 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Graph Prompt Learning: A Survey and Beyond
Aug 26, 2024Large-scale "pre-train and prompt learning" paradigms have demonstrated remarkable adaptability, enabling broad applications across diverse domains such as question answering, image recognition, and multimodal retrieval. This approach fully leverages the potential of large-scale pre-trained models, reducing downstream data requirements and computational costs while enhancing model applicability across various tasks. Graphs, as versatile data structures that capture relationships between entities, play pivotal roles in fields such as social network analysis, recommender systems, and biological graphs. Despite the success of pre-train and prompt learning paradigms in Natural Language Processing (NLP) and Computer Vision (CV), their application in graph domains remains nascent. In graph-structured data, not only do the node and edge features often have disparate distributions, but the topological structures also differ significantly. This diversity in graph data can lead to incompatible patterns or gaps between pre-training and fine-tuning on downstream graphs. We aim to bridge this gap by summarizing methods for alleviating these disparities. This includes exploring prompt design methodologies, comparing related techniques, assessing application scenarios and datasets, and identifying unresolved problems and challenges. This survey categorizes over 100 relevant works in this field, summarizing general design principles and the latest applications, including text-attributed graphs, molecules, proteins, and recommendation systems. Through this extensive review, we provide a foundational understanding of graph prompt learning, aiming to impact not only the graph mining community but also the broader Artificial General Intelligence (AGI) community.
Recent Advances on Machine Learning for Computational Fluid Dynamics: A Survey
Aug 22, 2024This paper explores the recent advancements in enhancing Computational Fluid Dynamics (CFD) tasks through Machine Learning (ML) techniques. We begin by introducing fundamental concepts, traditional methods, and benchmark datasets, then examine the various roles ML plays in improving CFD. The literature systematically reviews papers in recent five years and introduces a novel classification for forward modeling: Data-driven Surrogates, Physics-Informed Surrogates, and ML-assisted Numerical Solutions. Furthermore, we also review the latest ML methods in inverse design and control, offering a novel classification and providing an in-depth discussion. Then we highlight real-world applications of ML for CFD in critical scientific and engineering disciplines, including aerodynamics, combustion, atmosphere & ocean science, biology fluid, plasma, symbolic regression, and reduced order modeling. Besides, we identify key challenges and advocate for future research directions to address these challenges, such as multi-scale representation, physical knowledge encoding, scientific foundation model and automatic scientific discovery. This review serves as a guide for the rapidly expanding ML for CFD community, aiming to inspire insights for future advancements. We draw the conclusion that ML is poised to significantly transform CFD research by enhancing simulation accuracy, reducing computational time, and enabling more complex analyses of fluid dynamics. The paper resources can be viewed at https://github.com/WillDreamer/Awesome-AI4CFD.
Rank and Align: Towards Effective Source-free Graph Domain Adaptation
Aug 22, 2024Graph neural networks (GNNs) have achieved impressive performance in graph domain adaptation. However, extensive source graphs could be unavailable in real-world scenarios due to privacy and storage concerns. To this end, we investigate an underexplored yet practical problem of source-free graph domain adaptation, which transfers knowledge from source models instead of source graphs to a target domain. To solve this problem, we introduce a novel GNN-based approach called Rank and Align (RNA), which ranks graph similarities with spectral seriation for robust semantics learning, and aligns inharmonic graphs with harmonic graphs which close to the source domain for subgraph extraction. In particular, to overcome label scarcity, we employ the spectral seriation algorithm to infer the robust pairwise rankings, which can guide semantic learning using a similarity learning objective. To depict distribution shifts, we utilize spectral clustering and the silhouette coefficient to detect harmonic graphs, which the source model can easily classify. To reduce potential domain discrepancy, we extract domain-invariant subgraphs from inharmonic graphs by an adversarial edge sampling process, which guides the invariant learning of GNNs. Extensive experiments on several benchmark datasets demonstrate the effectiveness of our proposed RNA.
