 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpleFSDP: Simpler Fully Sharded Data Parallel with torch.compile
Nov 01, 2024

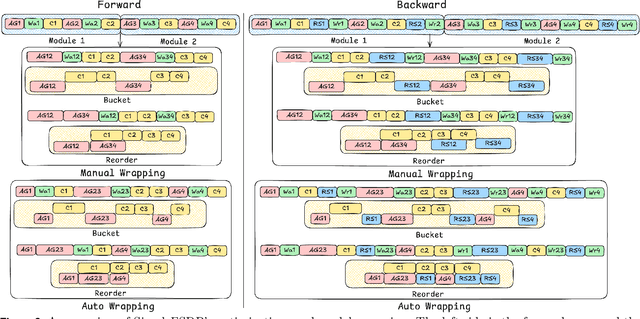
Distributed training of large models consumes enormous computation resources and requires substantial engineering efforts to compose various training techniques. This paper presents SimpleFSDP, a PyTorch-native compiler-based Fully Sharded Data Parallel (FSDP) framework, which has a simple implementation for maintenance and composability, allows full computation-communication graph tracing, and brings performance enhancement via compiler backend optimizations. SimpleFSDP's novelty lies in its unique torch.compile-friendly implementation of collective communications using existing PyTorch primitives, namely parametrizations, selective activation checkpointing, and DTensor. It also features the first-of-its-kind intermediate representation (IR) nodes bucketing and reordering in the TorchInductor backend for effective computation-communication overlapping. As a result, users can employ the aforementioned optimizations to automatically or manually wrap model components for minimal communication exposure. Extensive evaluations of SimpleFSDP on Llama 3 models (including the ultra-large 405B) using TorchTitan demonstrate up to 28.54% memory reduction and 68.67% throughput improvement compared to the most widely adopted FSDP2 eager framework, when composed with other distributed training techniques.
Aligning CodeLLMs with Direct Preference Optimization
Oct 24, 2024The last year has witnessed the rapid progress of large language models (LLMs) across diverse domains. Among them, CodeLLMs have garnered particular attention because they can not only assist in completing various programming tasks but also represent the decision-making and logical reasoning capabilities of LLMs. However, current CodeLLMs mainly focus on pre-training and supervised fine-tuning scenarios, leaving the alignment stage, which is important for post-training LLMs, under-explored. This work first identifies that the commonly used PPO algorithm may be suboptimal for the alignment of CodeLLM because the involved reward rules are routinely coarse-grained and potentially flawed. We then advocate addressing this using the DPO algorithm. Based on only preference data pairs, DPO can render the model rank data automatically, giving rise to a fine-grained rewarding pattern more robust than human intervention. We also contribute a pipeline for collecting preference pairs for DPO on CodeLLMs. Studies show that our method significantly improves the performance of existing CodeLLMs on benchmarks such as MBPP and HumanEval.
PGDiffSeg: Prior-Guided Denoising Diffusion Model with Parameter-Shared Attention for Breast Cancer Segmentation
Oct 23, 2024Early detection through imaging and accurate diagnosis is crucial in mitigating the high mortality rate associated with breast cancer. However, locating tumors from low-resolution and high-noise medical images is extremely challenging. Therefore, this paper proposes a novel PGDiffSeg (Prior-Guided Diffusion Denoising Model with Parameter-Shared Attention) that applies diffusion denoising methods to breast cancer medical image segmentation, accurately recovering the affected areas from Gaussian noise. Firstly, we design a parallel pipeline for noise processing and semantic information processing and propose a parameter-shared attention module (PSA) in multi-layer that seamlessly integrates these two pipelines. This integration empowers PGDiffSeg to incorporate semantic details at multiple levels during the denoising process, producing highly accurate segmentation maps. Secondly, we introduce a guided strategy that leverages prior knowledge to simulate the decision-making process of medical professionals, thereby enhancing the model's ability to locate tumor positions precisely. Finally, we provide the first-ever discussion on the interpretability of the generative diffusion model in the context of breast cancer segmentation. Extensive experiments have demonstrated the superiority of our model over the current state-of-the-art approaches, confirming its effectiveness as a flexible diffusion denoising method suitable for medical image research. Our code will be publicly available later.
Efficiently Computing Susceptibility to Context in Language Models
Oct 18, 2024One strength of modern language models is their ability to incorporate information from a user-input context when answering queries. However, they are not equally sensitive to the subtle changes to that context. To quantify this, Du et al. (2024) gives an information-theoretic metric to measure such sensitivity. Their metric, susceptibility, is defined as the degree to which contexts can influence a model's response to a query at a distributional level. However, exactly computing susceptibility is difficult and, thus, Du et al. (2024) falls back on a Monte Carlo approximation. Due to the large number of samples required, the Monte Carlo approximation is inefficient in practice. As a faster alternative, we propose Fisher susceptibility, an efficient method to estimate the susceptibility based on Fisher information. Empirically, we validate that Fisher susceptibility is comparable to Monte Carlo estimated susceptibility across a diverse set of query domains despite its being $70\times$ faster. Exploiting the improved efficiency, we apply Fisher susceptibility to analyze factors affecting the susceptibility of language models. We observe that larger models are as susceptible as smaller ones.
