 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGALA: Graph Diffusion-based Alignment with Jigsaw for Source-free Domain Adaptation
Oct 22, 2024Source-free domain adaptation is a crucial machine learning topic, as it contains numerous applications in the real world, particularly with respect to data privacy. Existing approaches predominantly focus on Euclidean data, such as images and videos, while the exploration of non-Euclidean graph data remains scarce. Recent graph neural network (GNN) approaches can suffer from serious performance decline due to domain shift and label scarcity in source-free adaptation scenarios. In this study, we propose a novel method named Graph Diffusion-based Alignment with Jigsaw (GALA), tailored for source-free graph domain adaptation. To achieve domain alignment, GALA employs a graph diffusion model to reconstruct source-style graphs from target data. Specifically, a score-based graph diffusion model is trained using source graphs to learn the generative source styles. Then, we introduce perturbations to target graphs via a stochastic differential equation instead of sampling from a prior, followed by the reverse process to reconstruct source-style graphs. We feed the source-style graphs into an off-the-shelf GNN and introduce class-specific thresholds with curriculum learning, which can generate accurate and unbiased pseudo-labels for target graphs. Moreover, we develop a simple yet effective graph-mixing strategy named graph jigsaw to combine confident graphs and unconfident graphs, which can enhance generalization capabilities and robustness via consistency learning. Extensive experiments on benchmark datasets validate the effectiveness of GALA.
Rank and Align: Towards Effective Source-free Graph Domain Adaptation
Aug 22, 2024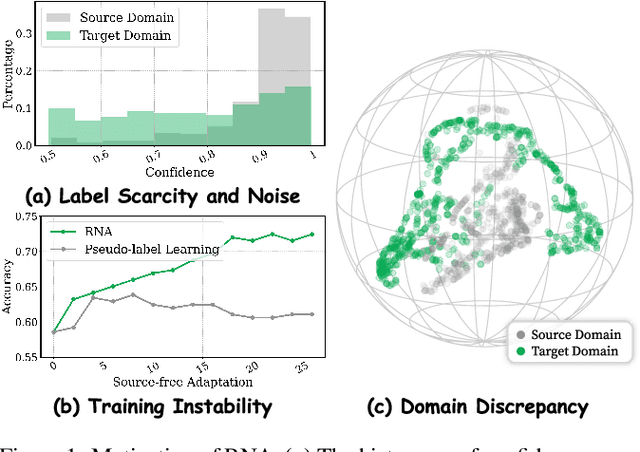
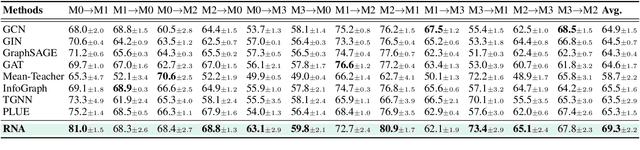
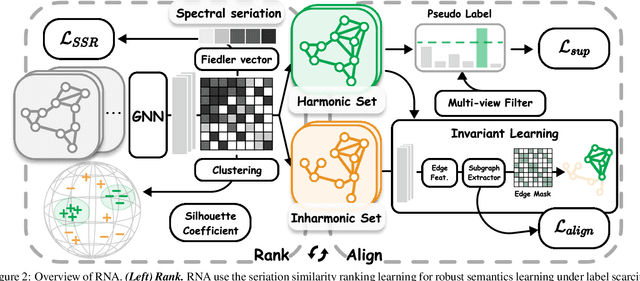

Graph neural networks (GNNs) have achieved impressive performance in graph domain adaptation. However, extensive source graphs could be unavailable in real-world scenarios due to privacy and storage concerns. To this end, we investigate an underexplored yet practical problem of source-free graph domain adaptation, which transfers knowledge from source models instead of source graphs to a target domain. To solve this problem, we introduce a novel GNN-based approach called Rank and Align (RNA), which ranks graph similarities with spectral seriation for robust semantics learning, and aligns inharmonic graphs with harmonic graphs which close to the source domain for subgraph extraction. In particular, to overcome label scarcity, we employ the spectral seriation algorithm to infer the robust pairwise rankings, which can guide semantic learning using a similarity learning objective. To depict distribution shifts, we utilize spectral clustering and the silhouette coefficient to detect harmonic graphs, which the source model can easily classify. To reduce potential domain discrepancy, we extract domain-invariant subgraphs from inharmonic graphs by an adversarial edge sampling process, which guides the invariant learning of GNNs. Extensive experiments on several benchmark datasets demonstrate the effectiveness of our proposed RNA.
