0% found this document useful (0 votes)
3K viewsEm Algorithm
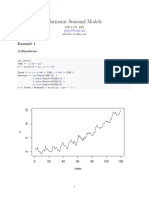
The document describes using the Expectation-Maximization (EM) algorithm to fit a mixture of two normal distributions to simulated data where some data points were drawn from N(1,1) and others from N(7,1). The EM algorithm iteratively estimates the latent class assignments (E-step) and distribution parameters (M-step) until convergence. It demonstrates the EM algorithm converging to the correct parameters over iterations on two examples of simulated data.
Uploaded by
api-285777244Copyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
3K viewsEm Algorithm
The document describes using the Expectation-Maximization (EM) algorithm to fit a mixture of two normal distributions to simulated data where some data points were drawn from N(1,1) and others from N(7,1). The EM algorithm iteratively estimates the latent class assignments (E-step) and distribution parameters (M-step) until convergence. It demonstrates the EM algorithm converging to the correct parameters over iterations on two examples of simulated data.
Uploaded by
api-285777244Copyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
/ 4