrate that our proposed FedKA achieves fast and stable convergence, significantly improving accuracy on popular benchmarks.
Cross-Modal Information-Guided Network using Contrastive Learning for Point Cloud Registration
Nov 02, 2023The majority of point cloud registration methods currently rely on extracting features from points. However, these methods are limited by their dependence on information obtained from a single modality of points, which can result in deficiencies such as inadequate perception of global features and a lack of texture information. Actually, humans can employ visual information learned from 2D images to comprehend the 3D world. Based on this fact, we present a novel Cross-Modal Information-Guided Network (CMIGNet), which obtains global shape perception through cross-modal information to achieve precise and robust point cloud registration. Specifically, we first incorporate the projected images from the point clouds and fuse the cross-modal features using the attention mechanism. Furthermore, we employ two contrastive learning strategies, namely overlapping contrastive learning and cross-modal contrastive learning. The former focuses on features in overlapping regions, while the latter emphasizes the correspondences between 2D and 3D features. Finally, we propose a mask prediction module to identify keypoints in the point clouds. Extensive experiments on several benchmark datasets demonstrate that our network achieves superior registration performance.
DBDNet:Partial-to-Partial Point Cloud Registration with Dual Branches Decoupling
Oct 18, 2023Point cloud registration plays a crucial role in various computer vision tasks, and usually demands the resolution of partial overlap registration in practice. Most existing methods perform a serial calculation of rotation and translation, while jointly predicting overlap during registration, this coupling tends to degenerate the registration performance. In this paper, we propose an effective registration method with dual branches decoupling for partial-to-partial registration, dubbed as DBDNet. Specifically, we introduce a dual branches structure to eliminate mutual interference error between rotation and translation by separately creating two individual correspondence matrices. For partial-to-partial registration, we consider overlap prediction as a preordering task before the registration procedure. Accordingly, we present an overlap predictor that benefits from explicit feature interaction, which is achieved by the powerful attention mechanism to accurately predict pointwise masks. Furthermore, we design a multi-resolution feature extraction network to capture both local and global patterns thus enhancing both overlap prediction and registration module. Experimental results on both synthetic and real datasets validate the effectiveness of our proposed method.
VITS-based Singing Voice Conversion System with DSPGAN post-processing for SVCC2023
Oct 08, 2023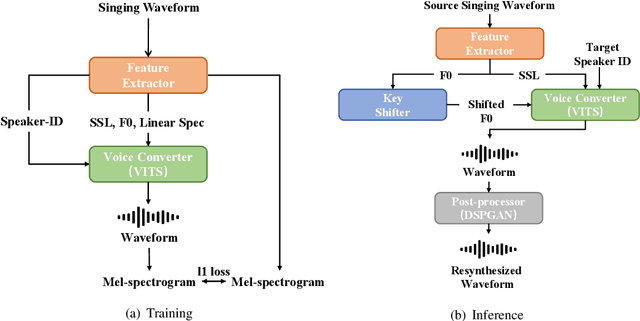
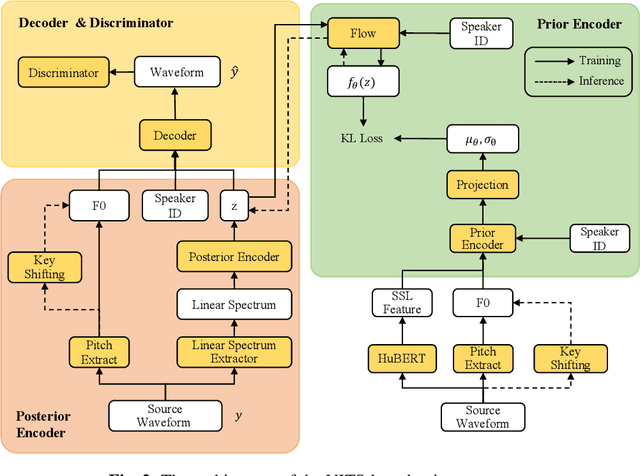
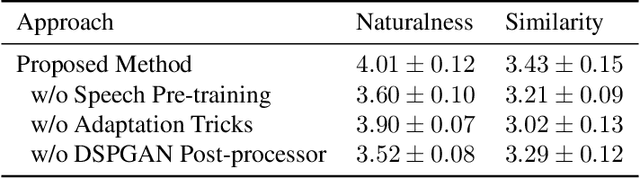
This paper presents the T02 team's system for the Singing Voice Conversion Challenge 2023 (SVCC2023). Our system entails a VITS-based SVC model, incorporating three modules: a feature extractor, a voice converter, and a post-processor. Specifically, the feature extractor provides F0 contours and extracts speaker-independent linguistic content from the input singing voice by leveraging a HuBERT model. The voice converter is employed to recompose the speaker timbre, F0, and linguistic content to generate the waveform of the target speaker. Besides, to further improve the audio quality, a fine-tuned DSPGAN vocoder is introduced to re-synthesise the waveform. Given the limited target speaker data, we utilize a two-stage training strategy to adapt the base model to the target speaker. During model adaptation, several tricks, such as data augmentation and joint training with auxiliary singer data, are involved. Official challenge results show that our system achieves superior performance, especially in the cross-domain task, ranking 1st and 2nd in naturalness and similarity, respectively. Further ablation justifies the effectiveness of our system design.
Evaluation and Analysis of Hallucination in Large Vision-Language Models
Aug 29, 2023



Large Vision-Language Models (LVLMs) have recently achieved remarkable success. However, LVLMs are still plagued by the hallucination problem, which limits the practicality in many scenarios. Hallucination refers to the information of LVLMs' responses that does not exist in the visual input, which poses potential risks of substantial consequences. There has been limited work studying hallucination evaluation in LVLMs. In this paper, we propose Hallucination Evaluation based on Large Language Models (HaELM), an LLM-based hallucination evaluation framework. HaELM achieves an approximate 95% performance comparable to ChatGPT and has additional advantages including low cost, reproducibility, privacy preservation and local deployment. Leveraging the HaELM, we evaluate the hallucination in current LVLMs. Furthermore, we analyze the factors contributing to hallucination in LVLMs and offer helpful suggestions to mitigate the hallucination problem. Our training data and human annotation hallucination data will be made public soon.