A Hybrid RAG System with Comprehensive Enhancement on Complex Reasoning
Aug 09, 2024Retrieval-augmented generation (RAG) is a framework enabling large language models (LLMs) to enhance their accuracy and reduce hallucinations by integrating external knowledge bases. In this paper, we introduce a hybrid RAG system enhanced through a comprehensive suite of optimizations that significantly improve retrieval quality, augment reasoning capabilities, and refine numerical computation ability. We refined the text chunks and tables in web pages, added attribute predictors to reduce hallucinations, conducted LLM Knowledge Extractor and Knowledge Graph Extractor, and finally built a reasoning strategy with all the references. We evaluated our system on the CRAG dataset through the Meta CRAG KDD Cup 2024 Competition. Both the local and online evaluations demonstrate that our system significantly enhances complex reasoning capabilities. In local evaluations, we have significantly improved accuracy and reduced error rates compared to the baseline model, achieving a notable increase in scores. In the meanwhile, we have attained outstanding results in online assessments, demonstrating the performance and generalization capabilities of the proposed system. The source code for our system is released in \url{https://gitlab.aicrowd.com/shizueyy/crag-new}.
MMEvalPro: Calibrating Multimodal Benchmarks Towards Trustworthy and Efficient Evaluation
Jun 29, 2024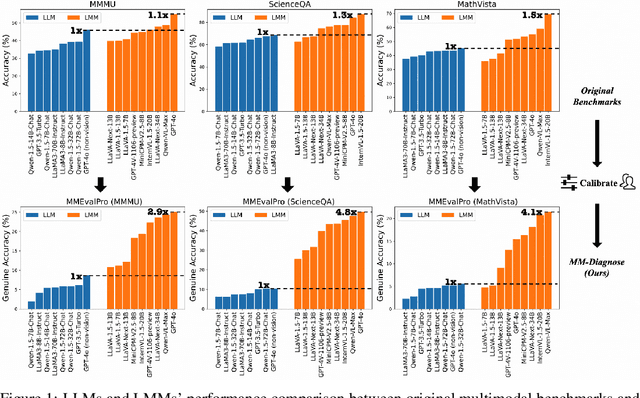



Large Multimodal Models (LMMs) exhibit impressive cross-modal understanding and reasoning abilities, often assessed through multiple-choice questions (MCQs) that include an image, a question, and several options. However, many benchmarks used for such evaluations suffer from systematic biases. Remarkably, Large Language Models (LLMs) without any visual perception capabilities achieve non-trivial performance, undermining the credibility of these evaluations. To address this issue while maintaining the efficiency of MCQ evaluations, we propose MMEvalPro, a benchmark designed to avoid Type-I errors through a trilogy evaluation pipeline and more rigorous metrics. For each original question from existing benchmarks, human annotators augment it by creating one perception question and one knowledge anchor question through a meticulous annotation process. MMEvalPro comprises $2,138$ question triplets, totaling $6,414$ distinct questions. Two-thirds of these questions are manually labeled by human experts, while the rest are sourced from existing benchmarks (MMMU, ScienceQA, and MathVista). Compared with the existing benchmarks, our experiments with the latest LLMs and LMMs demonstrate that MMEvalPro is more challenging (the best LMM lags behind human performance by $31.73\%$, compared to an average gap of $8.03\%$ in previous benchmarks) and more trustworthy (the best LLM trails the best LMM by $23.09\%$, whereas the gap for previous benchmarks is just $14.64\%$). Our in-depth analysis explains the reason for the large performance gap and justifies the trustworthiness of evaluation, underscoring its significant potential for advancing future research.
