Hadoop – Cluster, Properties and its Types
Last Updated :
30 Jul, 2020
Before we start learning about the Hadoop cluster first thing we need to know is what actually cluster means. Cluster is a collection of something, a simple computer cluster is a group of various computers that are connected with each other through LAN(Local Area Network), the nodes in a cluster share the data, work on the same task and this nodes are good enough to work as a single unit means all of them to work together.
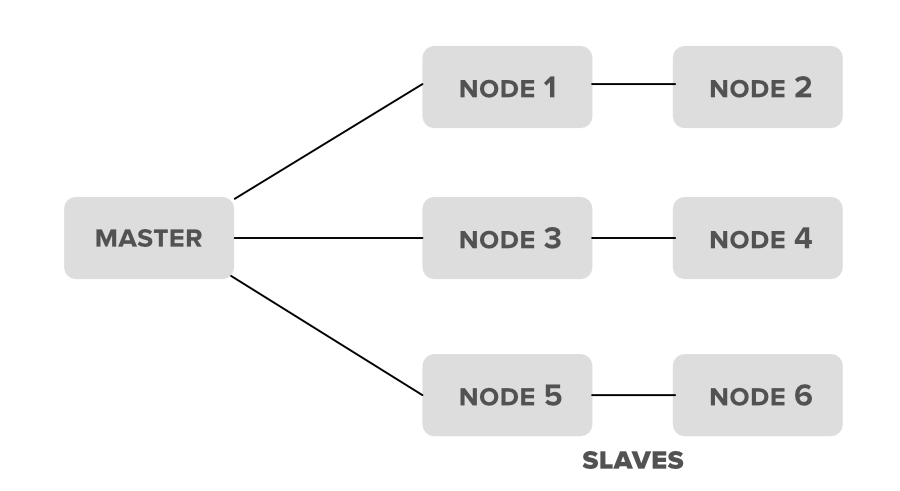
Similarly, a Hadoop cluster is also a collection of various commodity hardware(devices that are inexpensive and amply available). This Hardware components work together as a single unit. In the Hadoop cluster, there are lots of nodes (can be computer and servers) contains Master and Slaves, the Name node and Resource Manager works as Master and data node, and Node Manager works as a Slave. The purpose of Master nodes is to guide the slave nodes in a single Hadoop cluster. We design Hadoop clusters for storing, analyzing, understanding, and for finding the facts that are hidden behind the data or datasets which contain some crucial information. The Hadoop cluster stores different types of data and processes them.
- Structured-Data: The data which is well structured like Mysql.
- Semi-Structured Data: The data which has the structure but not the data type like XML, Json (Javascript object notation).
- Unstructured Data: The data that doesn’t have any structure like audio, video.
Hadoop Cluster Schema:
Hadoop Clusters Properties
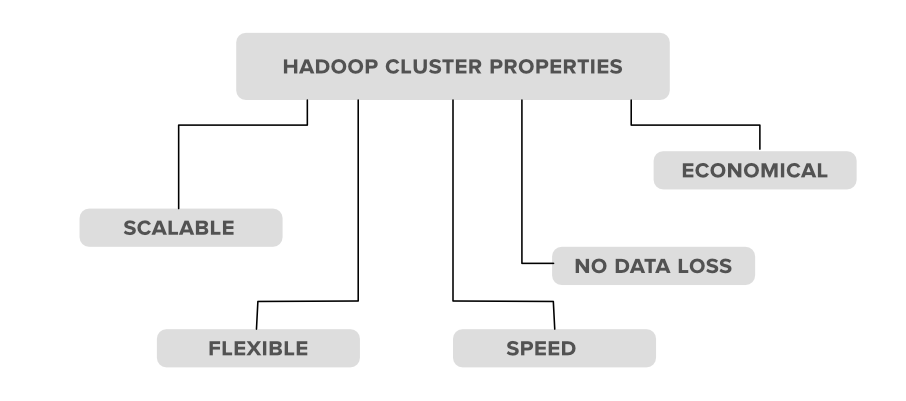
1. Scalability: Hadoop clusters are very much capable of scaling-up and scaling-down the number of nodes i.e. servers or commodity hardware. Let’s see with an example of what actually this scalable property means. Suppose an organization wants to analyze or maintain around 5PB of data for the upcoming 2 months so he used 10 nodes(servers) in his Hadoop cluster to maintain all of this data. But now what happens is, in between this month the organization has received extra data of 2PB, in that case, the organization has to set up or upgrade the number of servers in his Hadoop cluster system from 10 to 12(let’s consider) in order to maintain it. The process of scaling up or scaling down the number of servers in the Hadoop cluster is called scalability.
