 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRichelieu: Self-Evolving LLM-Based Agents for AI Diplomacy
Jul 09, 2024
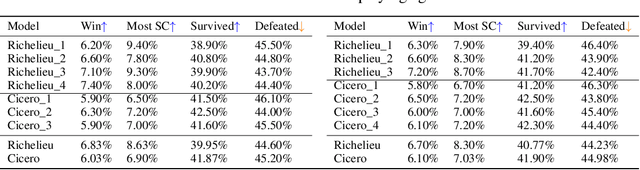


Diplomacy is one of the most sophisticated activities in human society. The complex interactions among multiple parties/ agents involve various abilities like social reasoning, negotiation arts, and long-term strategy planning. Previous AI agents surely have proved their capability of handling multi-step games and larger action spaces on tasks involving multiple agents. However, diplomacy involves a staggering magnitude of decision spaces, especially considering the negotiation stage required. Recently, LLM agents have shown their potential for extending the boundary of previous agents on a couple of applications, however, it is still not enough to handle a very long planning period in a complex multi-agent environment. Empowered with cutting-edge LLM technology, we make the first stab to explore AI's upper bound towards a human-like agent for such a highly comprehensive multi-agent mission by combining three core and essential capabilities for stronger LLM-based societal agents: 1) strategic planner with memory and reflection; 2) goal-oriented negotiate with social reasoning; 3) augmenting memory by self-play games to self-evolving without any human in the loop.
Aligning Human Motion Generation with Human Perceptions
Jul 02, 2024
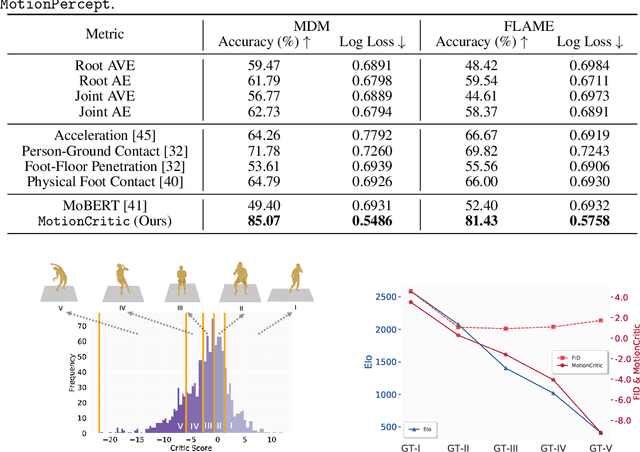


