 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation
Jul 07, 2024Recently, speech generation models have made significant progress by using large-scale training data. However, the research community struggle to produce highly spontaneous and human-like speech due to the lack of large-scale, diverse, and spontaneous speech data. This paper presents \textit{Emilia}, the first multilingual speech generation dataset from in-the-wild speech data, and Emilia-Pipe, the first open-source preprocessing pipeline designed to transform in-the-wild speech data into high-quality training data with annotations for speech generation. Emilia starts with over 101k hours of speech in six languages and features diverse speech with varied speaking styles. To facilitate the scale-up of Emilia, the open-source pipeline Emilia-Pipe can process one hour of raw speech data ready for model training in a few mins, which enables the research community to collaborate on large-scale speech generation research. Experimental results validate the effectiveness of Emilia. Demos are available at: https://emilia-dataset.github.io/Emilia-Demo-Page/.
PicoAudio: Enabling Precise Timestamp and Frequency Controllability of Audio Events in Text-to-audio Generation
Jul 03, 2024Recently, audio generation tasks have attracted considerable research interests. Precise temporal controllability is essential to integrate audio generation with real applications. In this work, we propose a temporal controlled audio generation framework, PicoAudio. PicoAudio integrates temporal information to guide audio generation through tailored model design. It leverages data crawling, segmentation, filtering, and simulation of fine-grained temporally-aligned audio-text data. Both subjective and objective evaluations demonstrate that PicoAudio dramantically surpasses current state-of-the-art generation models in terms of timestamp and occurrence frequency controllability. The generated samples are available on the demo website https://PicoAudio.github.io.
AudioTime: A Temporally-aligned Audio-text Benchmark Dataset
Jul 03, 2024Recent advancements in audio generation have enabled the creation of high-fidelity audio clips from free-form textual descriptions. However, temporal relationships, a critical feature for audio content, are currently underrepresented in mainstream models, resulting in an imprecise temporal controllability. Specifically, users cannot accurately control the timestamps of sound events using free-form text. We acknowledge that a significant factor is the absence of high-quality, temporally-aligned audio-text datasets, which are essential for training models with temporal control. The more temporally-aligned the annotations, the better the models can understand the precise relationship between audio outputs and temporal textual prompts. Therefore, we present a strongly aligned audio-text dataset, AudioTime. It provides text annotations rich in temporal information such as timestamps, duration, frequency, and ordering, covering almost all aspects of temporal control. Additionally, we offer a comprehensive test set and evaluation metric to assess the temporal control performance of various models. Examples are available on the https://zeyuxie29.github.io/AudioTime/
FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds
Jul 01, 2024We study Neural Foley, the automatic generation of high-quality sound effects synchronizing with videos, enabling an immersive audio-visual experience. Despite its wide range of applications, existing approaches encounter limitations when it comes to simultaneously synthesizing high-quality and video-aligned (i.e.,, semantic relevant and temporal synchronized) sounds. To overcome these limitations, we propose FoleyCrafter, a novel framework that leverages a pre-trained text-to-audio model to ensure high-quality audio generation. FoleyCrafter comprises two key components: the semantic adapter for semantic alignment and the temporal controller for precise audio-video synchronization. The semantic adapter utilizes parallel cross-attention layers to condition audio generation on video features, producing realistic sound effects that are semantically relevant to the visual content. Meanwhile, the temporal controller incorporates an onset detector and a timestampbased adapter to achieve precise audio-video alignment. One notable advantage of FoleyCrafter is its compatibility with text prompts, enabling the use of text descriptions to achieve controllable and diverse video-to-audio generation according to user intents. We conduct extensive quantitative and qualitative experiments on standard benchmarks to verify the effectiveness of FoleyCrafter. Models and codes are available at https://github.com/open-mmlab/FoleyCrafter.
