 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonsense Knowledge Editing Based on Free-Text in LLMs
Oct 31, 2024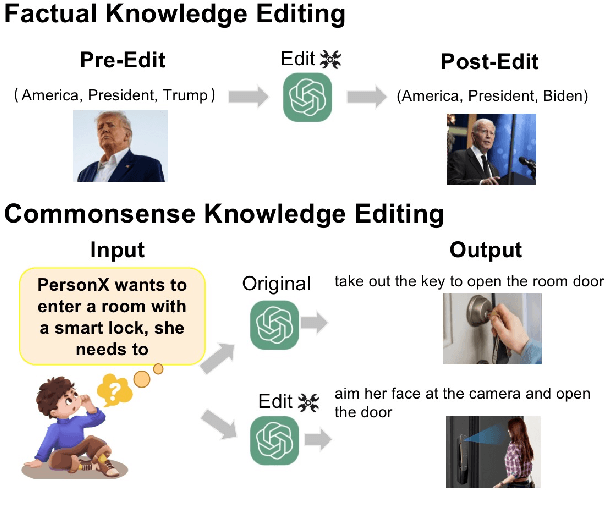

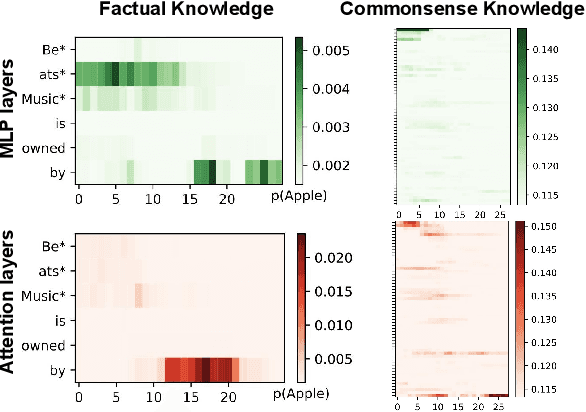
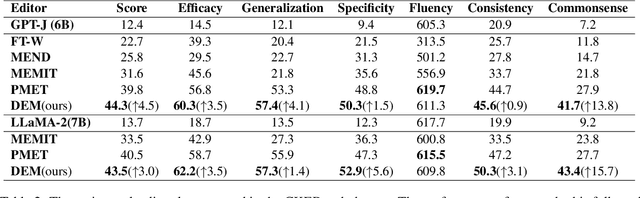
Knowledge editing technology is crucial for maintaining the accuracy and timeliness of large language models (LLMs) . However, the setting of this task overlooks a significant portion of commonsense knowledge based on free-text in the real world, characterized by broad knowledge scope, long content and non instantiation. The editing objects of previous methods (e.g., MEMIT) were single token or entity, which were not suitable for commonsense knowledge in free-text form. To address the aforementioned challenges, we conducted experiments from two perspectives: knowledge localization and knowledge editing. Firstly, we introduced Knowledge Localization for Free-Text(KLFT) method, revealing the challenges associated with the distribution of commonsense knowledge in MLP and Attention layers, as well as in decentralized distribution. Next, we propose a Dynamics-aware Editing Method(DEM), which utilizes a Dynamics-aware Module to locate the parameter positions corresponding to commonsense knowledge, and uses Knowledge Editing Module to update knowledge. The DEM method fully explores the potential of the MLP and Attention layers, and successfully edits commonsense knowledge based on free-text. The experimental results indicate that the DEM can achieve excellent editing performance.
* 11 pages, 8 figures
PGDiffSeg: Prior-Guided Denoising Diffusion Model with Parameter-Shared Attention for Breast Cancer Segmentation
Oct 23, 2024Early detection through imaging and accurate diagnosis is crucial in mitigating the high mortality rate associated with breast cancer. However, locating tumors from low-resolution and high-noise medical images is extremely challenging. Therefore, this paper proposes a novel PGDiffSeg (Prior-Guided Diffusion Denoising Model with Parameter-Shared Attention) that applies diffusion denoising methods to breast cancer medical image segmentation, accurately recovering the affected areas from Gaussian noise. Firstly, we design a parallel pipeline for noise processing and semantic information processing and propose a parameter-shared attention module (PSA) in multi-layer that seamlessly integrates these two pipelines. This integration empowers PGDiffSeg to incorporate semantic details at multiple levels during the denoising process, producing highly accurate segmentation maps. Secondly, we introduce a guided strategy that leverages prior knowledge to simulate the decision-making process of medical professionals, thereby enhancing the model's ability to locate tumor positions precisely. Finally, we provide the first-ever discussion on the interpretability of the generative diffusion model in the context of breast cancer segmentation. Extensive experiments have demonstrated the superiority of our model over the current state-of-the-art approaches, confirming its effectiveness as a flexible diffusion denoising method suitable for medical image research. Our code will be publicly available later.