DisenSemi: Semi-supervised Graph Classification via Disentangled Representation Learning
Jul 19, 2024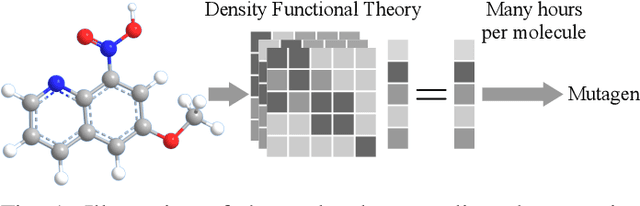
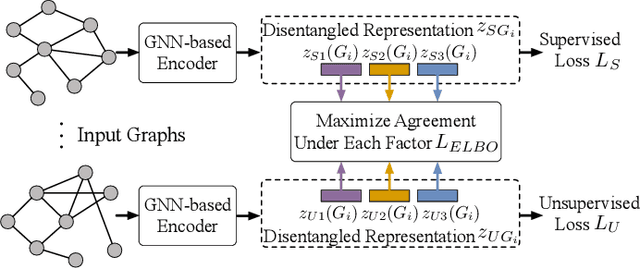
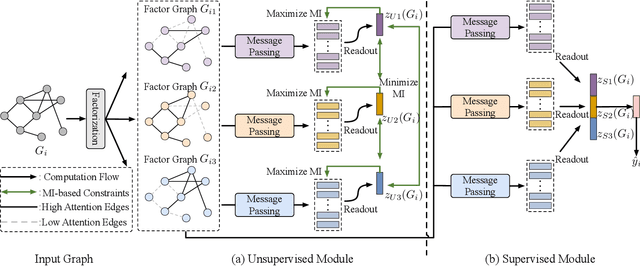
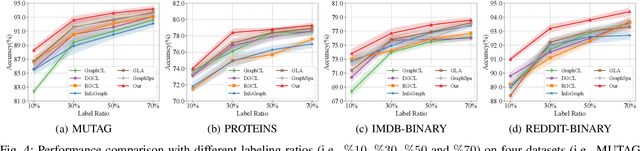
Graph classification is a critical task in numerous multimedia applications, where graphs are employed to represent diverse types of multimedia data, including images, videos, and social networks. Nevertheless, in real-world scenarios, labeled graph data can be limited or scarce. To address this issue, we focus on the problem of semi-supervised graph classification, which involves both supervised and unsupervised models learning from labeled and unlabeled data. In contrast to recent approaches that transfer the entire knowledge from the unsupervised model to the supervised one, we argue that an effective transfer should only retain the relevant semantics that align well with the supervised task. In this paper, we propose a novel framework named DisenSemi, which learns disentangled representation for semi-supervised graph classification. Specifically, a disentangled graph encoder is proposed to generate factor-wise graph representations for both supervised and unsupervised models. Then we train two models via supervised objective and mutual information (MI)-based constraints respectively. To ensure the meaningful transfer of knowledge from the unsupervised encoder to the supervised one, we further define an MI-based disentangled consistency regularization between two models and identify the corresponding rationale that aligns well with the current graph classification task. Experimental results on a range of publicly accessible datasets reveal the effectiveness of our DisenSemi.
Geneverse: A collection of Open-source Multimodal Large Language Models for Genomic and Proteomic Research
Jun 21, 2024The applications of large language models (LLMs) are promising for biomedical and healthcare research. Despite the availability of open-source LLMs trained using a wide range of biomedical data, current research on the applications of LLMs to genomics and proteomics is still limited. To fill this gap, we propose a collection of finetuned LLMs and multimodal LLMs (MLLMs), known as Geneverse, for three novel tasks in genomic and proteomic research. The models in Geneverse are trained and evaluated based on domain-specific datasets, and we use advanced parameter-efficient finetuning techniques to achieve the model adaptation for tasks including the generation of descriptions for gene functions, protein function inference from its structure, and marker gene selection from spatial transcriptomic data. We demonstrate that adapted LLMs and MLLMs perform well for these tasks and may outperform closed-source large-scale models based on our evaluations focusing on both truthfulness and structural correctness. All of the training strategies and base models we used are freely accessible.
