 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Urban Flow Inference with Multi-scale Representation Learning
Jun 14, 2024Fine-grained urban flow inference (FUFI) is a crucial transportation service aimed at improving traffic efficiency and safety. FUFI can infer fine-grained urban traffic flows based solely on observed coarse-grained data. However, most of existing methods focus on the influence of single-scale static geographic information on FUFI, neglecting the interactions and dynamic information between different-scale regions within the city. Different-scale geographical features can capture redundant information from the same spatial areas. In order to effectively learn multi-scale information across time and space, we propose an effective fine-grained urban flow inference model called UrbanMSR, which uses self-supervised contrastive learning to obtain dynamic multi-scale representations of neighborhood-level and city-level geographic information, and fuses multi-scale representations to improve fine-grained accuracy. The fusion of multi-scale representations enhances fine-grained. We validate the performance through extensive experiments on three real-world datasets. The resutls compared with state-of-the-art methods demonstrate the superiority of the proposed model.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024
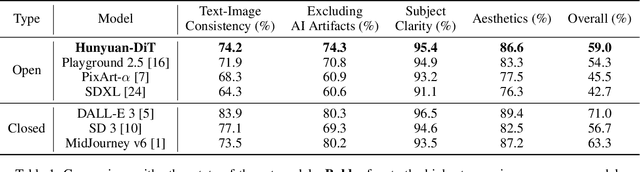


We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
Urban Region Embedding via Multi-View Contrastive Prediction
Dec 15, 2023Recently, learning urban region representations utilizing multi-modal data (information views) has become increasingly popular, for deep understanding of the distributions of various socioeconomic features in cities. However, previous methods usually blend multi-view information in a posteriors stage, falling short in learning coherent and consistent representations across different views. In this paper, we form a new pipeline to learn consistent representations across varying views, and propose the multi-view Contrastive Prediction model for urban Region embedding (ReCP), which leverages the multiple information views from point-of-interest (POI) and human mobility data. Specifically, ReCP comprises two major modules, namely an intra-view learning module utilizing contrastive learning and feature reconstruction to capture the unique information from each single view, and inter-view learning module that perceives the consistency between the two views using a contrastive prediction learning scheme. We conduct thorough experiments on two downstream tasks to assess the proposed model, i.e., land use clustering and region popularity prediction. The experimental results demonstrate that our model outperforms state-of-the-art baseline methods significantly in urban region representation learning.
Deep Learning Enables Large Depth-of-Field Images for Sub-Diffraction-Limit Scanning Superlens Microscopy
Oct 27, 2023Scanning electron microscopy (SEM) is indispensable in diverse applications ranging from microelectronics to food processing because it provides large depth-of-field images with a resolution beyond the optical diffraction limit. However, the technology requires coating conductive films on insulator samples and a vacuum environment. We use deep learning to obtain the mapping relationship between optical super-resolution (OSR) images and SEM domain images, which enables the transformation of OSR images into SEM-like large depth-of-field images. Our custom-built scanning superlens microscopy (SSUM) system, which requires neither coating samples by conductive films nor a vacuum environment, is used to acquire the OSR images with features down to ~80 nm. The peak signal-to-noise ratio (PSNR) and structural similarity index measure values indicate that the deep learning method performs excellently in image-to-image translation, with a PSNR improvement of about 0.74 dB over the optical super-resolution images. The proposed method provides a high level of detail in the reconstructed results, indicating that it has broad applicability to chip-level defect detection, biological sample analysis, forensics, and various other fields.