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Oct 10, 2024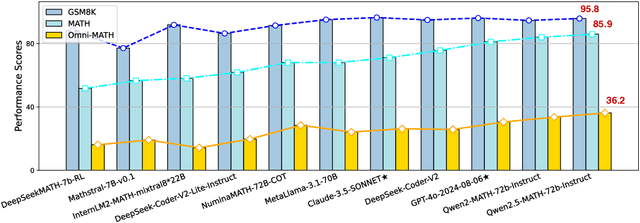

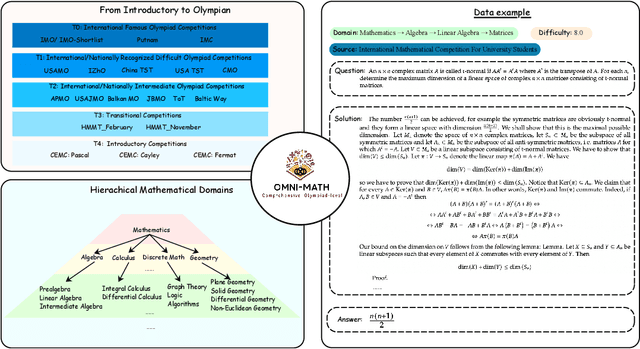
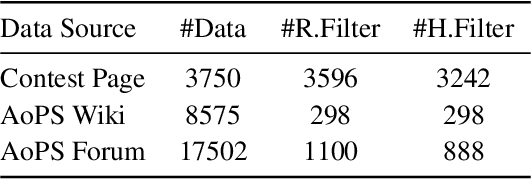
Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.
TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training
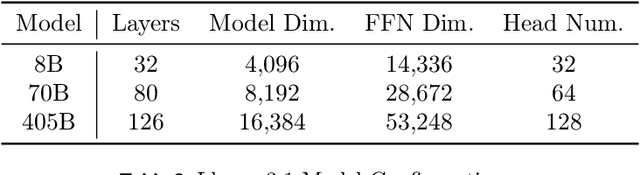
Oct 09, 2024The development of large language models (LLMs) has been instrumental in advancing state-of-the-art natural language processing applications. Training LLMs with billions of parameters and trillions of tokens require sophisticated distributed systems that enable composing and comparing several state-of-the-art techniques in order to efficiently scale across thousands of accelerators. However, existing solutions are complex, scattered across multiple libraries/repositories, lack interoperability, and are cumbersome to maintain. Thus, curating and empirically comparing training recipes require non-trivial engineering effort. This paper introduces TorchTitan, an open-source, PyTorch-native distributed training system that unifies state-of-the-art techniques, streamlining integration and reducing overhead. TorchTitan enables 3D parallelism in a modular manner with elastic scaling, providing comprehensive logging, checkpointing, and debugging tools for production-ready training. It also incorporates hardware-software co-designed solutions, leveraging features like Float8 training and SymmetricMemory. As a flexible test bed, TorchTitan facilitates custom recipe curation and comparison, allowing us to develop optimized training recipes for Llama 3.1 and provide guidance on selecting techniques for maximum efficiency based on our experiences. We thoroughly assess TorchTitan on the Llama 3.1 family of LLMs, spanning 8 billion to 405 billion parameters, and showcase its exceptional performance, modular composability, and elastic scalability. By stacking training optimizations, we demonstrate accelerations of 65.08% with 1D parallelism at the 128-GPU scale (Llama 3.1 8B), an additional 12.59% with 2D parallelism at the 256-GPU scale (Llama 3.1 70B), and an additional 30% with 3D parallelism at the 512-GPU scale (Llama 3.1 405B) on NVIDIA H100 GPUs over optimized baselines.