A Comprehensive Graph Pooling Benchmark: Effectiveness, Robustness and Generalizability
Jun 16, 2024Graph pooling has gained attention for its ability to obtain effective node and graph representations for various downstream tasks. Despite the recent surge in graph pooling approaches, there is a lack of standardized experimental settings and fair benchmarks to evaluate their performance. To address this issue, we have constructed a comprehensive benchmark that includes 15 graph pooling methods and 21 different graph datasets. This benchmark systematically assesses the performance of graph pooling methods in three dimensions, i.e., effectiveness, robustness, and generalizability. We first evaluate the performance of these graph pooling approaches across different tasks including graph classification, graph regression and node classification. Then, we investigate their performance under potential noise attacks and out-of-distribution shifts in real-world scenarios. We also involve detailed efficiency analysis and parameter analysis. Extensive experiments validate the strong capability and applicability of graph pooling approaches in various scenarios, which can provide valuable insights and guidance for deep geometric learning research. The source code of our benchmark is available at https://github.com/goose315/Graph_Pooling_Benchmark.
Towards Graph Contrastive Learning: A Survey and Beyond
May 20, 2024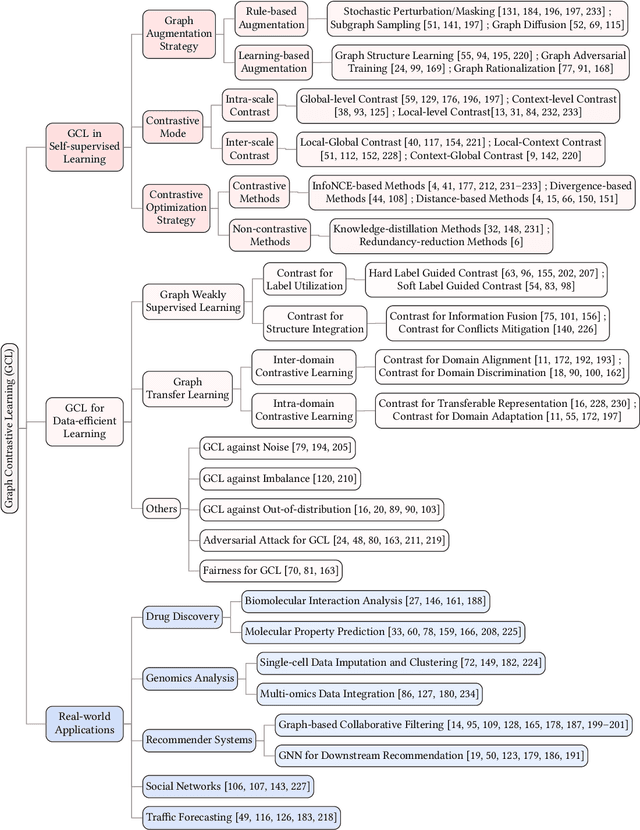
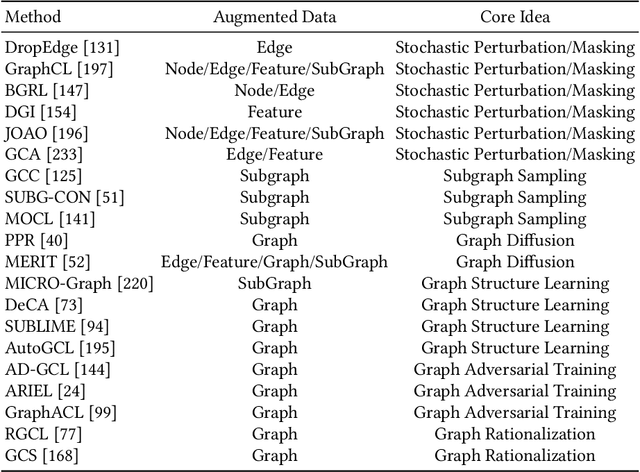
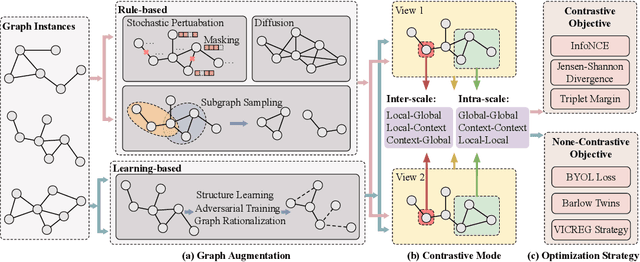
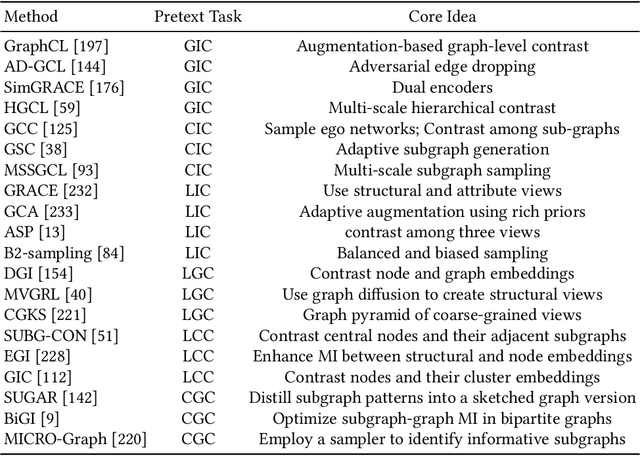
In recent years, deep learning on graphs has achieved remarkable success in various domains. However, the reliance on annotated graph data remains a significant bottleneck due to its prohibitive cost and time-intensive nature. To address this challenge, self-supervised learning (SSL) on graphs has gained increasing attention and has made significant progress. SSL enables