 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024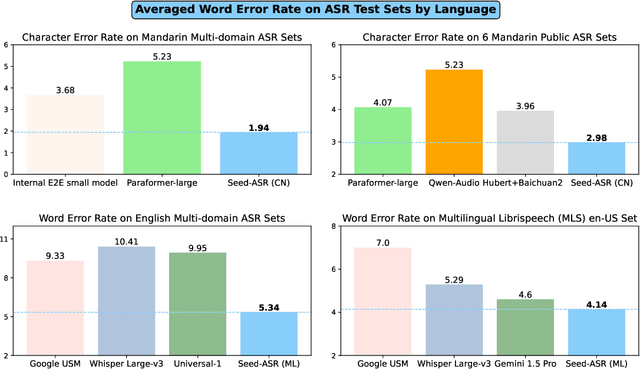

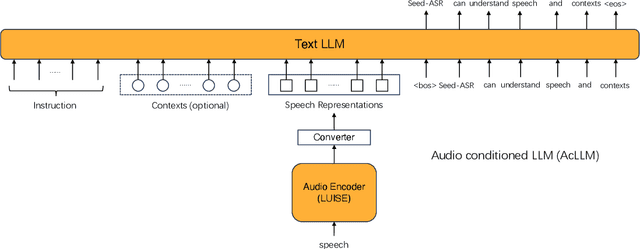

Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
A Comprehensive Solution to Connect Speech Encoder and Large Language Model for ASR
Jun 25, 2024
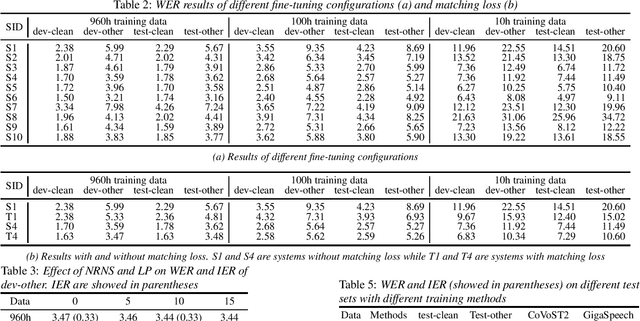
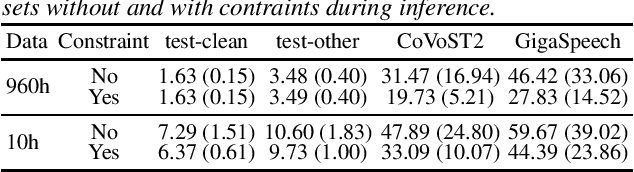
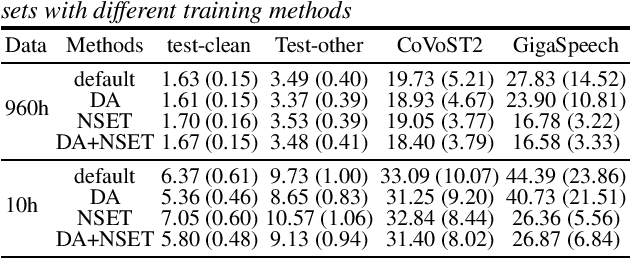
Recent works have shown promising results in connecting speech encoders to large language models (LLMs) for speech recognition. However, several limitations persist, including limited fine-tuning options, a lack of mechanisms to enforce speech-text alignment, and high insertion errors especially in domain mismatch conditions. This paper presents a comprehensive solution to address these issues. We begin by investigating more thoughtful fine-tuning schemes. Next, we propose a matching loss to enhance alignment between modalities. Finally, we explore training and inference methods to mitigate high insertion errors. Experimental results on the Librispeech corpus demonstrate that partially fine-tuning the encoder and LLM using parameter-efficient methods, such as LoRA, is the most cost-effective approach. Additionally, the matching loss improves modality alignment, enhancing performance. The proposed training and inference methods significantly reduce insertion errors.