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Jun 19, 2024
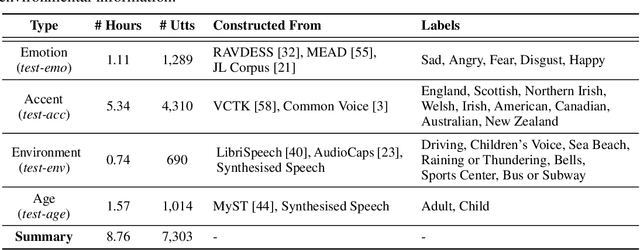
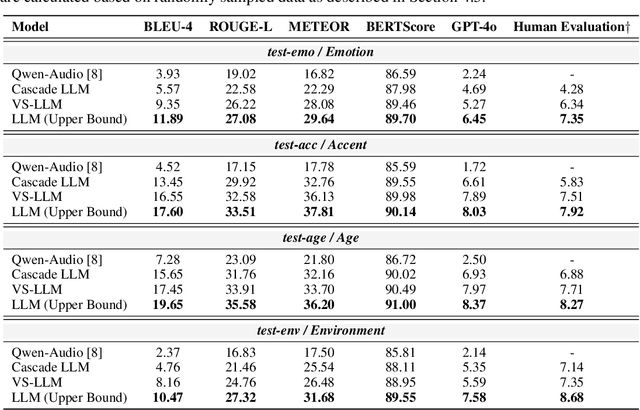

Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
Multi-Scale Accent Modeling with Disentangling for Multi-Speaker Multi-Accent TTS Synthesis
Jun 16, 2024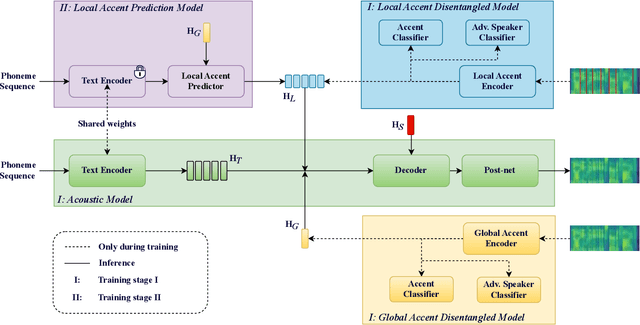
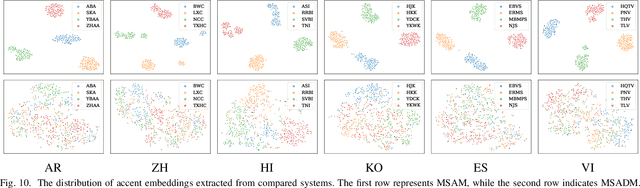
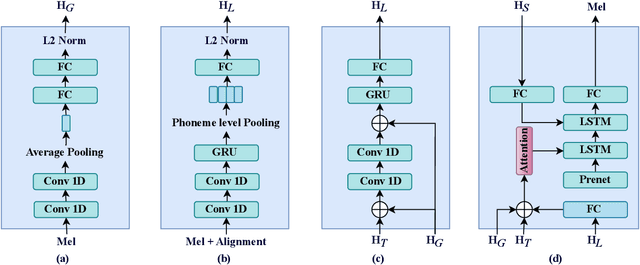
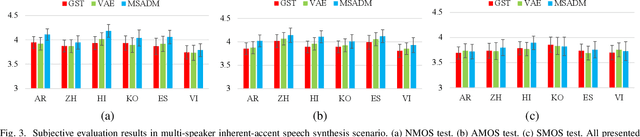
Synthesizing speech across different accents while preserving the speaker identity is essential for various real-world customer applications. However, the individual and accurate modeling of accents and speakers in a text-to-speech (TTS) system is challenging due to the complexity of accent variations and the intrinsic entanglement between the accent and speaker identity. In this paper, we present a novel approach for multi-speaker multi-accent TTS synthesis, which aims to synthesize voices of multiple speakers, each with various accents. Our proposed approach employs a multi-scale accent modeling strategy to address accent variations at different levels. Specifically, we introduce both global (utterance level) and local (phoneme level) accent modeling, supervised by individual accent classifiers to capture the overall variation within accented utterances and fine-grained variations between phonemes, respectively. To control accents and speakers separately, speaker-independent accent modeling is necessary, which is achieved by adversarial training with speaker classifiers to disentangle speaker identity within the multi-scale accent modeling. Consequently, we obtain speaker-independent and accent-discriminative multi-scale embeddings as comprehensive accent features. Additionally, we propose a local accent prediction model that allows to generate accented speech directly from phoneme inputs. Extensive experiments are conducted on an accented English speech corpus. Both objective and subjective evaluations show the superiority of our proposed system compared to baselines systems. Detailed component analysis demonstrates the effectiveness of global and local accent modeling, and speaker disentanglement on multi-speaker multi-accent speech synthesis.