Structured Generation and Exploration of Design Space with Large Language Models for Human-AI Co-Creation
Oct 23, 2023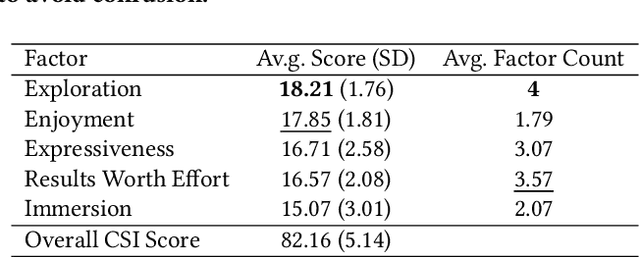
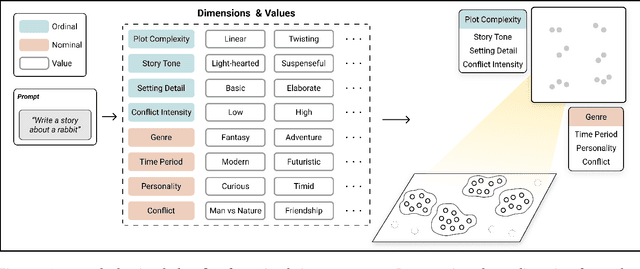
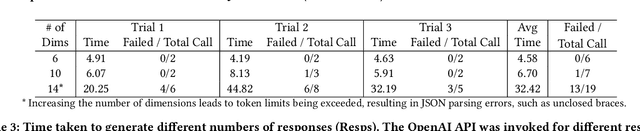
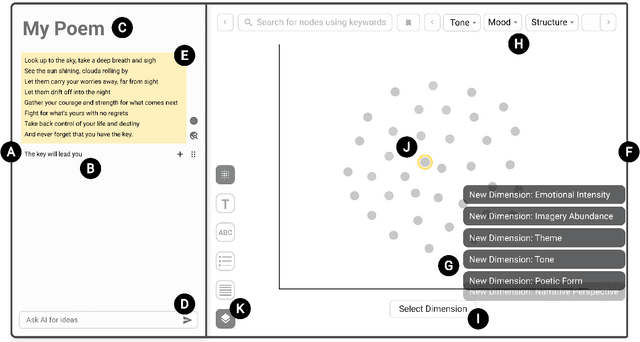
Thanks to their generative capabilities, large language models (LLMs) have become an invaluable tool for creative processes. These models have the capacity to produce hundreds and thousands of visual and textual outputs, offering abundant inspiration for creative endeavors. But are we harnessing their full potential? We argue that current interaction paradigms fall short, guiding users towards rapid convergence on a limited set of ideas, rather than empowering them to explore the vast latent design space in generative models. To address this limitation, we propose a framework that facilitates the structured generation of design space in which users can seamlessly explore, evaluate, and synthesize a multitude of responses. We demonstrate the feasibility and usefulness of this framework through the design and development of an interactive system, Luminate, and a user study with 8 professional writers. Our work advances how we interact with LLMs for creative tasks, introducing a way to harness the creative potential of LLMs.
VITS-based Singing Voice Conversion System with DSPGAN post-processing for SVCC2023
Oct 08, 2023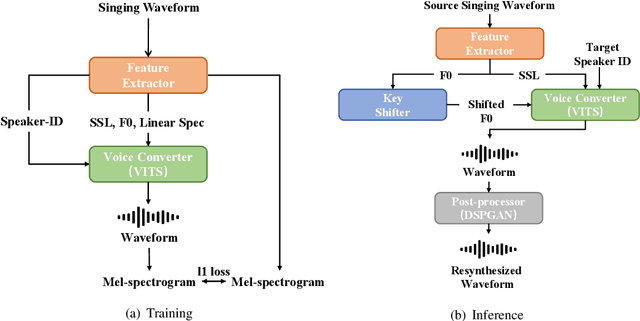
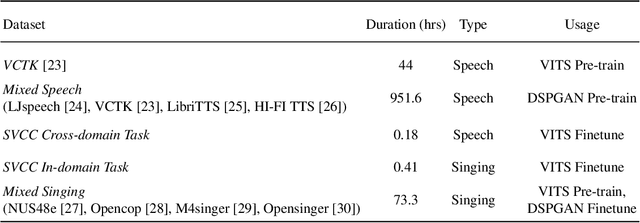
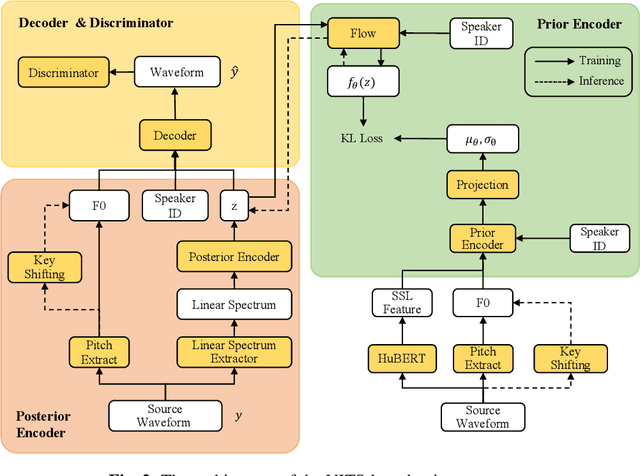
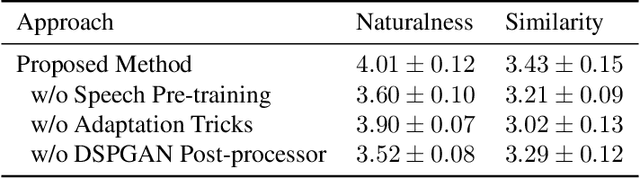
This paper presents the T02 team's system for the Singing Voice Conversion Challenge 2023 (SVCC2023). Our system entails a VITS-based SVC model, incorporating three modules: a feature extractor, a voice converter, and a post-processor. Specifically, the feature extractor provides F0 contours and extracts speaker-independent linguistic content from the input singing voice by leveraging