 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances on Machine Learning for Computational Fluid Dynamics: A Survey
Aug 22, 2024This paper explores the recent advancements in enhancing Computational Fluid Dynamics (CFD) tasks through Machine Learning (ML) techniques. We begin by introducing fundamental concepts, traditional methods, and benchmark datasets, then examine the various roles ML plays in improving CFD. The literature systematically reviews papers in recent five years and introduces a novel classification for forward modeling: Data-driven Surrogates, Physics-Informed Surrogates, and ML-assisted Numerical Solutions. Furthermore, we also review the latest ML methods in inverse design and control, offering a novel classification and providing an in-depth discussion. Then we highlight real-world applications of ML for CFD in critical scientific and engineering disciplines, including aerodynamics, combustion, atmosphere & ocean science, biology fluid, plasma, symbolic regression, and reduced order modeling. Besides, we identify key challenges and advocate for future research directions to address these challenges, such as multi-scale representation, physical knowledge encoding, scientific foundation model and automatic scientific discovery. This review serves as a guide for the rapidly expanding ML for CFD community, aiming to inspire insights for future advancements. We draw the conclusion that ML is poised to significantly transform CFD research by enhancing simulation accuracy, reducing computational time, and enabling more complex analyses of fluid dynamics. The paper resources can be viewed at https://github.com/WillDreamer/Awesome-AI4CFD.
When Parameter-efficient Tuning Meets General-purpose Vision-language Models
Dec 16, 2023Instruction tuning has shown promising potential for developing general-purpose AI capabilities by using large-scale pre-trained models and boosts growing research to integrate multimodal information for creative applications. However, existing works still face two main limitations: the high training costs and heavy computing resource dependence of full model fine-tuning, and the lack of semantic information in instructions, which hinders multimodal alignment. Addressing these challenges, this paper proposes a novel approach to utilize Parameter-Efficient Tuning for generAl-purpose vision-Language models, namely PETAL. PETAL revolutionizes the training process by requiring only 0.5% of the total parameters, achieved through a unique mode approximation technique, which significantly reduces the training costs and reliance on heavy computing resources. Furthermore, PETAL enhances the semantic depth of instructions in two innovative ways: 1) by introducing adaptive instruction mixture-of-experts(MOEs), and 2) by fortifying the score-based linkage between parameter-efficient tuning and mutual information. Our extensive experiments across five multimodal downstream benchmarks reveal that PETAL not only outperforms current state-of-the-art methods in most scenarios but also surpasses full fine-tuning models in effectiveness. Additionally, our approach demonstrates remarkable advantages in few-shot settings, backed by comprehensive visualization analyses. Our source code is available at: https://github. com/melonking32/PETAL.
Mode Approximation Makes Good Multimodal Prompts
May 23, 2023Driven by the progress of large-scale pre-training, parameter-efficient transfer learning has gained immense popularity across different subfields of Artificial Intelligence. The core is to adapt the model to downstream tasks with only a small set of parameters. Recently, researchers have leveraged such proven techniques in multimodal tasks and achieve promising results. However, two critical issues remain unresolved: how to further reduce the complexity with lightweight design and how to boost alignment between modalities under extremely low parameters. In this paper, we propose A graceful prompt framework for cross-modal transfer (Aurora) to overcome these challenges. Considering the redundancy in existing architectures, we first utilize the mode approximation to generate 0.1M trainable parameters to implement the multimodal prompt tuning, which explores the low intrinsic dimension with only 0.04% parameters of the pre-trained model. Then, for better modality alignment, we propose the Informative Context Enhancement and Gated Query Transformation module under extremely few parameters scenes. A thorough evaluation on six cross-modal benchmarks shows that it not only outperforms the state-of-the-art but even outperforms the full fine-tuning approach. Our code is available at: https://github.com/WillDreamer/Aurora.
Exploiting Pseudo Image Captions for Multimodal Summarization
May 09, 2023Cross-modal contrastive learning in vision language pretraining (VLP) faces the challenge of (partial) false negatives. In this paper, we study this problem from the perspective of Mutual Information (MI) optimization. It is common sense that InfoNCE loss used in contrastive learning will maximize the lower bound of MI between anchors and their positives, while we theoretically prove that MI involving negatives also matters when noises commonly exist. Guided by a more general lower bound form for optimization, we propose a contrastive learning strategy regulated by progressively refined cross-modal similarity, to more accurately optimize MI between an image/text anchor and its negative texts/images instead of improperly minimizing it. Our method performs competitively on four downstream cross-modal tasks and systematically balances the beneficial and harmful effects of (partial) false negative samples under theoretical guidance.
LION: Implicit Vision Prompt Tuning
Mar 17, 2023Despite recent competitive performance across a range of vision tasks, vision Transformers still have an issue of heavy computational costs. Recently, vision prompt learning has provided an economic solution to this problem without fine-tuning the whole large-scale models. However, the efficiency of existing models are still far from satisfactory due to insertion of extensive prompts blocks and trick prompt designs. In this paper, we propose an efficient vision model named impLicit vIsion prOmpt tuNing (LION), which is motivated by deep implicit models with stable memory costs for various complex tasks. In particular, we merely insect two equilibrium implicit layers in two ends of the pre-trained main backbone with parameters in the backbone frozen. Moreover, we prune the parameters in these two layers according to lottery hypothesis. The performance obtained by our LION are promising on a wide range of datasets. In particular, our LION reduces up to 11.5% of training parameter numbers while obtaining higher performance compared with the state-of-the-art baseline VPT, especially under challenging scenes. Furthermore, we find that our proposed LION had a good generalization performance, making it an easy way to boost transfer learning in the future.