An Investigation of Time-Frequency Representation Discriminators for High-Fidelity Vocoder
Apr 26, 2024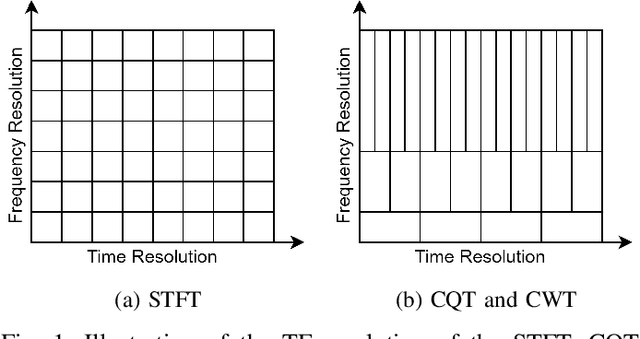
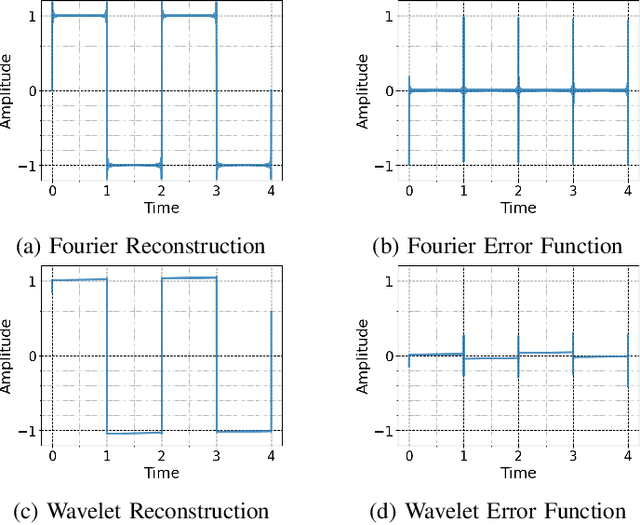
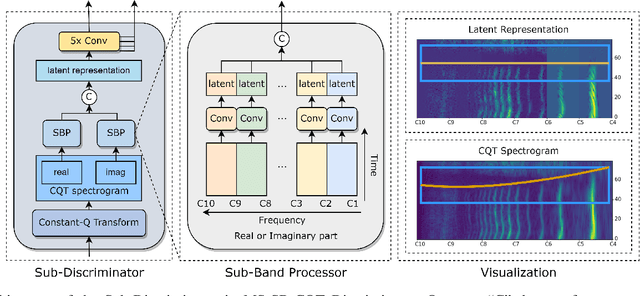
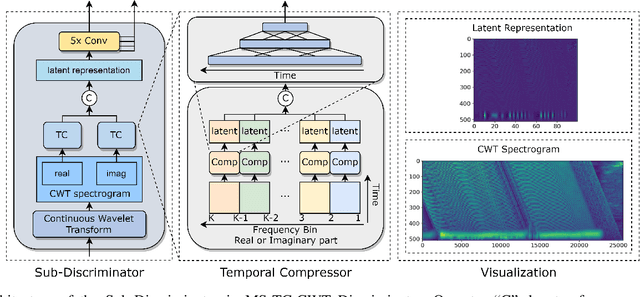
Generative Adversarial Network (GAN) based vocoders are superior in both inference speed and synthesis quality when reconstructing an audible waveform from an acoustic representation. This study focuses on improving the discriminator for GAN-based vocoders. Most existing Time-Frequency Representation (TFR)-based discriminators are rooted in Short-Time Fourier Transform (STFT), which owns a constant Time-Frequency (TF) resolution, linearly scaled center frequencies, and a fixed decomposition basis, making it incompatible with signals like singing voices that require dynamic attention for different frequency bands and different time intervals. Motivated by that, we propose a Multi-Scale Sub-Band Constant-Q Transform CQT (MS-SB-CQT) discriminator and a Multi-Scale Temporal-Compressed Continuous Wavelet Transform CWT (MS-TC-CWT) discriminator. Both CQT and CWT have a dynamic TF resolution for different frequency bands. In contrast, CQT has a better modeling ability in pitch information, and CWT has a better modeling ability in short-time transients. Experiments conducted on both speech and singing voices confirm the effectiveness of our proposed discriminators. Moreover, the STFT, CQT, and CWT-based discriminators can be used jointly for better performance. The proposed discriminators can boost the synthesis quality of various state-of-the-art GAN-based vocoders, including HiFi-GAN, BigVGAN, and APNet.