a HuBERT model. The voice converter is employed to recompose the speaker timbre, F0, and linguistic content to generate the waveform of the target speaker. Besides, to further improve the audio quality, a fine-tuned DSPGAN vocoder is introduced to re-synthesise the waveform. Given the limited target speaker data, we utilize a two-stage training strategy to adapt the base model to the target speaker. During model adaptation, several tricks, such as data augmentation and joint training with auxiliary singer data, are involved. Official challenge results show that our system achieves superior performance, especially in the cross-domain task, ranking 1st and 2nd in naturalness and similarity, respectively. Further ablation justifies the effectiveness of our system design.
Leveraging Label Information for Multimodal Emotion Recognition
Sep 05, 2023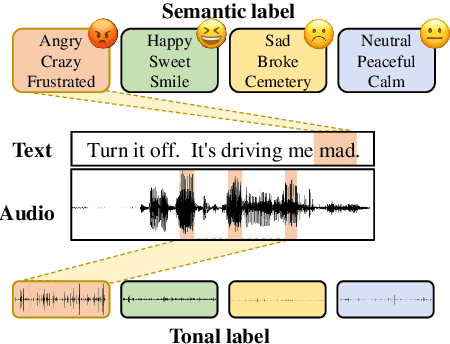

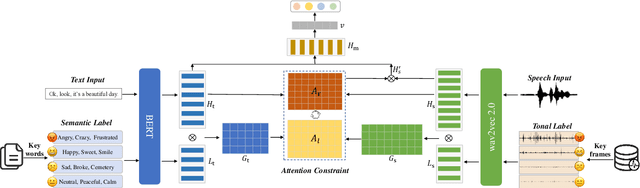
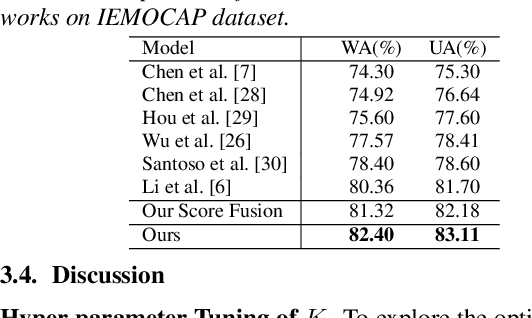
Multimodal emotion recognition (MER) aims to detect the emotional status of a given expression by combining the speech and text information. Intuitively, label information should be capable of helping the model locate the salient tokens/frames relevant to the specific emotion, which finally facilitates the MER task. Inspired by this, we propose a novel approach for MER by leveraging label information. Specifically, we first obtain the representative label embeddings for both text and speech modalities, then learn the label-enhanced text/speech representations for each utterance via label-token and label-frame interactions. Finally, we devise a novel label-guided attentive fusion module to fuse the label-aware text and speech representations for emotion classification. Extensive experiments were conducted on the public IEMOCAP dataset, and experimental results demonstrate that our proposed approach outperforms existing baselines and achieves new state-of-the-art performance.