machine learning models to produce informative representations from unlabeled graph data, reducing the reliance on expensive labeled data. While SSL on graphs has witnessed widespread adoption, one critical component, Graph Contrastive Learning (GCL), has not been thoroughly investigated in the existing literature. Thus, this survey aims to fill this gap by offering a dedicated survey on GCL. We provide a comprehensive overview of the fundamental principles of GCL, including data augmentation strategies, contrastive modes, and contrastive optimization objectives. Furthermore, we explore the extensions of GCL to other aspects of data-efficient graph learning, such as weakly supervised learning, transfer learning, and related scenarios. We also discuss practical applications spanning domains such as drug discovery, genomics analysis, recommender systems, and finally outline the challenges and potential future directions in this field.
DEMO: A Statistical Perspective for Efficient Image-Text Matching
May 19, 2024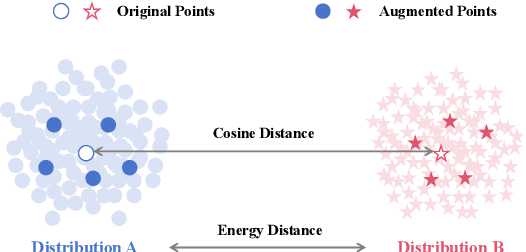
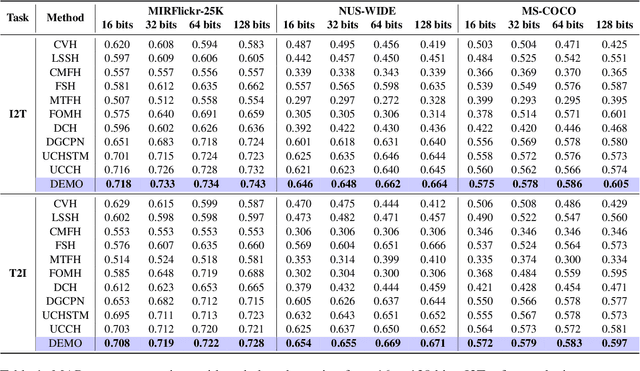
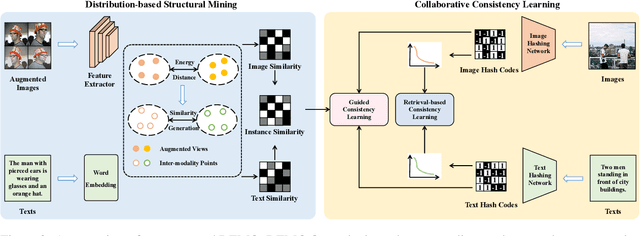
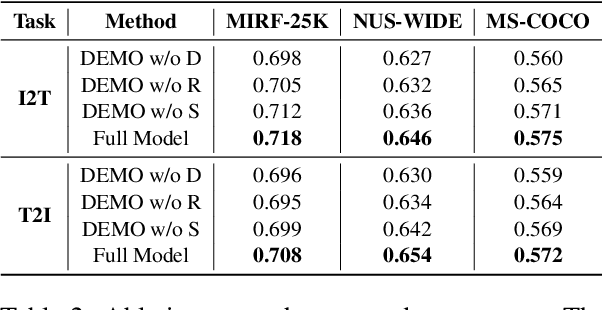
Image-text matching has been a long-standing problem, which seeks to connect vision and language through semantic understanding. Due to the capability to manage large-scale raw data, unsupervised hashing-based approaches have gained prominence recently. They typically construct a semantic similarity structure using the natural distance, which subsequently provides guidance to the model optimization process. However, the similarity structure could be biased at the boundaries of semantic distributions, causing error accumulation during sequential optimization. To tackle this, we introduce a novel hashing approach termed Distribution-based Structure Mining with Consistency Learning (DEMO) for efficient image-text matching. From a statistical view, DEMO characterizes