Frequency-Aware Contrastive Learning for Neural Machine Translation
Dec 29, 2021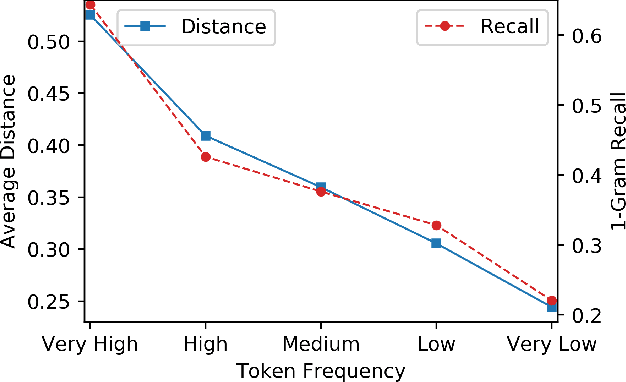
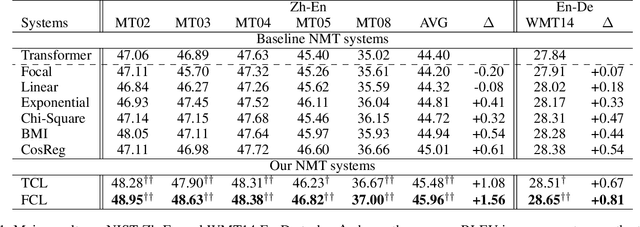
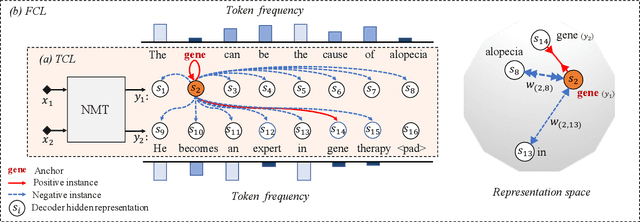
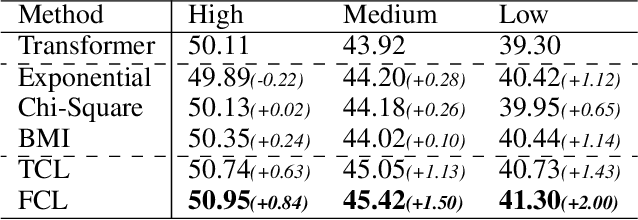
Low-frequency word prediction remains a challenge in modern neural machine translation (NMT) systems. Recent adaptive training methods promote the output of infrequent words by emphasizing their weights in the overall training objectives. Despite the improved recall of low-frequency words, their prediction precision is unexpectedly hindered by the adaptive objectives. Inspired by the observation that low-frequency words form a more compact embedding space, we tackle this challenge from a representation learning perspective. Specifically, we propose a frequency-aware token-level contrastive learning method, in which the hidden state of each decoding step is pushed away from the counterparts of other target words, in a soft contrastive way based on the corresponding word frequencies. We conduct experiments on widely used NIST Chinese-English and WMT14 English-German translation tasks. Empirical results show that our proposed methods can not only significantly improve the translation quality but also enhance lexical diversity and optimize word representation space. Further investigation reveals that, comparing with related adaptive training strategies, the superiority of our method on low-frequency word prediction lies in the robustness of token-level recall across different frequencies without sacrificing precision.
Exploiting Method Names to Improve Code Summarization: A Deliberation Multi-Task Learning Approach
Mar 30, 2021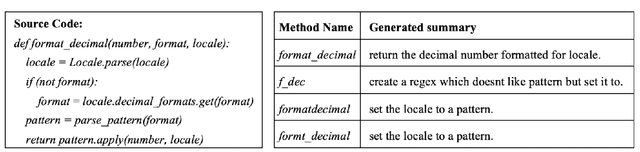
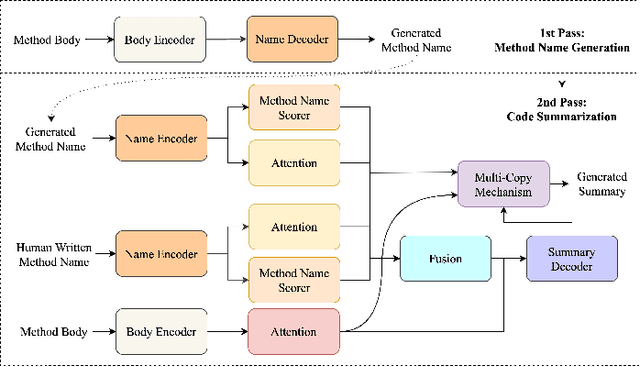


Code summaries are brief natural language descriptions of source code pieces. The main purpose of code summarization is to assist developers in understanding code and to reduce documentation workload. In this paper, we design a novel multi-task learning (MTL) approach for code summarization through mining the relationship between method code summaries and method names. More specifically, since a method's name can be considered as a shorter version of its code summary, we first introduce the tasks of generation and informativeness prediction of method names as two auxiliary training objectives for code summarization. A novel two-pass deliberation mechanism is then incorporated into our MTL architecture to generate more consistent intermediate states fed into a summary decoder, especially when informative method names do not exist. To evaluate our deliberation MTL approach, we carried out a large-scale experiment on two existing datasets for Java and Python. The experiment results show that our technique can be easily applied to many state-of-the-art neural models for code summarization and improve their performance. Meanwhile, our approach shows significant superiority when generating summaries for methods with non-informative names.