Do We Fully Understand Students' Knowledge States? Identifying and Mitigating Answer Bias in Knowledge Tracing
Aug 15, 2023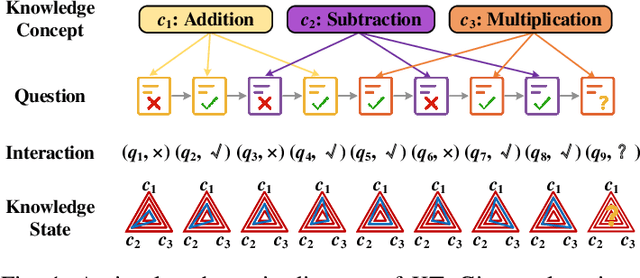
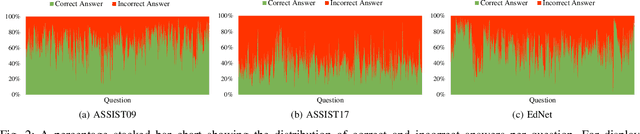
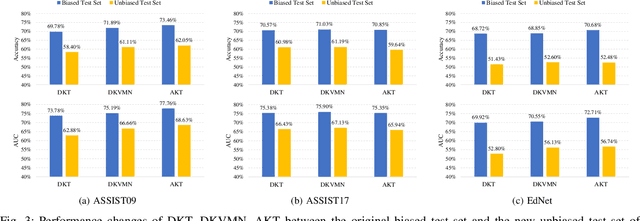
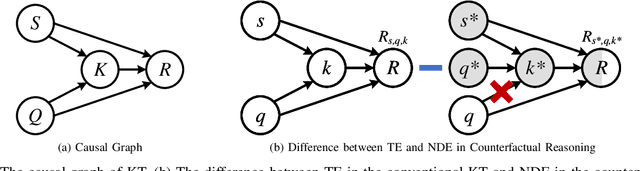
Knowledge tracing (KT) aims to monitor students' evolving knowledge states through their learning interactions with concept-related questions, and can be indirectly evaluated by predicting how students will perform on future questions. In this paper, we observe that there is a common phenomenon of answer bias, i.e., a highly unbalanced distribution of correct and incorrect answers for each question. Existing models tend to memorize the answer bias as a shortcut for achieving high prediction performance in KT, thereby failing to fully understand students' knowledge states. To address this issue, we approach the KT task from a causality perspective. A causal graph of KT is first established, from which we identify that the impact of answer bias lies in the direct causal effect of questions on students' responses. A novel COunterfactual REasoning (CORE) framework for KT is further proposed, which separately captures the total causal effect and direct causal effect during training, and mitigates answer bias by subtracting the latter from the former in testing. The CORE framework is applicable to various existing KT models, and we implement it based on the prevailing DKT, DKVMN, and AKT models, respectively. Extensive experiments on three benchmark datasets demonstrate the effectiveness of CORE in making the debiased inference for KT.