Human motion generation is a critical task with a wide range of applications. Achieving high realism in generated motions requires naturalness, smoothness, and plausibility. Despite rapid advancements in the field, current generation methods often fall short of these goals. Furthermore, existing evaluation metrics typically rely on ground-truth-based errors, simple heuristics, or distribution distances, which do not align well with human perceptions of motion quality. In this work, we propose a data-driven approach to bridge this gap by introducing a large-scale human perceptual evaluation dataset, MotionPercept, and a human motion critic model, MotionCritic, that capture human perceptual preferences. Our critic model offers a more accurate metric for assessing motion quality and could be readily integrated into the motion generation pipeline to enhance generation quality. Extensive experiments demonstrate the effectiveness of our approach in both evaluating and improving the quality of generated human motions by aligning with human perceptions. Code and data are publicly available at https://motioncritic.github.io/.
Through the Theory of Mind's Eye: Reading Minds with Multimodal Video Large Language Models
Jun 19, 2024Can large multimodal models have a human-like ability for emotional and social reasoning, and if so, how does it work? Recent research has discovered emergent theory-of-mind (ToM) reasoning capabilities in large language models (LLMs). LLMs can reason about people's mental states by solving various text-based ToM tasks that ask questions about the actors' ToM (e.g., human belief, desire, intention). However, human reasoning in the wild is often grounded in dynamic scenes across time. Thus, we consider videos a new medium for examining spatio-temporal ToM reasoning ability. Specifically, we ask explicit probing questions about videos with abundant social and emotional reasoning content. We develop a pipeline for multimodal LLM for ToM reasoning using video and text. We also enable explicit ToM reasoning by retrieving key frames for answering a ToM question, which reveals how multimodal LLMs reason about ToM.
Bayesian Intervention Optimization for Causal Discovery
Jun 16, 2024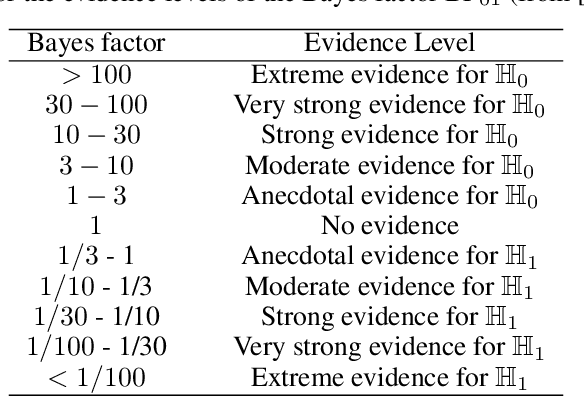
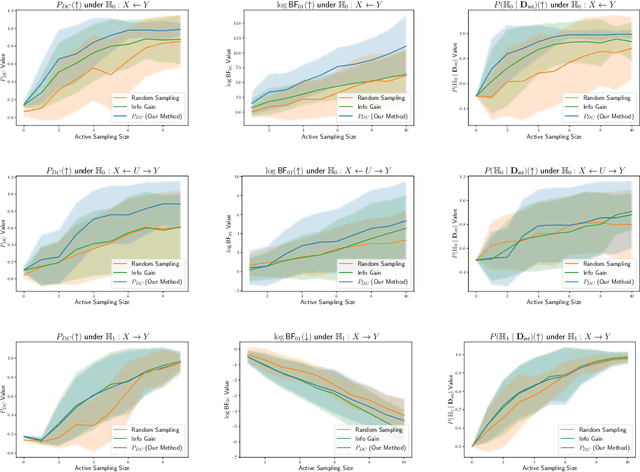
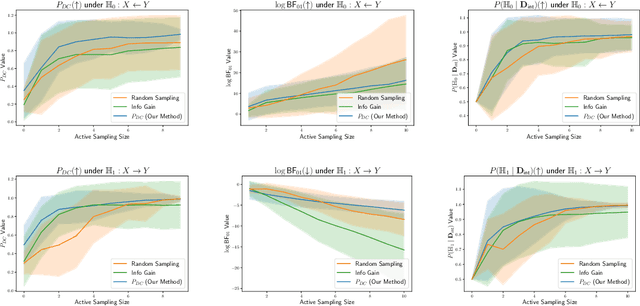

Causal discovery is crucial for understanding complex systems and informing decisions. While observational data can uncover causal relationships under certain assumptions, it often falls short, making active interventions necessary. Current methods, such as Bayesian and graph-theoretical approaches, do not prioritize decision-making and often rely on ideal conditions or information gain, which is not directly related to hypothesis testing. We propose a novel Bayesian optimization-based method inspired by Bayes factors that aims to maximize the probability of obtaining decisive and correct evidence. Our approach uses observational data to estimate causal models under different hypotheses, evaluates potential interventions pre-experimentally, and iteratively updates priors to refine interventions. We demonstrate the effectiveness of our method through various experiments. Our contributions provide a robust framework for efficient causal discovery through active interventions, enhancing the practical application of theoretical advancements.
CLoG: Benchmarking Continual Learning of Image Generation Models
Jun 07, 2024
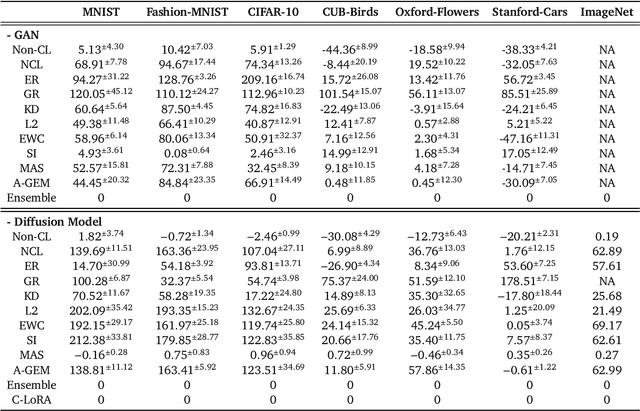