each image using multiple augmented views, which are considered as samples drawn from its intrinsic semantic distribution. Then, we employ a non-parametric distribution divergence to ensure a robust and precise similarity structure. In addition, we introduce collaborative consistency learning which not only preserves the similarity structure in the Hamming space but also encourages consistency between retrieval distribution from different directions in a self-supervised manner. Through extensive experiments on three benchmark image-text matching datasets, we demonstrate that DEMO achieves superior performance compared with many state-of-the-art methods.
Hypergraph-enhanced Dual Semi-supervised Graph Classification
May 08, 2024In this paper, we study semi-supervised graph classification, which aims at accurately predicting the categories of graphs in scenarios with limited labeled graphs and abundant unlabeled graphs. Despite the promising capability of graph neural networks (GNNs), they typically require a large number of costly labeled graphs, while a wealth of unlabeled graphs fail to be effectively utilized. Moreover, GNNs are inherently limited to encoding local neighborhood information using message-passing mechanisms, thus lacking the ability to model higher-order dependencies among nodes. To tackle these challenges, we propose a Hypergraph-Enhanced DuAL framework named HEAL for semi-supervised graph classification, which captures graph semantics from the perspective of the hypergraph and the line graph, respectively. Specifically, to better explore the higher-order relationships among nodes, we design a hypergraph structure learning to adaptively learn complex node dependencies beyond pairwise relations. Meanwhile, based on the learned hypergraph, we introduce a line graph to capture the interaction between hyperedges, thereby better mining the underlying semantic structures. Finally, we develop a relational consistency learning to facilitate knowledge transfer between the two branches and provide better mutual guidance. Extensive experiments on real-world graph datasets verify the effectiveness of the proposed method against existing state-of-the-art methods.