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Mar 05, 2024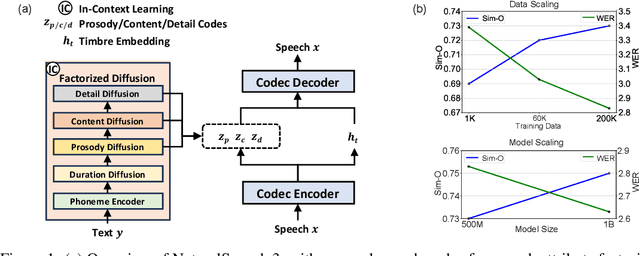
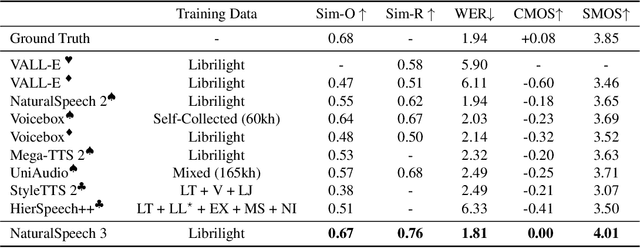
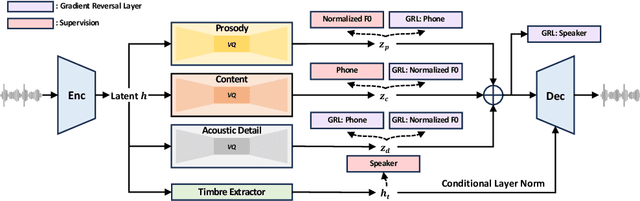
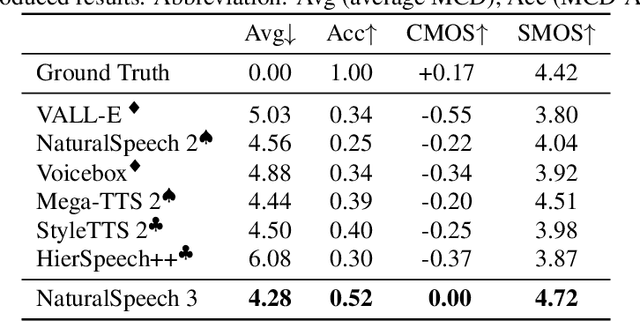
While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model the intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
SingVisio: Visual Analytics of Diffusion Model for Singing Voice Conversion
Feb 20, 2024In this study, we present SingVisio, an interactive visual analysis system that aims to explain the diffusion model used in singing voice conversion. SingVisio provides a visual display of the generation process in diffusion models, showcasing the step-by-step denoising of the noisy spectrum and its transformation into a clean spectrum that captures the desired singer's timbre. The system also facilitates side-by-side comparisons of different conditions, such as source content, melody, and target timbre, highlighting the impact of these conditions on the diffusion generation process and resulting conversions. Through comprehensive evaluations, SingVisio demonstrates its effectiveness in terms of system design, functionality, explainability, and user-friendliness. It offers users of various backgrounds valuable learning experiences and insights into the diffusion model for singing voice conversion.