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Jun 22, 2024Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Jun 19, 2024
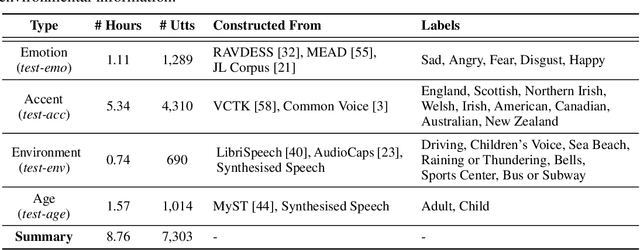
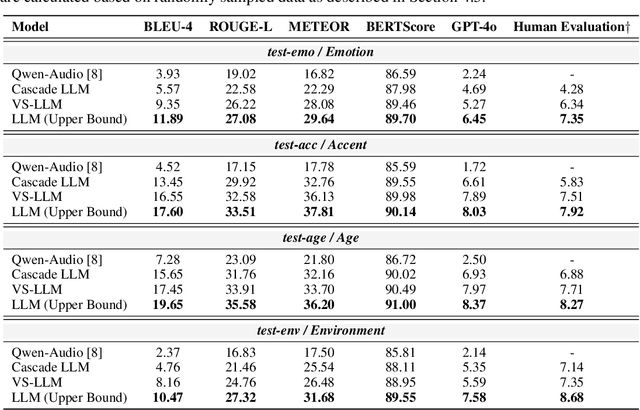

Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
Dual-Pipeline with Low-Rank Adaptation for New Language Integration in Multilingual ASR
Jun 12, 2024This paper addresses challenges in integrating new languages into a pre-trained multilingual automatic speech recognition (mASR) system, particularly in scenarios where training data for existing languages is limited or unavailable. The proposed method employs a dual-pipeline with low-rank adaptation (LoRA). It maintains two data flow pipelines-one for existing languages and another for new languages. The primary pipeline follows the standard flow through the pre-trained parameters of mASR, while the secondary pipeline additionally utilizes language-specific parameters represented by LoRA and a separate output decoder module. Importantly, the proposed approach minimizes the performance degradation of existing languages and enables a language-agnostic operation mode, facilitated by a decoder selection strategy. We validate the effectiveness of the proposed method by extending the pre-trained Whisper model to 19 new languages from the FLEURS dataset
Can Large Language Models Understand Spatial Audio?
Jun 12, 2024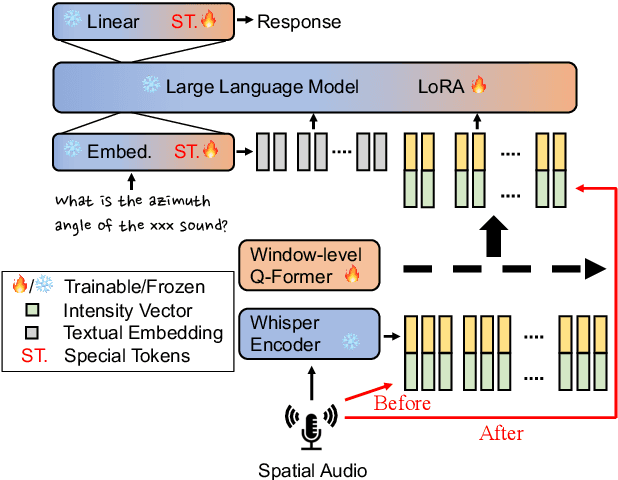
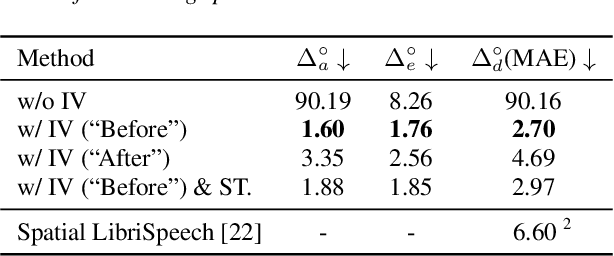
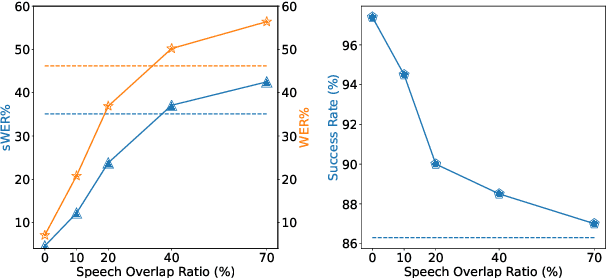

This paper explores enabling large language models (LLMs) to understand spatial information from multichannel audio, a skill currently lacking in auditory LLMs. By leveraging LLMs' advanced cognitive and inferential abilities, the aim is to enhance understanding of 3D environments via audio. We study 3 spatial audio tasks: sound source localization (SSL), far-field speech recognition (FSR), and localisation-informed speech extraction (LSE), achieving notable progress in each task. For SSL, our approach achieves an MAE of $2.70^{\circ}$ on the Spatial LibriSpeech dataset, substantially surpassing the prior benchmark of about $6.60^{\circ}$. Moreover, our model can employ spatial cues to improve FSR accuracy and execute LSE by selectively attending to sounds originating from a specified direction via text prompts, even amidst overlapping speech. These findings highlight the potential of adapting LLMs to grasp physical audio concepts, paving the way for LLM-based agents in 3D environments.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024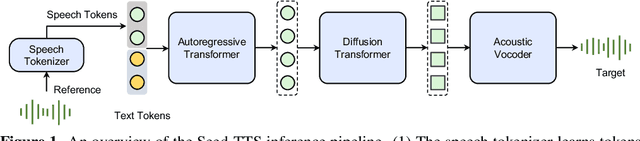
