 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-view image geo-localization with Panorama-BEV Co-Retrieval Network
Aug 10, 2024Cross-view geolocalization identifies the geographic location of street view images by matching them with a georeferenced satellite database. Significant challenges arise due to the drastic appearance and geometry differences between views. In this paper, we propose a new approach for cross-view image geo-localization, i.e., the Panorama-BEV Co-Retrieval Network. Specifically, by utilizing the ground plane assumption and geometric relations, we convert street view panorama images into the BEV view, reducing the gap between street panoramas and satellite imagery. In the existing retrieval of street view panorama images and satellite images, we introduce BEV and satellite image retrieval branches for collaborative retrieval. By retaining the original street view retrieval branch, we overcome the limited perception range issue of BEV representation. Our network enables comprehensive perception of both the global layout and local details around the street view capture locations. Additionally, we introduce CVGlobal, a global cross-view dataset that is closer to real-world scenarios. This dataset adopts a more realistic setup, with street view directions not aligned with satellite images. CVGlobal also includes cross-regional, cross-temporal, and street view to map retrieval tests, enabling a comprehensive evaluation of algorithm performance. Our method excels in multiple tests on common cross-view datasets such as CVUSA, CVACT, VIGOR, and our newly introduced CVGlobal, surpassing the current state-of-the-art approaches. The code and datasets can be found at \url{https://github.com/yejy53/EP-BEV}.
SkyDiffusion: Street-to-Satellite Image Synthesis with Diffusion Models and BEV Paradigm
Aug 03, 2024Street-to-satellite image synthesis focuses on generating realistic satellite images from corresponding ground street-view images while maintaining a consistent content layout, similar to looking down from the sky. The significant differences in perspectives create a substantial domain gap between the views, making this cross-view generation task particularly challenging. In this paper, we introduce SkyDiffusion, a novel cross-view generation method for synthesizing satellite images from street-view images, leveraging diffusion models and Bird's Eye View (BEV) paradigm. First, we design a Curved-BEV method to transform street-view images to the satellite view, reformulating the challenging cross-domain image synthesis task into a conditional generation problem. Curved-BEV also includes a "Multi-to-One" mapping strategy for combining multiple street-view images within the same satellite coverage area, effectively solving the occlusion issues in dense urban scenes. Next, we design a BEV-controlled diffusion model to generate satellite images consistent with the street-view content, which also incorporates a light manipulation module to optimize the lighting condition of the synthesized image using a reference satellite. Experimental results demonstrate that SkyDiffusion outperforms state-of-the-art methods on both suburban (CVUSA & CVACT) and urban (VIGOR-Chicago) cross-view datasets, with an average SSIM increase of 14.5% and a FID reduction of 29.6%, achieving realistic and content-consistent satellite image generation. The code and models of this work will be released at https://opendatalab.github.io/skydiffusion/.
Haze-Aware Attention Network for Single-Image Dehazing
Jul 16, 2024Single-image dehazing is a pivotal challenge in computer vision that seeks to remove haze from images and restore clean background details. Recognizing the limitations of traditional physical model-based methods and the inefficiencies of current attention-based solutions, we propose a new dehazing network combining an innovative Haze-Aware Attention Module (HAAM) with a Multiscale Frequency Enhancement Module (MFEM). The HAAM is inspired by the atmospheric scattering model, thus skillfully integrating physical principles into high-dimensional features for targeted dehazing. It picks up on latent features during the image restoration process, which gives a significant boost to the metrics, while the MFEM efficiently enhances high-frequency details, thus sidestepping wavelet or Fourier transform complexities. It employs multiscale fields to extract and emphasize key frequency components with minimal parameter overhead. Integrated into a simple U-Net framework, our Haze-Aware Attention Network (HAA-Net) for single-image dehazing significantly outperforms existing attention-based and transformer models in efficiency and effectiveness. Tested across various public datasets, the HAA-Net sets new performance benchmarks. Our work not only advances the field of image dehazing but also offers insights into the design of attention mechanisms for broader applications in computer vision.
Vision Transformer with Key-select Routing Attention for Single Image Dehazing
Jun 28, 2024We present Ksformer, utilizing Multi-scale Key-select Routing Attention (MKRA) for intelligent selection of key areas through multi-channel, multi-scale windows with a top-k operator, and Lightweight Frequency Processing Module (LFPM) to enhance high-frequency features, outperforming other dehazing methods in tests.
