 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgevideo-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Jun 22, 2024Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.
Can Large Language Models Understand Spatial Audio?
Jun 12, 2024This paper explores enabling large language models (LLMs) to understand spatial information from multichannel audio, a skill currently lacking in auditory LLMs. By leveraging LLMs' advanced cognitive and inferential abilities, the aim is to enhance understanding of 3D environments via audio. We study 3 spatial audio tasks: sound source localization (SSL), far-field speech recognition (FSR), and localisation-informed speech extraction (LSE), achieving notable progress in each task. For SSL, our approach achieves an MAE of $2.70^{\circ}$ on the Spatial LibriSpeech dataset, substantially surpassing the prior benchmark of about $6.60^{\circ}$. Moreover, our model can employ spatial cues to improve FSR accuracy and execute LSE by selectively attending to sounds originating from a specified direction via text prompts, even amidst overlapping speech. These findings highlight the potential of adapting LLMs to grasp physical audio concepts, paving the way for LLM-based agents in 3D environments.
An Improved Empirical Fisher Approximation for Natural Gradient Descent
Jun 10, 2024Approximate Natural Gradient Descent (NGD) methods are an important family of optimisers for deep learning models, which use approximate Fisher information matrices to pre-condition gradients during training. The empirical Fisher (EF) method approximates the Fisher information matrix empirically by reusing the per-sample gradients collected during back-propagation. Despite its ease of implementation, the EF approximation has its theoretical and practical limitations. This paper first investigates the inversely-scaled projection issue of EF, which is shown to be a major cause of the poor empirical approximation quality. An improved empirical Fisher (iEF) method, motivated as a generalised NGD method from a loss reduction perspective, is proposed to address this issue, meanwhile retaining the practical convenience of EF. The exact iEF and EF methods are experimentally evaluated using practical deep learning setups, including widely-used setups for parameter-efficient fine-tuning of pre-trained models (T5-base with LoRA and Prompt-Tuning on GLUE tasks, and ViT with LoRA for CIFAR100). Optimisation experiments show that applying exact iEF as an optimiser provides strong convergence and generalisation. It achieves the best test performance and the lowest training loss for majority of the tasks, even when compared with well-tuned AdamW/Adafactor baselines. Additionally, under a novel empirical evaluation framework, the proposed iEF method shows consistently better approximation quality to the exact Natural Gradient updates than both EF and the more expensive sampled Fisher (SF). Further investigation also shows that the superior approximation quality of iEF is robust to damping across tasks and training stages. Improving existing approximate NGD optimisers with iEF is expected to lead to better convergence ability and stronger robustness to choice of damping.
M$^3$AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
Mar 21, 2024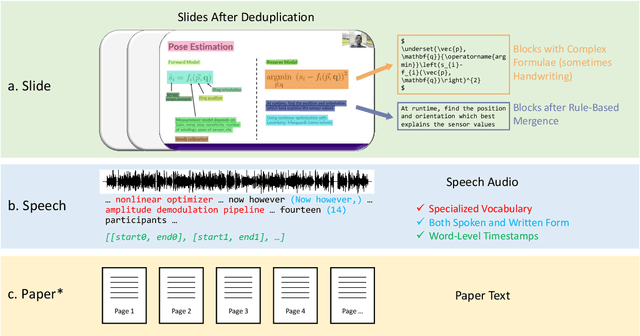
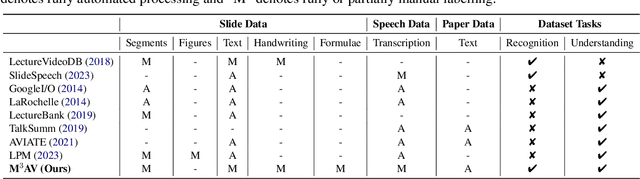
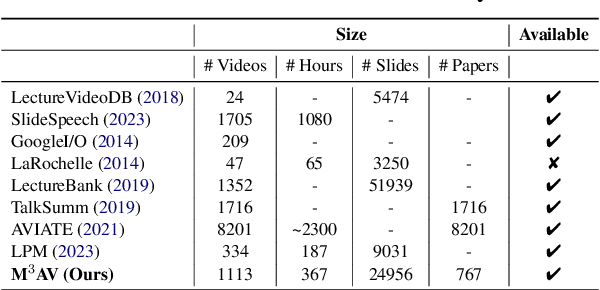
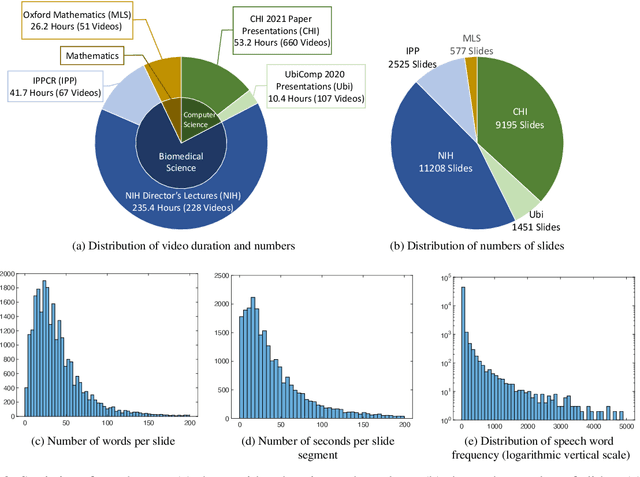
Publishing open-source academic video recordings is an emergent and prevalent approach to sharing knowledge online. Such videos carry rich multimodal information including speech, the facial and body movements of the speakers, as well as the texts and pictures in the slides and possibly even the papers. Although multiple academic video datasets have been constructed and released, few of them support both multimodal content recognition and understanding tasks, which is partially due to the lack of high-quality human annotations. In this paper, we propose a novel multimodal, multigenre, and multipurpose audio-visual academic lecture dataset (M$^3$AV), which has almost 367 hours of videos from five sources covering computer science, mathematics, and medical and biology topics. With high-quality human annotations of the spoken and written words, in particular high-valued name entities, the dataset can be used for multiple audio-visual recognition and understanding tasks. Evaluations performed on contextual speech recognition, speech synthesis, and slide and script generation tasks demonstrate that the diversity of M$^3$AV makes it a challenging dataset.