A Troublemaker with Contagious Jailbreak Makes Chaos in Honest Towns
Oct 21, 2024With the development of large language models, they are widely used as agents in various fields. A key component of agents is memory, which stores vital information but is susceptible to jailbreak attacks. Existing research mainly focuses on single-agent attacks and shared memory attacks. However, real-world scenarios often involve independent memory. In this paper, we propose the Troublemaker Makes Chaos in Honest Town (TMCHT) task, a large-scale, multi-agent, multi-topology text-based attack evaluation framework. TMCHT involves one attacker agent attempting to mislead an entire society of agents. We identify two major challenges in multi-agent attacks: (1) Non-complete graph structure, (2) Large-scale systems. We attribute these challenges to a phenomenon we term toxicity disappearing. To address these issues, we propose an Adversarial Replication Contagious Jailbreak (ARCJ) method, which optimizes the retrieval suffix to make poisoned samples more easily retrieved and optimizes the replication suffix to make poisoned samples have contagious ability. We demonstrate the superiority of our approach in TMCHT, with 23.51%, 18.95%, and 52.93% improvements in line topology, star topology, and 100-agent settings. Encourage community attention to the security of multi-agent systems.
MIRAGE: Evaluating and Explaining Inductive Reasoning Process in Language Models
Oct 12, 2024Inductive reasoning is an essential capability for large language models (LLMs) to achieve higher intelligence, which requires the model to generalize rules from observed facts and then apply them to unseen examples. We present {\scshape Mirage}, a synthetic dataset that addresses the limitations of previous work, specifically the lack of comprehensive evaluation and flexible test data. In it, we evaluate LLMs' capabilities in both the inductive and deductive stages, allowing for flexible variation in input distribution, task scenario, and task difficulty to analyze the factors influencing LLMs' inductive reasoning. Based on these multi-faceted evaluations, we demonstrate that the LLM is a poor rule-based reasoner. In many cases, when conducting inductive reasoning, they do not rely on a correct rule to answer the unseen case. From the perspectives of different prompting methods, observation numbers, and task forms, models tend to consistently conduct correct deduction without correct inductive rules. Besides, we find that LLMs are good neighbor-based reasoners. In the inductive reasoning process, the model tends to focus on observed facts that are close to the current test example in feature space. By leveraging these similar examples, the model maintains strong inductive capabilities within a localized region, significantly improving its deductive performance.
LINKED: Eliciting, Filtering and Integrating Knowledge in Large Language Model for Commonsense Reasoning
Oct 12, 2024Large language models (LLMs) sometimes demonstrate poor performance on knowledge-intensive tasks, commonsense reasoning is one of them. Researchers typically address these issues by retrieving related knowledge from knowledge graphs or employing self-enhancement methods to elicit knowledge in LLMs. However, noisy knowledge and invalid reasoning issues hamper their ability to answer questions accurately. To this end, we propose a novel method named eliciting, filtering and integrating knowledge in large language model (LINKED). In it, we design a reward model to filter out the noisy knowledge and take the marginal consistent reasoning module to reduce invalid reasoning. With our comprehensive experiments on two complex commonsense reasoning benchmarks, our method outperforms SOTA baselines (up to 9.0% improvement of accuracy). Besides, to measure the positive and negative impact of the injected knowledge, we propose a new metric called effectiveness-preservation score for the knowledge enhancement works. Finally, through extensive experiments, we conduct an in-depth analysis and find many meaningful conclusions about LLMs in commonsense reasoning tasks.
DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models
Oct 09, 2024


We introduce DA-Code, a code generation benchmark specifically designed to assess LLMs on agent-based data science tasks. This benchmark features three core elements: First, the tasks within DA-Code are inherently challenging, setting them apart from traditional code generation tasks and demanding advanced coding skills in grounding and planning. Second, examples in DA-Code are all based on real and diverse data, covering a wide range of complex data wrangling and analytics tasks. Third, to solve the tasks, the models must utilize complex data science programming languages, to perform intricate data processing and derive the answers. We set up the benchmark in a controllable and executable environment that aligns with real-world data analysis scenarios and is scalable. The annotators meticulously design the evaluation suite to ensure the accuracy and robustness of the evaluation. We develop the DA-Agent baseline. Experiments show that although the baseline performs better than other existing frameworks, using the current best LLMs achieves only 30.5% accuracy, leaving ample room for improvement. We release our benchmark at [https://da-code-bench.github.io](https://da-code-bench.github.io).
Resource Allocation for Stable LLM Training in Mobile Edge Computing
Sep 30, 2024
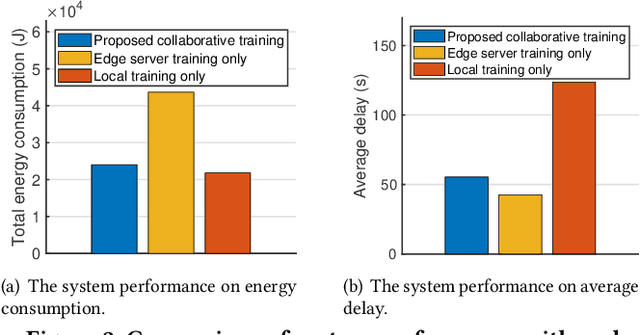

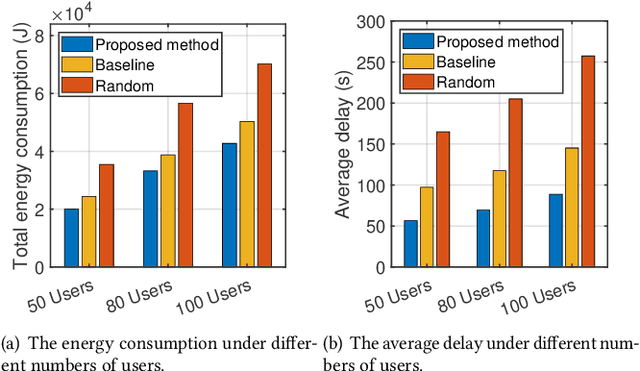
As mobile devices increasingly become focal points for advanced applications, edge computing presents a viable solution to their inherent computational limitations, particularly in deploying large language models (LLMs). However, despite the advancements in edge computing, significant challenges remain in efficient training and deploying LLMs due to the computational demands and data privacy concerns associated with these models. This paper explores a collaborative training framework that integrates mobile users with edge servers to optimize resource allocation, thereby enhancing both performance and efficiency. Our approach leverages parameter-efficient fine-tuning (PEFT) methods, allowing mobile users to adjust the initial layers of the LLM while edge servers handle the more demanding latter layers. Specifically, we formulate a multi-objective optimization problem to minimize the total energy consumption and delay during training. We also address the common issue of instability in model performance by incorporating stability enhancements into our objective function. Through novel fractional programming technique, we achieve a stationary point for the formulated problem. Simulations demonstrate that our method reduces the energy consumption as well as the latency, and increases the reliability of LLMs across various mobile settings.
JoyType: A Robust Design for Multilingual Visual Text Creation
Sep 26, 2024



Generating images with accurately represented text, especially in non-Latin languages, poses a significant challenge for diffusion models. Existing approaches, such as the integration of hint condition diagrams via auxiliary networks (e.g., ControlNet), have made strides towards addressing this issue. However, diffusion models often fall short in tasks requiring controlled text generation, such as specifying particular fonts or producing text in small fonts. In this paper, we introduce a novel approach for multilingual visual text creation, named JoyType, designed to maintain the font style of text during the image generation process. Our methodology begins with assembling a training dataset, JoyType-1M, comprising 1 million pairs of data. Each pair includes an image, its description, and glyph instructions corresponding to the font style within the image. We then developed a text control network, Font ControlNet, tasked with extracting font style information to steer the image generation. To further enhance our model's ability to maintain font style, notably in generating small-font text, we incorporated a multi-layer OCR-aware loss into the diffusion process. This enhancement allows JoyType to direct text rendering using low-level descriptors. Our evaluations, based on both visual and accuracy metrics, demonstrate that JoyType significantly outperforms existing state-of-the-art methods. Additionally, JoyType can function as a plugin, facilitating the creation of varied image styles in conjunction with other stable diffusion models on HuggingFace and CivitAI. Our project is open-sourced on https://jdh-algo.github.io/JoyType/.