Exploring Test-Time Adaptation for Object Detection in Continually Changing Environments
Jun 25, 2024For real-world applications, neural network models are commonly deployed in dynamic environments, where the distribution of the target domain undergoes temporal changes. Continual Test-Time Adaptation (CTTA) has recently emerged as a promising technique to gradually adapt a source-trained model to test data drawn from a continually changing target domain. Despite recent advancements in addressing CTTA, two critical issues remain: 1) The use of a fixed threshold for pseudo-labeling in existing methodologies leads to the generation of low-quality pseudo-labels, as model confidence varies across categories and domains; 2) While current solutions utilize stochastic parameter restoration to mitigate catastrophic forgetting, their capacity to preserve critical information is undermined by its intrinsic randomness. To tackle these challenges, we present CTAOD, aiming to enhance the performance of detection models in CTTA scenarios. Inspired by prior CTTA works for effective adaptation, CTAOD is founded on the mean-teacher framework, characterized by three core components. Firstly, the object-level contrastive learning module tailored for object detection extracts object-level features using the teacher's region of interest features and optimizes them through contrastive learning. Secondly, the dynamic threshold strategy updates the category-specific threshold based on predicted confidence scores to improve the quality of pseudo-labels. Lastly, we design a data-driven stochastic restoration mechanism to selectively reset inactive parameters using the gradients as weights for a random mask matrix, thereby ensuring the retention of essential knowledge. We demonstrate the effectiveness of our approach on four CTTA tasks for object detection, where CTAOD outperforms existing methods, especially achieving a 3.0 mAP improvement on the Cityscapes-to-Cityscapes-C CTTA task.
A$^{2}$-MAE: A spatial-temporal-spectral unified remote sensing pre-training method based on anchor-aware masked autoencoder
Jun 12, 2024
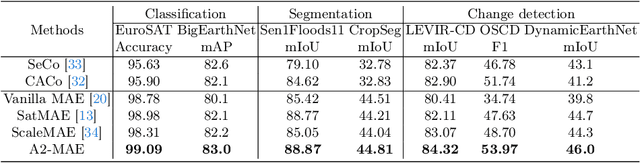


Vast amounts of remote sensing (RS) data provide Earth observations across multiple dimensions, encompassing critical spatial, temporal, and spectral information which is essential for addressing global-scale challenges such as land use monitoring, disaster prevention, and environmental change mitigation. Despite various pre-training methods tailored to the characteristics of RS data, a key limitation persists: the inability to effectively integrate spatial, temporal, and spectral information within a single unified model. To unlock the potential of RS data, we construct a Spatial-Temporal-Spectral Structured Dataset (STSSD) characterized by the incorporation of multiple RS sources, diverse coverage, unified locations within image sets, and heterogeneity within images. Building upon this structured dataset, we propose an Anchor-Aware Masked AutoEncoder method (A$^{2}$-MAE), leveraging intrinsic complementary information from the different kinds of images and geo-information to reconstruct the masked patches during the pre-training phase. A$^{2}$-MAE integrates an anchor-aware masking strategy and a geographic encoding module to comprehensively exploit the properties of RS images. Specifically, the proposed anchor-aware masking strategy dynamically adapts the masking process based on the meta-information of a pre-selected anchor image, thereby facilitating the training on images captured by diverse types of RS sources within one model. Furthermore, we propose a geographic encoding method to leverage accurate spatial patterns, enhancing the model generalization capabilities for downstream applications that are generally location-related. Extensive experiments demonstrate our method achieves comprehensive improvements across various downstream tasks compared with existing RS pre-training methods, including image classification, semantic segmentation, and change detection tasks.
Parallel Cross Strip Attention Network for Single Image Dehazing
May 09, 2024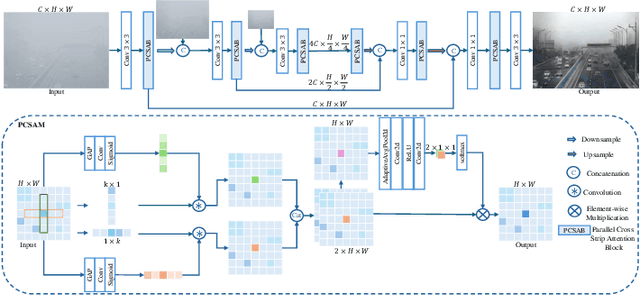


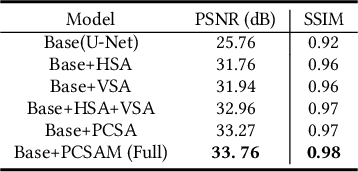
The objective of single image dehazing is to restore hazy images and produce clear, high-quality visuals. Traditional convolutional models struggle with long-range dependencies due to their limited receptive field size. While Transformers excel at capturing such dependencies, their quadratic computational complexity in relation to feature map resolution makes them less suitable for pixel-to-pixel dense prediction tasks. Moreover, fixed kernels or tokens in most models do not adapt well to varying blur sizes, resulting in suboptimal dehazing performance. In this study, we introduce a novel dehazing network based on Parallel Stripe Cross Attention (PCSA) with a multi-scale strategy. PCSA efficiently integrates long-range dependencies by simultaneously capturing horizontal and vertical relationships, allowing each pixel to capture contextual cues from an expanded spatial domain. To handle different sizes and shapes of blurs flexibly, We employs a channel-wise design with varying convolutional kernel sizes and strip lengths in each PCSA to capture context information at different scales.Additionally, we incorporate a softmax-based adaptive weighting mechanism within PCSA to prioritize and leverage more critical features.