A Spark of Vision-Language Intelligence: 2-Dimensional Autoregressive Transformer for Efficient Finegrained Image Generation
Oct 02, 2024
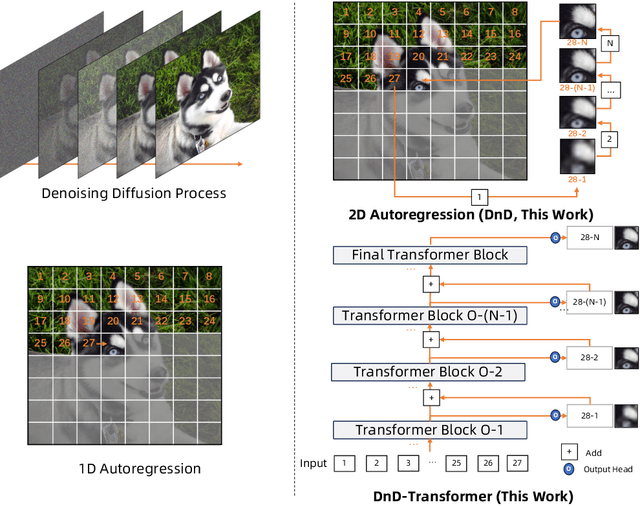
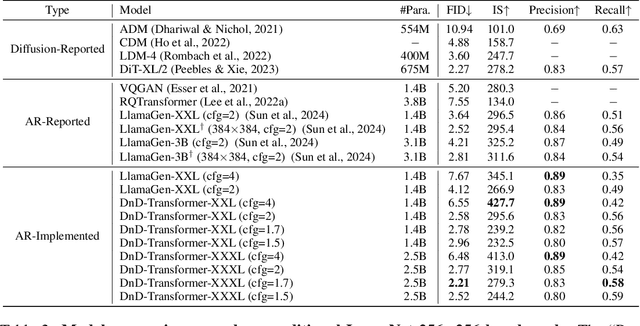

This work tackles the information loss bottleneck of vector-quantization (VQ) autoregressive image generation by introducing a novel model architecture called the 2-Dimensional Autoregression (DnD) Transformer. The DnD-Transformer predicts more codes for an image by introducing a new autoregression direction, \textit{model depth}, along with the sequence length direction. Compared to traditional 1D autoregression and previous work utilizing similar 2D image decomposition such as RQ-Transformer, the DnD-Transformer is an end-to-end model that can generate higher quality images with the same backbone model size and sequence length, opening a new optimization perspective for autoregressive image generation. Furthermore, our experiments reveal that the DnD-Transformer's potential extends beyond generating natural images. It can even generate images with rich text and graphical elements in a self-supervised manner, demonstrating an understanding of these combined modalities. This has not been previously demonstrated for popular vision generative models such as diffusion models, showing a spark of vision-language intelligence when trained solely on images. Code, datasets and models are open at https://github.com/chenllliang/DnD-Transformer.
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Sep 18, 2024In this report, we present a series of math-specific large language models: Qwen2.5-Math and Qwen2.5-Math-Instruct-1.5B/7B/72B. The core innovation of the Qwen2.5 series lies in integrating the philosophy of self-improvement throughout the entire pipeline, from pre-training and post-training to inference: (1) During the pre-training phase, Qwen2-Math-Instruct is utilized to generate large-scale, high-quality mathematical data. (2) In the post-training phase, we develop a reward model (RM) by conducting massive sampling from Qwen2-Math-Instruct. This RM is then applied to the iterative evolution of data in supervised fine-tuning (SFT). With a stronger SFT model, it's possible to iteratively train and update the RM, which in turn guides the next round of SFT data iteration. On the final SFT model, we employ the ultimate RM for reinforcement learning, resulting in the Qwen2.5-Math-Instruct. (3) Furthermore, during the inference stage, the RM is used to guide sampling, optimizing the model's performance. Qwen2.5-Math-Instruct supports both Chinese and English, and possess advanced mathematical reasoning capabilities, including Chain-of-Thought (CoT) and Tool-Integrated Reasoning (TIR). We evaluate our models on 10 mathematics datasets in both English and Chinese, such as GSM8K, MATH, GaoKao, AMC23, and AIME24, covering a range of difficulties from grade school level to math competition problems.
Qwen2.5-Coder Technical Report
Sep 18, 2024In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes two models: Qwen2.5-Coder-1.5B and Qwen2.5-Coder-7B. As a code-specific model, Qwen2.5-Coder is built upon the Qwen2.5 architecture and continues pretrained on a vast corpus of over 5.5 trillion tokens. Through meticulous data cleaning, scalable synthetic data generation, and balanced data mixing, Qwen2.5-Coder demonstrates impressive code generation capabilities while retaining general versatility. The model has been evaluated on a wide range of code-related tasks, achieving state-of-the-art (SOTA) performance across more than 10 benchmarks, including code generation, completion, reasoning, and repair, consistently outperforming larger models of the same model size. We believe that the release of the Qwen2.5-Coder series will not only push the boundaries of research in code intelligence but also, through its permissive licensing, encourage broader adoption by developers in real-world applications.
Towards a Unified View of Preference Learning for Large Language Models: A Survey
Sep 04, 2024Large Language Models (LLMs) exhibit remarkably powerful capabilities. One of the crucial factors to achieve success is aligning the LLM's output with human preferences. This alignment process often requires only a small amount of data to efficiently enhance the LLM's performance. While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment. In light of this, we break down the existing popular alignment strategies into different components and provide a unified framework to study the current alignment strategies, thereby establishing connections among them. In this survey, we decompose all the strategies in preference learning into four components: model, data, feedback, and algorithm. This unified view offers an in-depth understanding of existing alignment algorithms and also opens up possibilities to synergize the strengths of different strategies. Furthermore, we present detailed working examples of prevalent existing algorithms to facilitate a comprehensive understanding for the readers. Finally, based on our unified perspective, we explore the challenges and future research directions for aligning large language models with human preferences.