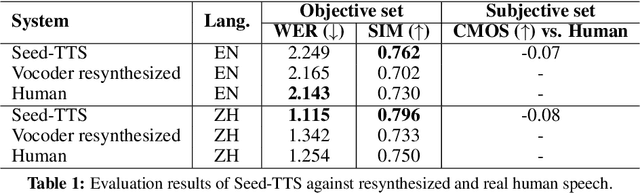


We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
Promoting AI Equity in Science: Generalized Domain Prompt Learning for Accessible VLM Research
May 14, 2024Large-scale Vision-Language Models (VLMs) have demonstrated exceptional performance in natural vision tasks, motivating researchers across domains to explore domain-specific VLMs. However, the construction of powerful domain-specific VLMs demands vast amounts of annotated data, substantial electrical energy, and computing resources, primarily accessible to industry, yet hindering VLM research in academia. To address this challenge and foster sustainable and equitable VLM research, we present the Generalized Domain Prompt Learning (GDPL) framework. GDPL facilitates the transfer of VLMs' robust recognition capabilities from natural vision to specialized domains, without the need for extensive data or resources. By leveraging small-scale domain-specific foundation models and minimal prompt samples, GDPL empowers the language branch with domain knowledge through quaternion networks, uncovering cross-modal relationships between domain-specific vision features and natural vision-based contextual embeddings. Simultaneously, GDPL guides the vision branch into specific domains through hierarchical propagation of generated vision prompt features, grounded in well-matched vision-language relations. Furthermore, to fully harness the domain adaptation potential of VLMs, we introduce a novel low-rank adaptation approach. Extensive experiments across diverse domains like remote sensing, medical imaging, geology, Synthetic Aperture Radar, and fluid dynamics, validate the efficacy of GDPL, demonstrating its ability to achieve state-of-the-art domain recognition performance in a prompt learning paradigm. Our framework paves the way for sustainable and inclusive VLM research, transcending the barriers between academia and industry.