3D Building Reconstruction from Monocular Remote Sensing Images with Multi-level Supervisions
Apr 07, 2024
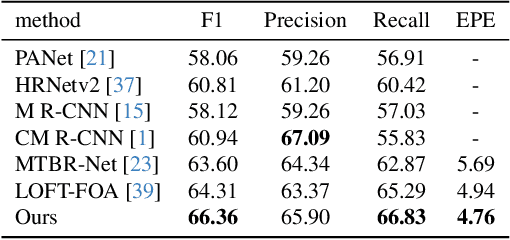


3D building reconstruction from monocular remote sensing images is an important and challenging research problem that has received increasing attention in recent years, owing to its low cost of data acquisition and availability for large-scale applications. However, existing methods rely on expensive 3D-annotated samples for fully-supervised training, restricting their application to large-scale cross-city scenarios. In this work, we propose MLS-BRN, a multi-level supervised building reconstruction network that can flexibly utilize training samples with different annotation levels to achieve better reconstruction results in an end-to-end manner. To alleviate the demand on full 3D supervision, we design two new modules, Pseudo Building Bbox Calculator and Roof-Offset guided Footprint Extractor, as well as new tasks and training strategies for different types of samples. Experimental results on several public and new datasets demonstrate that our proposed MLS-BRN achieves competitive performance using much fewer 3D-annotated samples, and significantly improves the footprint extraction and 3D reconstruction performance compared with current state-of-the-art. The code and datasets of this work will be released at https://github.com/opendatalab/MLS-BRN.git.
SG-BEV: Satellite-Guided BEV Fusion for Cross-View Semantic Segmentation
Apr 03, 2024This paper aims at achieving fine-grained building attribute segmentation in a cross-view scenario, i.e., using satellite and street-view image pairs. The main challenge lies in overcoming the significant perspective differences between street views and satellite views. In this work, we introduce SG-BEV, a novel approach for satellite-guided BEV fusion for cross-view semantic segmentation. To overcome the limitations of existing cross-view projection methods in capturing the complete building facade features, we innovatively incorporate Bird's Eye View (BEV) method to establish a spatially explicit mapping of street-view features. Moreover, we fully leverage the advantages of multiple perspectives by introducing a novel satellite-guided reprojection module, optimizing the uneven feature distribution issues associated with traditional BEV methods. Our method demonstrates significant improvements on four cross-view datasets collected from multiple cities, including New York, San Francisco, and Boston. On average across these datasets, our method achieves an increase in mIOU by 10.13% and 5.21% compared with the state-of-the-art satellite-based and cross-view methods. The code and datasets of this work will be released at https://github.com/yejy53/SG-BEV.
H2RSVLM: Towards Helpful and Honest Remote Sensing Large Vision Language Model
Mar 29, 2024
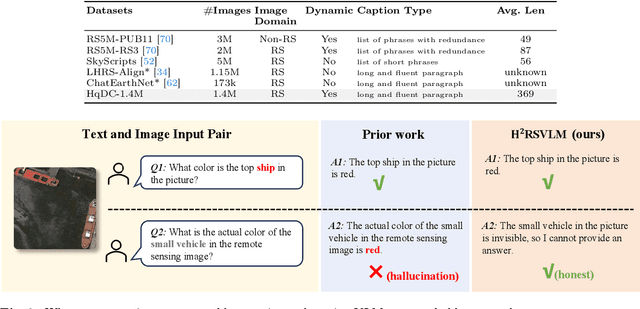


The generic large Vision-Language Models (VLMs) is rapidly developing, but still perform poorly in Remote Sensing (RS) domain, which is due to the unique and specialized nature of RS imagery and the comparatively limited spatial perception of current VLMs. Existing Remote Sensing specific Vision Language Models (RSVLMs) still have considerable potential for improvement, primarily owing to the lack of large-scale, high-quality RS vision-language datasets. We constructed HqDC-1.4M, the large scale High quality and Detailed Captions for RS images, containing 1.4 million image-caption pairs, which not only enhance the RSVLM's understanding of RS images but also significantly improve the model's spatial perception abilities, such as localization and counting, thereby increasing the helpfulness of the RSVLM. Moreover, to address the inevitable "hallucination" problem in RSVLM, we developed RSSA, the first dataset aimed at enhancing the Self-Awareness capability of RSVLMs. By incorporating a variety of unanswerable questions into typical RS visual question-answering tasks, RSSA effectively improves the truthfulness and reduces the hallucinations of the model's outputs, thereby enhancing the honesty of the RSVLM. Based on these datasets, we proposed the H2RSVLM, the Helpful and Honest Remote Sensing Vision Language Model. H2RSVLM has achieved outstanding performance on multiple RS public datasets and is capable of recognizing and refusing to answer the unanswerable questions, effectively mitigating the incorrect generations. We will release the code, data and model weights at https://github.com/opendatalab/H2RSVLM .