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Oct 20, 2023Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music. In this paper, we propose SALMONN, a speech audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model. SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning \textit{etc.} SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, and speech audio co-reasoning \textit{etc}. The presence of the cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities of SALMONN. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities. An interactive demo of SALMONN is available at \texttt{\url{https://github.com/bytedance/SALMONN}}, and the training code and model checkpoints will be released upon acceptance.
Fine-grained Audio-Visual Joint Representations for Multimodal Large Language Models
Oct 10, 2023Audio-visual large language models (LLM) have drawn significant attention, yet the fine-grained combination of both input streams is rather under-explored, which is challenging but necessary for LLMs to understand general video inputs. To this end, a fine-grained audio-visual joint representation (FAVOR) learning framework for multimodal LLMs is proposed in this paper, which extends a text-based LLM to simultaneously perceive speech and audio events in the audio input stream and images or videos in the visual input stream, at the frame level. To fuse the audio and visual feature streams into joint representations and to align the joint space with the LLM input embedding space, we propose a causal Q-Former structure with a causal attention module to enhance the capture of causal relations of the audio-visual frames across time. An audio-visual evaluation benchmark (AVEB) is also proposed which comprises six representative single-modal tasks with five cross-modal tasks reflecting audio-visual co-reasoning abilities. While achieving competitive single-modal performance on audio, speech and image tasks in AVEB, FAVOR achieved over 20% accuracy improvements on the video question-answering task when fine-grained information or temporal causal reasoning is required. FAVOR, in addition, demonstrated remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other multimodal LLMs. An interactive demo of FAVOR is available at https://github.com/BriansIDP/AudioVisualLLM.git, and the training code and model checkpoints will be released soon.
Connecting Speech Encoder and Large Language Model for ASR
Sep 26, 2023The impressive capability and versatility of large language models (LLMs) have aroused increasing attention in automatic speech recognition (ASR), with several pioneering studies attempting to build integrated ASR models by connecting a speech encoder with an LLM. This paper presents a comparative study of three commonly used structures as connectors, including fully connected layers, multi-head cross-attention, and Q-Former. Speech encoders from the Whisper model series as well as LLMs from the Vicuna model series with different model sizes were studied. Experiments were performed on the commonly used LibriSpeech, Common Voice, and GigaSpeech datasets, where the LLMs with Q-Formers demonstrated consistent and considerable word error rate (WER) reductions over LLMs with other connector structures. Q-Former-based LLMs can generalise well to out-of-domain datasets, where 12% relative WER reductions over the Whisper baseline ASR model were achieved on the Eval2000 test set without using any in-domain training data from Switchboard. Moreover, a novel segment-level Q-Former is proposed to enable LLMs to recognise speech segments with a duration exceeding the limitation of the encoders, which results in 17% relative WER reductions over other connector structures on 90-second-long speech data.