Fusion Dynamical Systems with Machine Learning in Imitation Learning: A Comprehensive Overview
Mar 29, 2024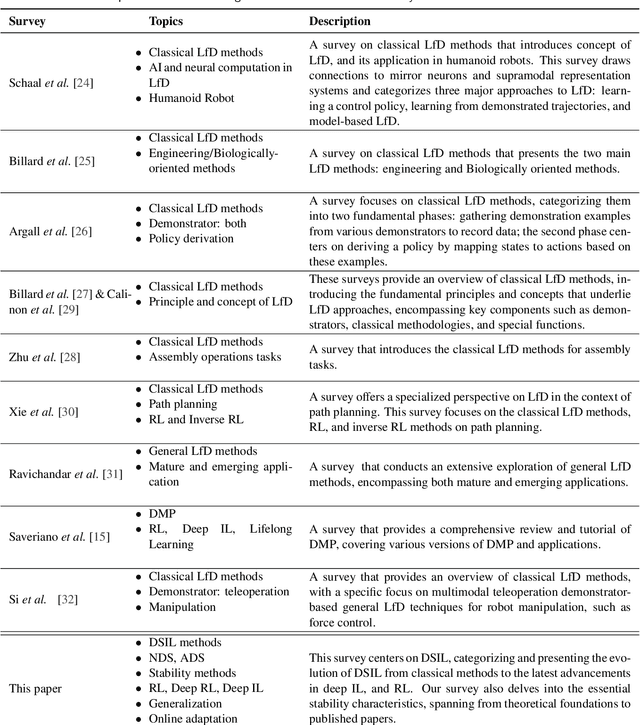
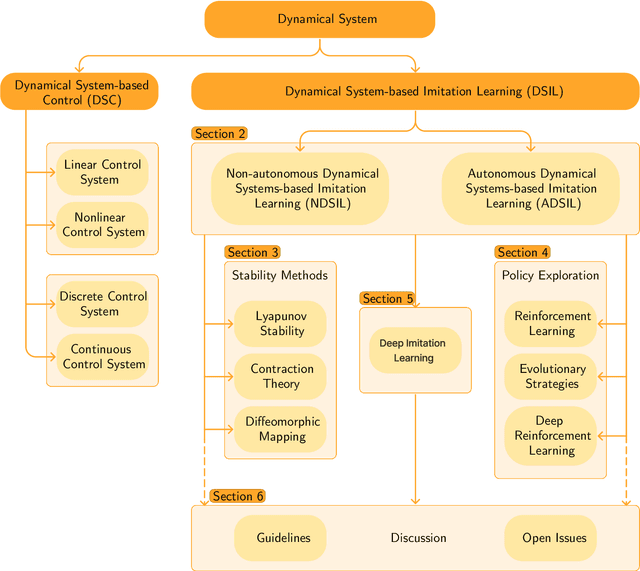
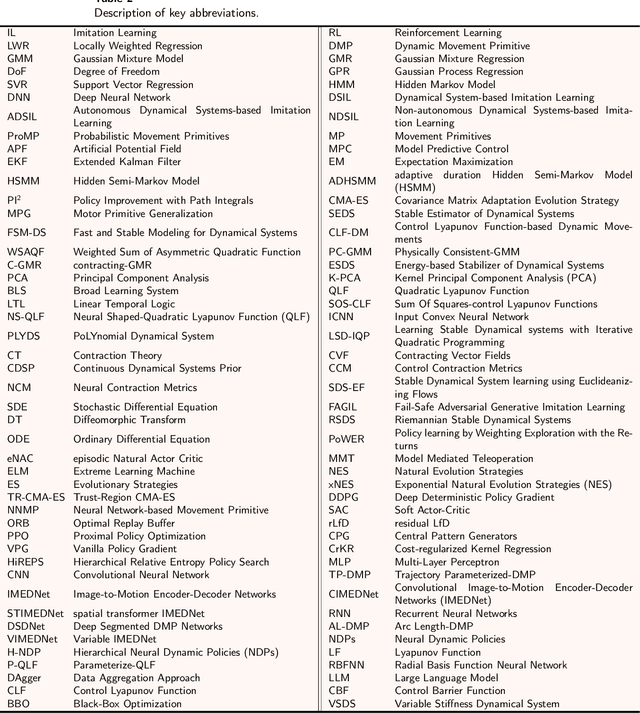
Imitation Learning (IL), also referred to as Learning from Demonstration (LfD), holds significant promise for capturing expert motor skills through efficient imitation, facilitating adept navigation of complex scenarios. A persistent challenge in IL lies in extending generalization from historical demonstrations, enabling the acquisition of new skills without re-teaching. Dynamical system-based IL (DSIL) emerges as a significant subset of IL methodologies, offering the ability to learn trajectories via movement primitives and policy learning based on experiential abstraction. This paper emphasizes the fusion of theoretical paradigms, integrating control theory principles inherent in dynamical systems into IL. This integration notably enhances robustness, adaptability, and convergence in the face of novel scenarios. This survey aims to present a comprehensive overview of DSIL methods, spanning from classical approaches to recent advanced approaches. We categorize DSIL into autonomous dynamical systems and non-autonomous dynamical systems, surveying traditional IL methods with low-dimensional input and advanced deep IL methods with high-dimensional input. Additionally, we present and analyze three main stability methods for IL: Lyapunov stability, contraction theory, and diffeomorphism mapping. Our exploration also extends to popular policy improvement methods for DSIL, encompassing reinforcement learning, deep reinforcement learning, and evolutionary strategies.