Continual Learning (CL) poses a significant challenge in Artificial Intelligence, aiming to mirror the human ability to incrementally acquire knowledge and skills. While extensive research has focused on CL within the context of classification tasks, the advent of increasingly powerful generative models necessitates the exploration of Continual Learning of Generative models (CLoG). This paper advocates for shifting the research focus from classification-based CL to CLoG. We systematically identify the unique challenges presented by CLoG compared to traditional classification-based CL. We adapt three types of existing CL methodologies, replay-based, regularization-based, and parameter-isolation-based methods to generative tasks and introduce comprehensive benchmarks for CLoG that feature great diversity and broad task coverage. Our benchmarks and results yield intriguing insights that can be valuable for developing future CLoG methods. Additionally, we will release a codebase designed to facilitate easy benchmarking and experimentation in CLoG publicly at https://github.com/linhaowei1/CLoG. We believe that shifting the research focus to CLoG will benefit the continual learning community and illuminate the path for next-generation AI-generated content (AIGC) in a lifelong learning paradigm.
Cross-Dimensional Medical Self-Supervised Representation Learning Based on a Pseudo-3D Transformation
Jun 03, 2024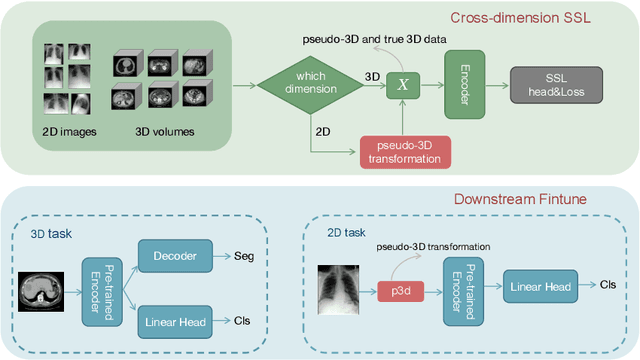
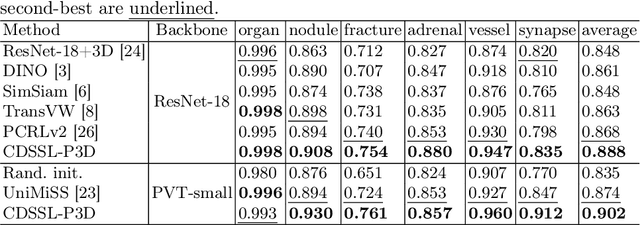

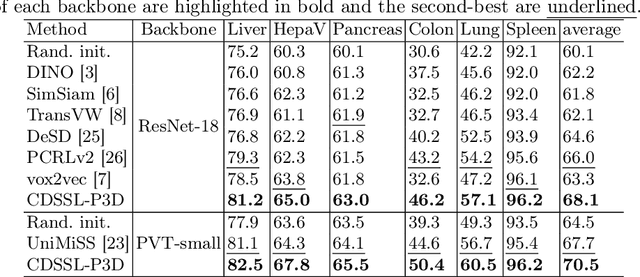
Medical image analysis suffers from a shortage of data, whether annotated or not. This becomes even more pronounced when it comes to 3D medical images. Self-Supervised Learning (SSL) can partially ease this situation by using unlabeled data. However, most existing SSL methods can only make use of data in a single dimensionality (e.g. 2D or 3D), and are incapable of enlarging the training dataset by using data with differing dimensionalities jointly. In this paper, we propose a new cross-dimensional SSL framework based on a pseudo-3D transformation (CDSSL-P3D), that can leverage both 2D and 3D data for joint pre-training. Specifically, we introduce an image transformation based on the im2col algorithm, which converts 2D images into a format consistent with 3D data. This transformation enables seamless integration of 2D and 3D data, and facilitates cross-dimensional self-supervised learning for 3D medical image analysis. We run extensive experiments on 13 downstream tasks, including 2D and 3D classification and segmentation. The results indicate that our CDSSL-P3D achieves superior performance, outperforming other advanced SSL methods.
Instruct-ReID++: Towards Universal Purpose Instruction-Guided Person Re-identification
May 28, 2024