Self-supervised Gait-based Emotion Representation Learning from Selective Strongly Augmented Skeleton Sequences
May 08, 2024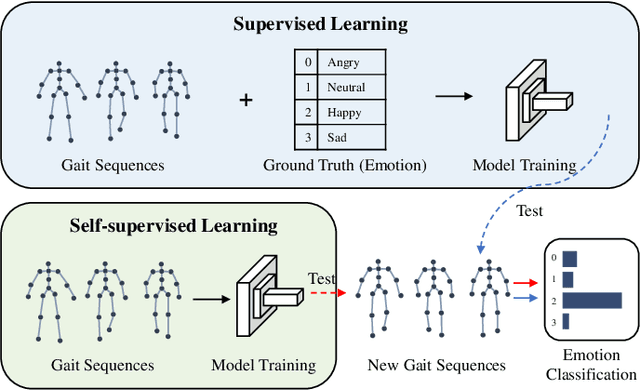
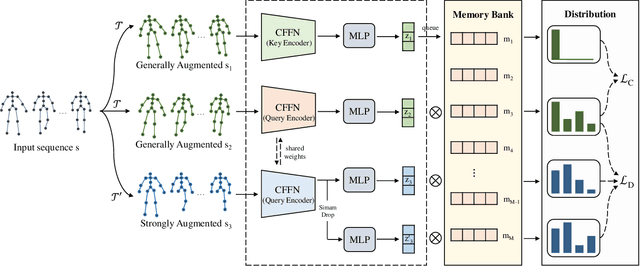
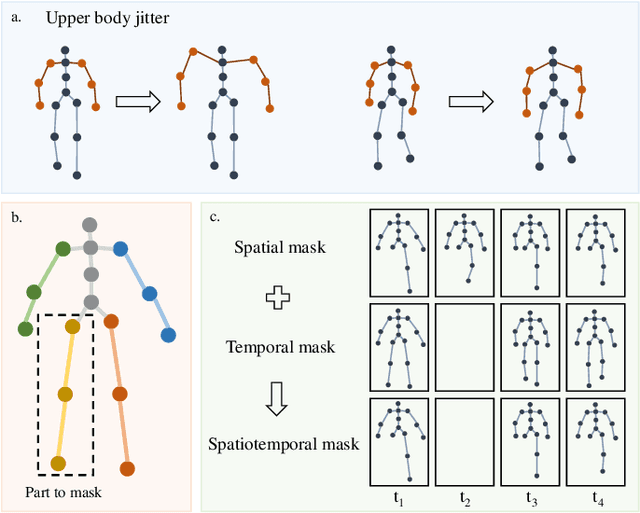
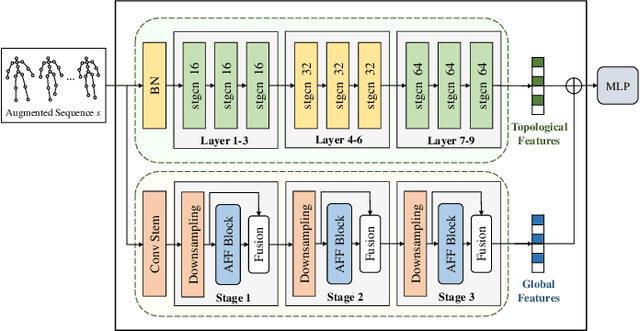
Emotion recognition is an important part of affective computing. Extracting emotional cues from human gaits yields benefits such as natural interaction, a nonintrusive nature, and remote detection. Recently, the introduction of self-supervised learning techniques offers a practical solution to the issues arising from the scarcity of labeled data in the field of gait-based emotion recognition. However, due to the limited diversity of gaits and the incompleteness of feature representations for skeletons, the existing contrastive learning methods are usually inefficient for the acquisition of gait emotions. In this paper, we propose a contrastive learning framework utilizing selective strong augmentation (SSA) for self-supervised gait-based emotion representation, which aims to derive effective representations from limited labeled gait data. First, we propose an SSA method for the gait emotion recognition task, which includes upper body jitter and random spatiotemporal mask. The goal of SSA is to generate more diverse and targeted positive samples and prompt the model to learn more distinctive and robust feature representations. Then, we design a complementary feature fusion network (CFFN) that facilitates the integration of cross-domain information to acquire topological structural and global adaptive features. Finally, we implement the distributional divergence minimization loss to supervise the representation learning of the generally and strongly augmented queries. Our approach is validated on the Emotion-Gait (E-Gait) and Emilya datasets and outperforms the state-of-the-art methods under different evaluation protocols.
