 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Solution to Connect Speech Encoder and Large Language Model for ASR
Jun 25, 2024Recent works have shown promising results in connecting speech encoders to large language models (LLMs) for speech recognition. However, several limitations persist, including limited fine-tuning options, a lack of mechanisms to enforce speech-text alignment, and high insertion errors especially in domain mismatch conditions. This paper presents a comprehensive solution to address these issues. We begin by investigating more thoughtful fine-tuning schemes. Next, we propose a matching loss to enhance alignment between modalities. Finally, we explore training and inference methods to mitigate high insertion errors. Experimental results on the Librispeech corpus demonstrate that partially fine-tuning the encoder and LLM using parameter-efficient methods, such as LoRA, is the most cost-effective approach. Additionally, the matching loss improves modality alignment, enhancing performance. The proposed training and inference methods significantly reduce insertion errors.
VideoHallucer: Evaluating Intrinsic and Extrinsic Hallucinations in Large Video-Language Models
Jun 24, 2024Recent advancements in Multimodal Large Language Models (MLLMs) have extended their capabilities to video understanding. Yet, these models are often plagued by "hallucinations", where irrelevant or nonsensical content is generated, deviating from the actual video context. This work introduces VideoHallucer, the first comprehensive benchmark for hallucination detection in large video-language models (LVLMs). VideoHallucer categorizes hallucinations into two main types: intrinsic and extrinsic, offering further subcategories for detailed analysis, including object-relation, temporal, semantic detail, extrinsic factual, and extrinsic non-factual hallucinations. We adopt an adversarial binary VideoQA method for comprehensive evaluation, where pairs of basic and hallucinated questions are crafted strategically. By evaluating eleven LVLMs on VideoHallucer, we reveal that i) the majority of current models exhibit significant issues with hallucinations; ii) while scaling datasets and parameters improves models' ability to detect basic visual cues and counterfactuals, it provides limited benefit for detecting extrinsic factual hallucinations; iii) existing models are more adept at detecting facts than identifying hallucinations. As a byproduct, these analyses further instruct the development of our self-PEP framework, achieving an average of 5.38% improvement in hallucination resistance across all model architectures.
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Jun 22, 2024Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Jun 19, 2024Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
Bayesian Intervention Optimization for Causal Discovery
Jun 16, 2024Causal discovery is crucial for understanding complex systems and informing decisions. While observational data can uncover causal relationships under certain assumptions, it often falls short, making active interventions necessary. Current methods, such as Bayesian and graph-theoretical approaches, do not prioritize decision-making and often rely on ideal conditions or information gain, which is not directly related to hypothesis testing. We propose a novel Bayesian optimization-based method inspired by Bayes factors that aims to maximize the probability of obtaining decisive and correct evidence. Our approach uses observational data to estimate causal models under different hypotheses, evaluates potential interventions pre-experimentally, and iteratively updates priors to refine interventions. We demonstrate the effectiveness of our method through various experiments. Our contributions provide a robust framework for efficient causal discovery through active interventions, enhancing the practical application of theoretical advancements.
Dual-Pipeline with Low-Rank Adaptation for New Language Integration in Multilingual ASR
Jun 12, 2024This paper addresses challenges in integrating new languages into a pre-trained multilingual automatic speech recognition (mASR) system, particularly in scenarios where training data for existing languages is limited or unavailable. The proposed method employs a dual-pipeline with low-rank adaptation (LoRA). It maintains two data flow pipelines-one for existing languages and another for new languages. The primary pipeline follows the standard flow through the pre-trained parameters of mASR, while the secondary pipeline additionally utilizes language-specific parameters represented by LoRA and a separate output decoder module. Importantly, the proposed approach minimizes the performance degradation of existing languages and enables a language-agnostic operation mode, facilitated by a decoder selection strategy. We validate the effectiveness of the proposed method by extending the pre-trained Whisper model to 19 new languages from the FLEURS dataset
Can Large Language Models Understand Spatial Audio?
Jun 12, 2024This paper explores enabling large language models (LLMs) to understand spatial information from multichannel audio, a skill currently lacking in auditory LLMs. By leveraging LLMs' advanced cognitive and inferential abilities, the aim is to enhance understanding of 3D environments via audio. We study 3 spatial audio tasks: sound source localization (SSL), far-field speech recognition (FSR), and localisation-informed speech extraction (LSE), achieving notable progress in each task. For SSL, our approach achieves an MAE of $2.70^{\circ}$ on the Spatial LibriSpeech dataset, substantially surpassing the prior benchmark of about $6.60^{\circ}$. Moreover, our model can employ spatial cues to improve FSR accuracy and execute LSE by selectively attending to sounds originating from a specified direction via text prompts, even amidst overlapping speech. These findings highlight the potential of adapting LLMs to grasp physical audio concepts, paving the way for LLM-based agents in 3D environments.
Progressive Confident Masking Attention Network for Audio-Visual Segmentation
Jun 04, 2024Audio and visual signals typically occur simultaneously, and humans possess an innate ability to correlate and synchronize information from these two modalities. Recently, a challenging problem known as Audio-Visual Segmentation (AVS) has emerged, intending to produce segmentation maps for sounding objects within a scene. However, the methods proposed so far have not sufficiently integrated audio and visual information, and the computational costs have been extremely high. Additionally, the outputs of different stages have not been fully utilized. To facilitate this research, we introduce a novel Progressive Confident Masking Attention Network (PMCANet). It leverages attention mechanisms to uncover the intrinsic correlations between audio signals and visual frames. Furthermore, we design an efficient and effective cross-attention module to enhance semantic perception by selecting query tokens. This selection is determined through confidence-driven units based on the network's multi-stage predictive outputs. Experiments demonstrate that our network outperforms other AVS methods while requiring less computational resources.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
Human-Centered LLM-Agent User Interface: A Position Paper
May 19, 2024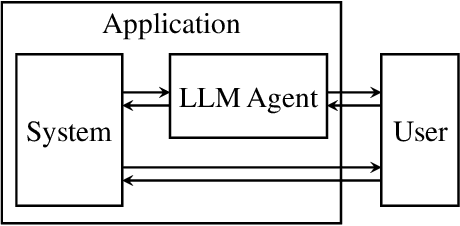


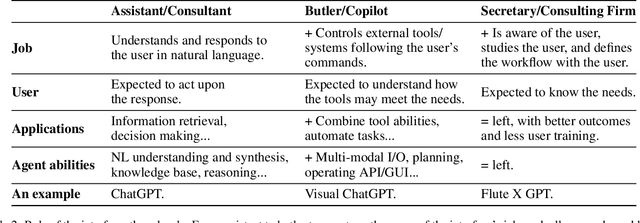
Large Language Model (LLM) -in-the-loop applications have been shown to effectively interpret the human user's commands, make plans, and operate external tools/systems accordingly. Still, the operation scope of the LLM agent is limited to passively following the user, requiring the user to frame his/her needs with regard to the underlying tools/systems. We note that the potential of an LLM-Agent User Interface (LAUI) is much greater. A user mostly ignorant to the underlying tools/systems should be able to work with a LAUI to discover an emergent workflow. Contrary to the conventional way of designing an explorable GUI to teach the user a predefined set of ways to use the system, in the ideal LAUI, the LLM agent is initialized to be proficient with the system, proactively studies the user and his/her needs, and proposes new interaction schemes to the user. To illustrate LAUI, we present Flute X GPT, a concrete example using an LLM agent, a prompt manager, and a flute-tutoring multi-modal software-hardware system to facilitate the complex, real-time user experience of learning to play the flute.