Human intelligence can retrieve any person according to both visual and language descriptions. However, the current computer vision community studies specific person re-identification (ReID) tasks in different scenarios separately, which limits the applications in the real world. This paper strives to resolve this problem by proposing a novel instruct-ReID task that requires the model to retrieve images according to the given image or language instructions. Instruct-ReID is the first exploration of a general ReID setting, where existing 6 ReID tasks can be viewed as special cases by assigning different instructions. To facilitate research in this new instruct-ReID task, we propose a large-scale OmniReID++ benchmark equipped with diverse data and comprehensive evaluation methods e.g., task specific and task-free evaluation settings. In the task-specific evaluation setting, gallery sets are categorized according to specific ReID tasks. We propose a novel baseline model, IRM, with an adaptive triplet loss to handle various retrieval tasks within a unified framework. For task-free evaluation setting, where target person images are retrieved from task-agnostic gallery sets, we further propose a new method called IRM++ with novel memory bank-assisted learning. Extensive evaluations of IRM and IRM++ on OmniReID++ benchmark demonstrate the superiority of our proposed methods, achieving state-of-the-art performance on 10 test sets. The datasets, the model, and the code will be available at https://github.com/hwz-zju/Instruct-ReID
SocialGFs: Learning Social Gradient Fields for Multi-Agent Reinforcement Learning
May 03, 2024Multi-agent systems (MAS) need to adaptively cope with dynamic environments, changing agent populations, and diverse tasks. However, most of the multi-agent systems cannot easily handle them, due to the complexity of the state and task space. The social impact theory regards the complex influencing factors as forces acting on an agent, emanating from the environment, other agents, and the agent's intrinsic motivation, referring to the social force. Inspired by this concept, we propose a novel gradient-based state representation for multi-agent reinforcement learning. To non-trivially model the social forces, we further introduce a data-driven method, where we employ denoising score matching to learn the social gradient fields (SocialGFs) from offline samples, e.g., the attractive or repulsive outcomes of each force. During interactions, the agents take actions based on the multi-dimensional gradients to maximize their own rewards. In practice, we integrate SocialGFs into the widely used multi-agent reinforcement learning algorithms, e.g., MAPPO. The empirical results reveal that SocialGFs offer four advantages for multi-agent systems: 1) they can be learned without requiring online interaction, 2) they demonstrate transferability across diverse tasks, 3) they facilitate credit assignment in challenging reward settings, and 4) they are scalable with the increasing number of agents.
The 8th AI City Challenge
Apr 15, 2024The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
Rewrite the Stars
Mar 29, 2024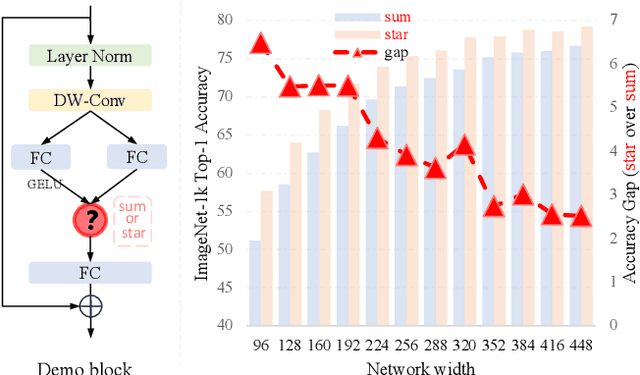

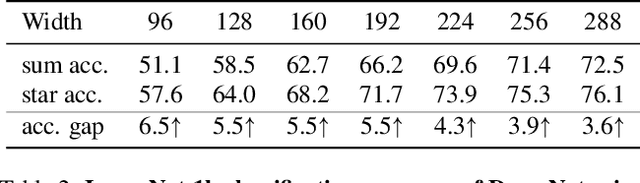

Recent studies have drawn attention to the untapped potential of the "star operation" (element-wise multiplication) in network design. While intuitive explanations abound, the foundational rationale behind its application remains largely unexplored. Our study attempts to reveal the star operation's ability to map inputs into high-dimensional, non-linear feature spaces -- akin to kernel tricks -- without widening the network. We further introduce StarNet, a simple yet powerful prototype, demonstrating impressive performance and low latency under compact network structure and efficient budget. Like stars in the sky, the star operation appears unremarkable but holds a vast universe of potential. Our work encourages further exploration across tasks, with codes available at https://github.com/ma-xu/Rewrite-the-Stars.