Accurate RSS-Based Localization Using an Opposition-Based Learning Simulated Annealing Algorithm
Jul 22, 2023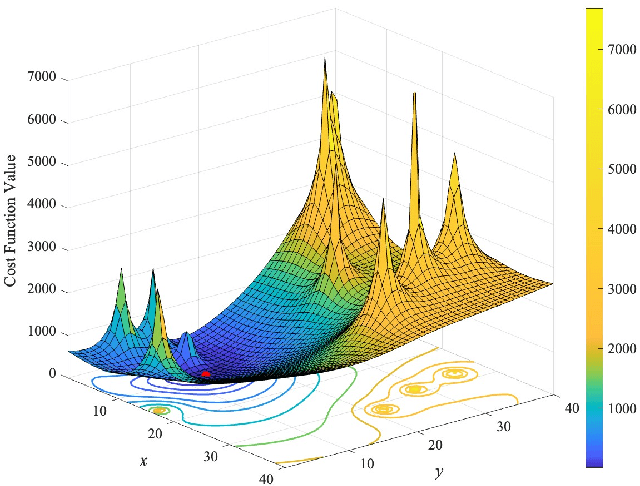
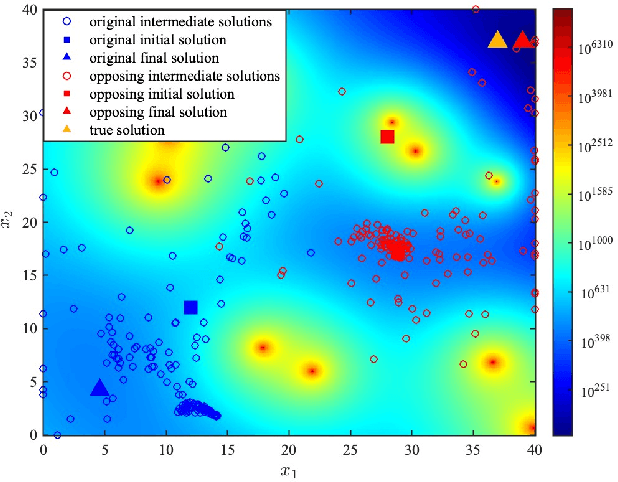
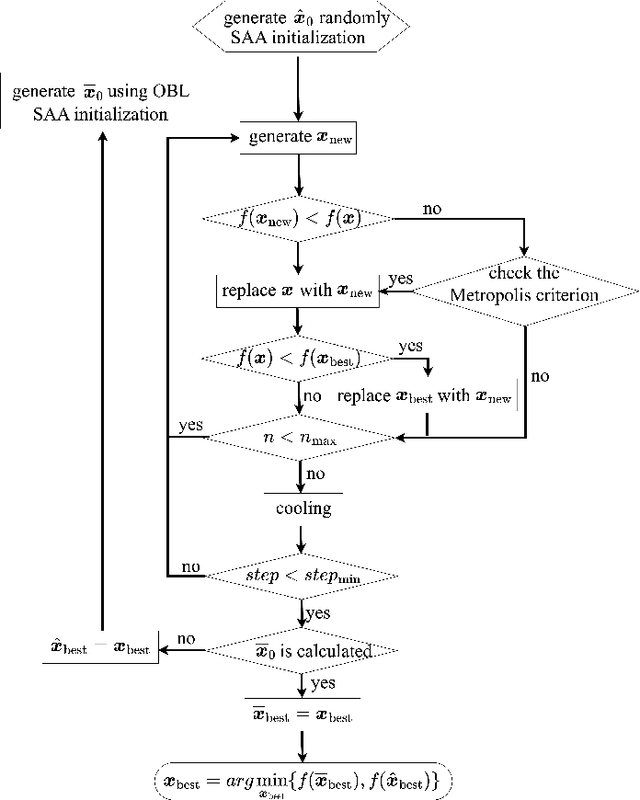
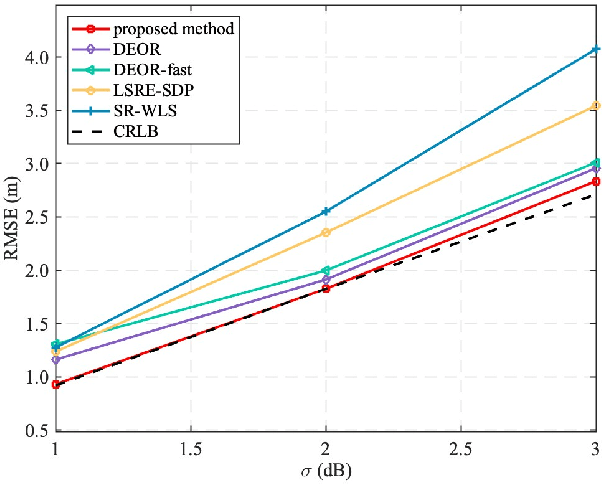
Wireless sensor networks require accurate target localization, often achieved through received signal strength (RSS) localization estimation based on maximum likelihood (ML). However, ML-based algorithms can suffer from issues such as low diversity, slow convergence, and local optima, which can significantly affect localization performance. In this paper, we propose a novel localization algorithm that combines opposition-based learning (OBL) and simulated annealing algorithm (SAA) to address these challenges. The algorithm begins by generating an initial solution randomly, which serves as the starting point for the SAA. Subsequently, OBL is employed to generate an opposing initial solution, effectively providing an alternative initial solution. The SAA is then executed independently on both the original and opposing initial solutions, optimizing each towards a potential optimal solution. The final solution is selected as the more effective of the two outcomes from the SAA, thereby reducing the likelihood of the algorithm becoming trapped in local optima. Simulation results indicate that the proposed algorithm consistently outperforms existing algorithms in terms of localization accuracy, demonstrating the effectiveness of our approach.