CoAVT: A Cognition-Inspired Unified Audio-Visual-Text Pre-Training Model for Multimodal Processing
Jan 22, 2024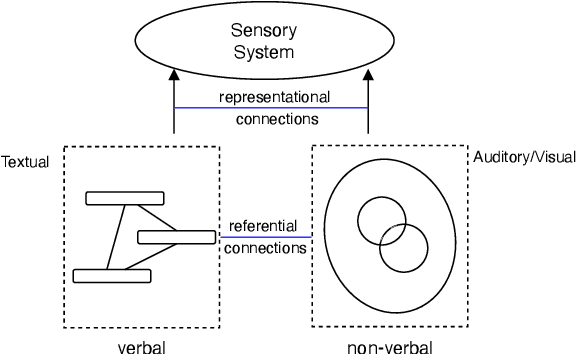
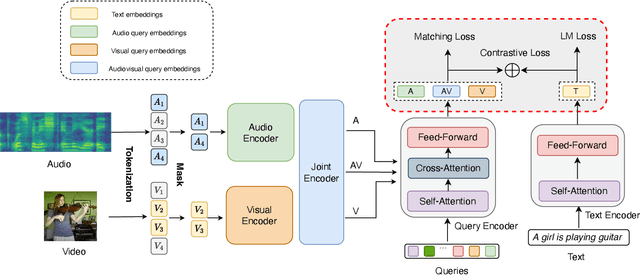

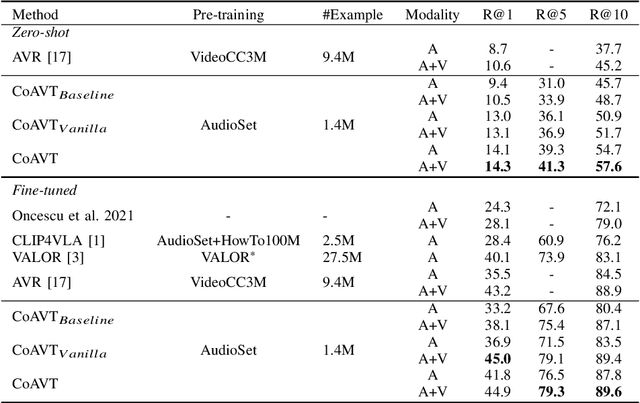
There has been a long-standing quest for a unified audio-visual-text model to enable various multimodal understanding tasks, which mimics the listening, seeing and reading process of human beings. Humans tends to represent knowledge using two separate systems: one for representing verbal (textual) information and one for representing non-verbal (visual and auditory) information. These two systems can operate independently but can also interact with each other. Motivated by this understanding of human cognition, in this paper, we introduce CoAVT -- a novel cognition-inspired Correlated Audio-Visual-Text pre-training model to connect the three modalities. It contains a joint audio-visual encoder that learns to encode audio-visual synchronization information together with the audio and visual content for non-verbal information, and a text encoder to handle textual input for verbal information. To bridge the gap between modalities, CoAVT employs a query encoder, which contains a set of learnable query embeddings, and extracts the most informative audiovisual features of the corresponding text. Additionally, to leverage the correspondences between audio and vision with language respectively, we also establish the audio-text and visual-text bi-modal alignments upon the foundational audiovisual-text tri-modal alignment to enhance the multimodal representation learning. Finally, we jointly optimize CoAVT model with three multimodal objectives: contrastive loss, matching loss and language modeling loss. Extensive experiments show that CoAVT can learn strong multimodal correlations and be generalized to various downstream tasks. CoAVT establishes new state-of-the-art performance on text-video retrieval task on AudioCaps for both zero-shot and fine-tuning settings, audio-visual event classification and audio-visual retrieval tasks on AudioSet and VGGSound.