COOL: A Conjoint Perspective on Spatio-Temporal Graph Neural Network for Traffic Forecasting
Mar 02, 2024This paper investigates traffic forecasting, which attempts to forecast the future state of traffic based on historical situations. This problem has received ever-increasing attention in various scenarios and facilitated the development of numerous downstream applications such as urban planning and transportation management. However, the efficacy of existing methods remains sub-optimal due to their tendency to model temporal and spatial relationships independently, thereby inadequately accounting for complex high-order interactions of both worlds. Moreover, the diversity of transitional patterns in traffic forecasting makes them challenging to capture for existing approaches, warranting a deeper exploration of their diversity. Toward this end, this paper proposes Conjoint Spatio-Temporal graph neural network (abbreviated as COOL), which models heterogeneous graphs from prior and posterior information to conjointly capture high-order spatio-temporal relationships. On the one hand, heterogeneous graphs connecting sequential observation are constructed to extract composite spatio-temporal relationships via prior message passing. On the other hand, we model dynamic relationships using constructed affinity and penalty graphs, which guide posterior message passing to incorporate complementary semantic information into node representations. Moreover, to capture diverse transitional properties to enhance traffic forecasting, we propose a conjoint self-attention decoder that models diverse temporal patterns from both multi-rank and multi-scale views. Experimental results on four popular benchmark datasets demonstrate that our proposed COOL provides state-of-the-art performance compared with the competitive baselines.
ALEX: Towards Effective Graph Transfer Learning with Noisy Labels
Sep 26, 2023Graph Neural Networks (GNNs) have garnered considerable interest due to their exceptional performance in a wide range of graph machine learning tasks. Nevertheless, the majority of GNN-based approaches have been examined using well-annotated benchmark datasets, leading to suboptimal performance in real-world graph learning scenarios. To bridge this gap, the present paper investigates the problem of graph transfer learning in the presence of label noise, which transfers knowledge from a noisy source graph to an unlabeled target graph. We introduce a novel technique termed Balance Alignment and Information-aware Examination (ALEX) to address this challenge. ALEX first employs singular value decomposition to generate different views with crucial structural semantics, which help provide robust node representations using graph contrastive learning. To mitigate both label shift and domain shift, we estimate a prior distribution to build subgraphs with balanced label distributions. Building on this foundation, an adversarial domain discriminator is incorporated for the implicit domain alignment of complex multi-modal distributions. Furthermore, we project node representations into a different space, optimizing the mutual information between the projected features and labels. Subsequently, the inconsistency of similarity structures is evaluated to identify noisy samples with potential overfitting. Comprehensive experiments on various benchmark datasets substantiate the outstanding superiority of the proposed ALEX in different settings.
Learning on Graphs under Label Noise
Jun 14, 2023Node classification on graphs is a significant task with a wide range of applications, including social analysis and anomaly detection. Even though graph neural networks (GNNs) have produced promising results on this task, current techniques often presume that label information of nodes is accurate, which may not be the case in real-world applications. To tackle this issue, we investigate the problem of learning on graphs with label noise and develop a novel approach dubbed Consistent Graph Neural Network (CGNN) to solve it. Specifically, we employ graph contrastive learning as a regularization term, which promotes two views of augmented nodes to have consistent representations. Since this regularization term cannot utilize label information, it can enhance the robustness of node representations to label noise. Moreover, to detect noisy labels on the graph, we present a sample selection technique based on the homophily assumption, which identifies noisy nodes by measuring the consistency between the labels with their neighbors. Finally, we purify these confident noisy labels to permit efficient semantic graph learning. Extensive experiments on three well-known benchmark datasets demonstrate the superiority of our CGNN over competing approaches.
A Comprehensive Survey on Deep Graph Representation Learning
Apr 19, 2023Graph representation learning aims to effectively encode high-dimensional sparse graph-structured data into low-dimensional dense vectors, which is a fundamental task that has been widely studied in a range of fields, including machine learning and data mining. Classic graph embedding methods follow the basic idea that the embedding vectors of interconnected nodes in the graph can still maintain a relatively close distance, thereby preserving the structural information between the nodes in the graph. However, this is sub-optimal due to: (i) traditional methods have limited model capacity which limits the learning performance; (ii) existing techniques typically rely on unsupervised learning strategies and fail to couple with the latest learning paradigms; (iii) representation learning and downstream tasks are dependent on each other which should be jointly enhanced. With the remarkable success of deep learning, deep graph representation learning has shown great potential and advantages over shallow (traditional) methods, there exist a large number of deep graph representation learning techniques have been proposed in the past decade, especially graph neural networks. In this survey, we conduct a comprehensive survey on current deep graph representation learning algorithms by proposing a new taxonomy of existing state-of-the-art literature. Specifically, we systematically summarize the essential components of graph representation learning and categorize existing approaches by the ways of graph neural network architectures and the most recent advanced learning paradigms. Moreover, this survey also provides the practical and promising applications of deep graph representation learning. Last but not least, we state new perspectives and suggest challenging directions which deserve further investigations in the future.