SA-SOT: Speaker-Aware Serialized Output Training for Multi-Talker ASR
Mar 04, 2024
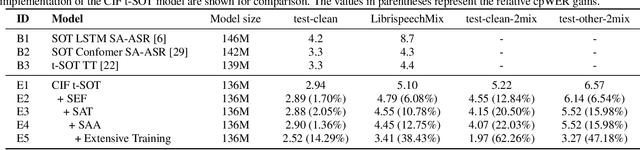
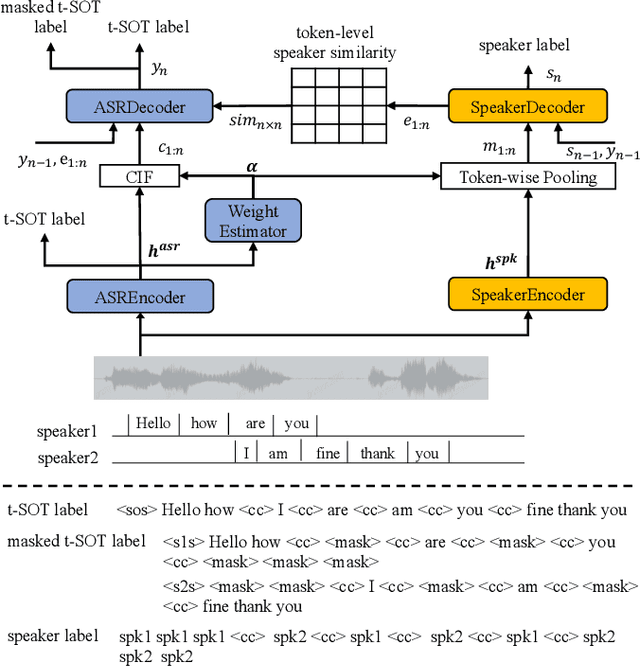
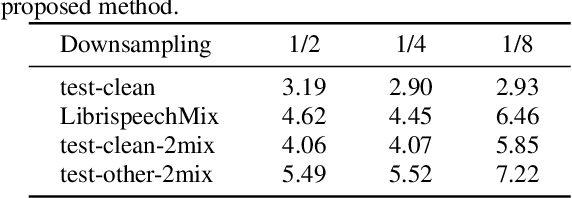
Multi-talker automatic speech recognition plays a crucial role in scenarios involving multi-party interactions, such as meetings and conversations. Due to its inherent complexity, this task has been receiving increasing attention. Notably, the serialized output training (SOT) stands out among various approaches because of its simplistic architecture and exceptional performance. However, the frequent speaker changes in token-level SOT (t-SOT) present challenges for the autoregressive decoder in effectively utilizing context to predict output sequences. To address this issue, we introduce a masked t-SOT label, which serves as the cornerstone of an auxiliary training loss. Additionally, we utilize a speaker similarity matrix to refine the self-attention mechanism of the decoder. This strategic adjustment enhances contextual relationships within the same speaker's tokens while minimizing interactions between different speakers' tokens. We denote our method as speaker-aware SOT (SA-SOT). Experiments on the Librispeech datasets demonstrate that our SA-SOT obtains a relative cpWER reduction ranging from 12.75% to 22.03% on the multi-talker test sets. Furthermore, with more extensive training, our method achieves an impressive cpWER of 3.41%, establishing a new state-of-the-art result on the LibrispeechMix dataset.