2. Flexibility: This is one of the important properties that a Hadoop cluster possesses. According to this property, the Hadoop cluster is very much Flexible means they can handle any type of data irrespective of its type and structure. With the help of this property, Hadoop can process any type of data from online web platforms.
3. Speed: Hadoop clusters are very much efficient to work with a very fast speed because the data is distributed among the cluster and also because of its data mapping capability’s i.e. the MapReduce architecture which works on the Master-Slave phenomena.
4. No Data-loss: There is no chance of loss of data from any node in a Hadoop cluster because Hadoop clusters have the ability to replicate the data in some other node. So in case of failure of any node no data is lost as it keeps track of backup for that data.
5. Economical: The Hadoop clusters are very much cost-efficient as they possess the distributed storage technique in their clusters i.e. the data is distributed in a cluster among all the nodes. So in the case to increase the storage we only need to add one more another hardware storage which is not that much costliest.
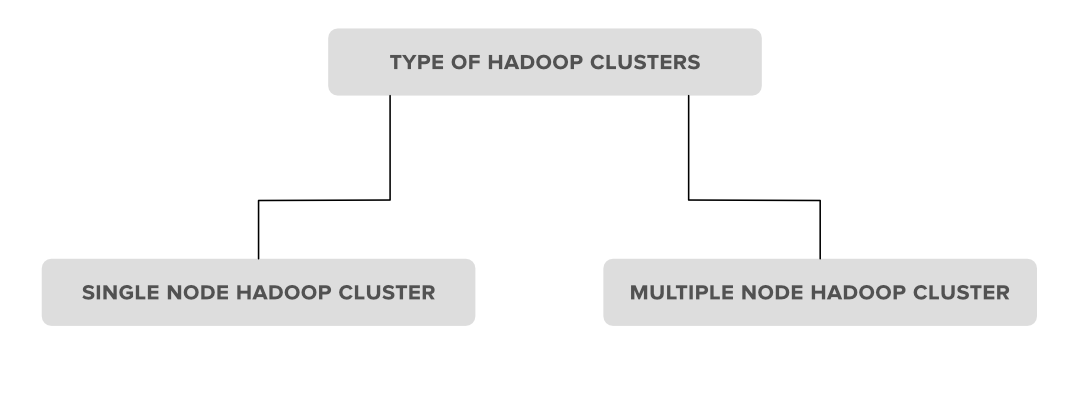
Types of Hadoop clusters
1. Single Node Hadoop Cluster
2. Multiple Node Hadoop Cluster
1. Single Node Hadoop Cluster: In Single Node Hadoop Cluster as the name suggests the cluster is of an only single node which means all our Hadoop Daemons i.e. Name Node, Data Node, Secondary Name Node, Resource Manager, Node Manager will run on the same system or on the same machine. It also means that all of our processes will be handled by only single JVM(Java Virtual Machine) Process Instance.
2. Multiple Node Hadoop Cluster: In multiple node Hadoop clusters as the name suggests it contains multiple nodes. In this kind of cluster set up all of our Hadoop Daemons, will store in different-different nodes in the same cluster setup. In general, in multiple node Hadoop cluster setup we try to utilize our higher processing nodes for Master i.e. Name node and Resource Manager and we utilize the cheaper system for the slave Daemon’s i.e.Node Manager and Data Node.
Please Login to comment...