OTF: Optimal Transport based Fusion of Supervised and Self-Supervised Learning Models for Automatic Speech Recognition
Jun 05, 2023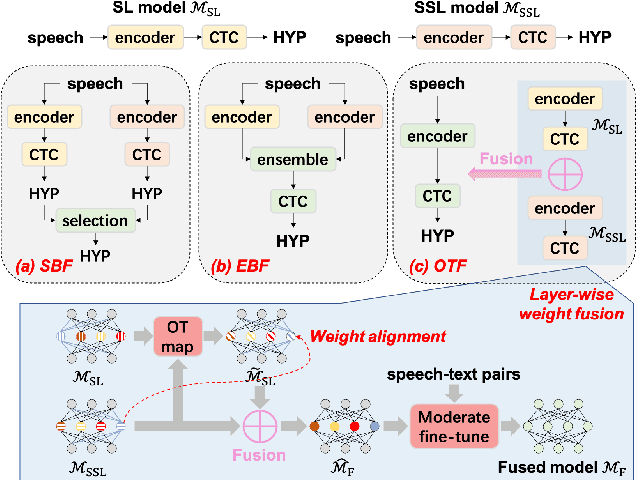
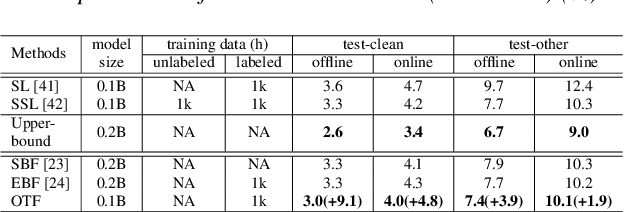
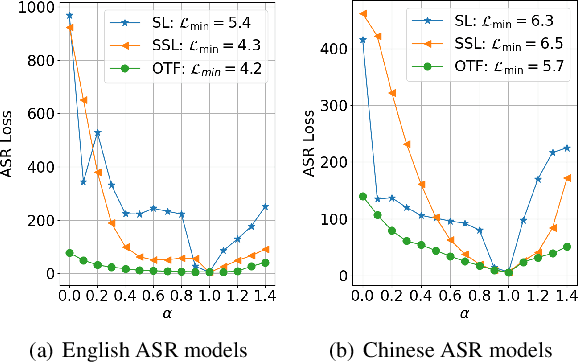
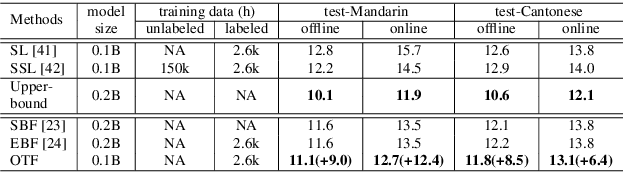
Self-Supervised Learning (SSL) Automatic Speech Recognition (ASR) models have shown great promise over Supervised Learning (SL) ones in low-resource settings. However, the advantages of SSL are gradually weakened when the amount of labeled data increases in many industrial applications. To further improve the ASR performance when abundant labels are available, we first explore the potential of combining SL and SSL ASR models via analyzing their complementarity in recognition accuracy and optimization property. Then, we propose a novel Optimal Transport based Fusion (OTF) method for SL and SSL models without incurring extra computation cost in inference. Specifically, optimal transport is adopted to softly align the layer-wise weights to unify the two different networks into a single one. Experimental results on the public 1k-hour English LibriSpeech dataset and our in-house 2.6k-hour Chinese dataset show that OTF largely outperforms the individual models with lower error rates.