MHAD: Multimodal Home Activity Dataset with Multi-Angle Videos and Synchronized Physiological Signals
Sep 14, 2024Video-based physiology, exemplified by remote photoplethysmography (rPPG), extracts physiological signals such as pulse and respiration by analyzing subtle changes in video recordings. This non-contact, real-time monitoring method holds great potential for home settings. Despite the valuable contributions of public benchmark datasets to this technology, there is currently no dataset specifically designed for passive home monitoring. Existing datasets are often limited to close-up, static, frontal recordings and typically include only 1-2 physiological signals. To advance video-based physiology in real home settings, we introduce the MHAD dataset. It comprises 1,440 videos from 40 subjects, capturing 6 typical activities from 3 angles in a real home environment. Additionally, 5 physiological signals were recorded, making it a comprehensive video-based physiology dataset. MHAD is compatible with the rPPG-toolbox and has been validated using several unsupervised and supervised methods. Our dataset is publicly available at https://github.com/jdh-algo/MHAD-Dataset.
Does Knowledge Localization Hold True? Surprising Differences Between Entity and Relation Perspectives in Language Models
Sep 01, 2024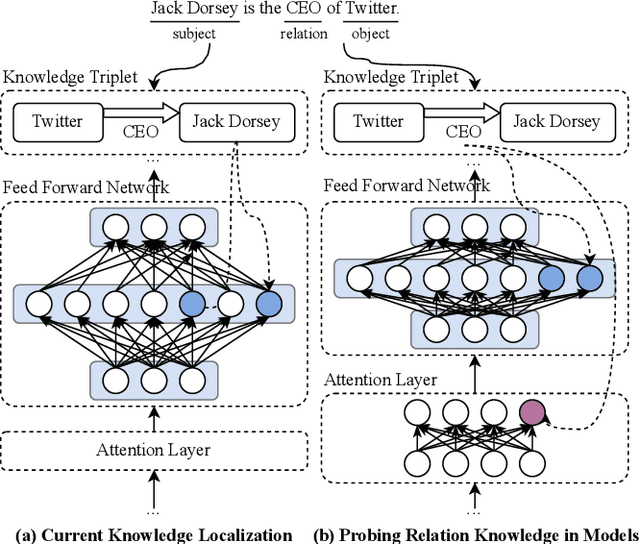
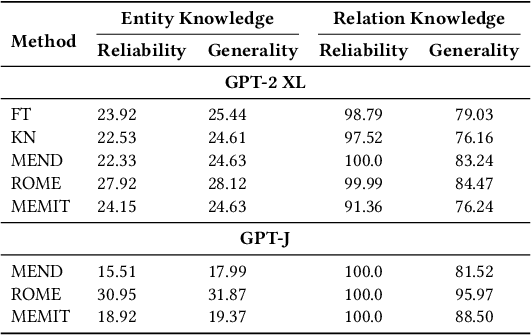

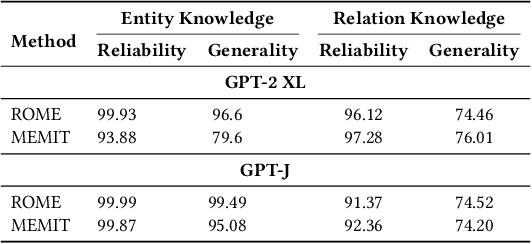
Large language models encapsulate knowledge and have demonstrated superior performance on various natural language processing tasks. Recent studies have localized this knowledge to specific model parameters, such as the MLP weights in intermediate layers. This study investigates the differences between entity and relational knowledge through knowledge editing. Our findings reveal that entity and relational knowledge cannot be directly transferred or mapped to each other. This result is unexpected, as logically, modifying the entity or the relation within the same knowledge triplet should yield equivalent outcomes. To further elucidate the differences between entity and relational knowledge, we employ causal analysis to investigate how relational knowledge is stored in pre-trained models. Contrary to prior research suggesting that knowledge is stored in MLP weights, our experiments demonstrate that relational knowledge is also significantly encoded in attention modules. This insight highlights the multifaceted nature of knowledge storage in language models, underscoring the complexity of manipulating specific types of knowledge within these models.