DNA Replication: DNA Replication Is A Biological Process That Occurs in All
DNA Replication: DNA Replication Is A Biological Process That Occurs in All
Download as doc, pdf, or txt
You might also like
- G5 - DLL - Classification of MatterDocument3 pagesG5 - DLL - Classification of MatterAdor Isip75% (4)
- DNA Replication: From Wikipedia, The Free EncyclopediaDocument10 pagesDNA Replication: From Wikipedia, The Free EncyclopediaRahul GuptaNo ratings yet
- Biochem Group ProjDocument21 pagesBiochem Group ProjYves Christian PineNo ratings yet
- DNA ReplicationDocument5 pagesDNA Replicationreccelle_pre295747No ratings yet
- DNA ReplicationDocument15 pagesDNA ReplicationAví Síngh KhökhárNo ratings yet
- DNA Replication, The Basis ForDocument23 pagesDNA Replication, The Basis ForDiana M. LlonaNo ratings yet
- 7th Cytogenetics Lecture 20121 1Document37 pages7th Cytogenetics Lecture 20121 1RC SILVESTRENo ratings yet
- DNA ReplicationDocument7 pagesDNA ReplicationMuhammad QayumNo ratings yet
- Replication of DNADocument9 pagesReplication of DNAvhyzh7ff2yNo ratings yet
- DNA ReplicationDocument18 pagesDNA ReplicationBalamurali PandiyanNo ratings yet
- HLF Dna ReplicationDocument8 pagesHLF Dna ReplicationPriyanka ChughNo ratings yet
- DNA Replication IDocument8 pagesDNA Replication IHarish GNo ratings yet
- Chapter Twelve: DNA Replication and Recombination: Comprehension QuestionsDocument13 pagesChapter Twelve: DNA Replication and Recombination: Comprehension QuestionsJeevikaGoyalNo ratings yet
- Dna ReplicateDocument31 pagesDna ReplicatedevinahNo ratings yet
- DNA, Replication, Gene Expression and Genetics-1Document62 pagesDNA, Replication, Gene Expression and Genetics-1Manar AnwerNo ratings yet
- Process of Dna Replication, Transcription, TranslationDocument8 pagesProcess of Dna Replication, Transcription, TranslationBenedictus YohanesNo ratings yet
- DNA Replication: DNA Replication Is A Biological Process That Occurs in AllDocument12 pagesDNA Replication: DNA Replication Is A Biological Process That Occurs in AllAnonymous HChxHbANo ratings yet
- Biochem QuinDocument4 pagesBiochem QuinKingNo ratings yet
- DNA Structure, Transcription, TranslationDocument10 pagesDNA Structure, Transcription, TranslationSajanMaharjanNo ratings yet
- DNA Replication-Sem 2 20222023-UKMFolio-Part 3Document40 pagesDNA Replication-Sem 2 20222023-UKMFolio-Part 3Keesal SundraNo ratings yet
- Molecular Biology Study MaterialDocument58 pagesMolecular Biology Study MaterialchitraNo ratings yet
- Solutions Manual Chapter 12Document17 pagesSolutions Manual Chapter 12Lú Lạ LẫmNo ratings yet
- Molecular Biology Unit IV and VDocument60 pagesMolecular Biology Unit IV and VchitraNo ratings yet
- MBC 331 NOTE 1Document13 pagesMBC 331 NOTE 1NwankwoNo ratings yet
- DNA ReplicationDocument12 pagesDNA Replicationmeprabhatmishra99No ratings yet
- Lecture 2Document48 pagesLecture 2KrishNo ratings yet
- Dna ReplicationDocument21 pagesDna ReplicationGhost IraQNo ratings yet
- Dna Replication and Protein SynthesisDocument12 pagesDna Replication and Protein Synthesisromelreston04No ratings yet
- 2.7, 7.1, 7.2, 7.3 DNA Replication, Transcription and Translation Biology HLDocument91 pages2.7, 7.1, 7.2, 7.3 DNA Replication, Transcription and Translation Biology HLmunir sehwai.No ratings yet
- Cytogenetics Seatwork No. 4 DNA ReplicationDocument4 pagesCytogenetics Seatwork No. 4 DNA ReplicationKemverly RanaNo ratings yet
- Structure and Function of DNADocument29 pagesStructure and Function of DNAMatthew Justin Villanueva GozoNo ratings yet
- Process of Dna ReplicationDocument3 pagesProcess of Dna ReplicationLaiba AsimNo ratings yet
- DNA Replication Process in ProkaryotesDocument3 pagesDNA Replication Process in Prokaryoteswithlovemahe246No ratings yet
- Dna ReplicationDocument18 pagesDna ReplicationOguh AugustineNo ratings yet
- DNA ReplicationDocument21 pagesDNA ReplicationP Santosh KumarNo ratings yet
- Structure of DNA Science Presentation in Light Blue Green Lined Style 20240314 1Document26 pagesStructure of DNA Science Presentation in Light Blue Green Lined Style 20240314 1leighariazbongsNo ratings yet
- Packaging of DNA Into ChromosomeDocument13 pagesPackaging of DNA Into ChromosomeShashank AppuNo ratings yet
- BCH 305 (Chemistry & Metabolism of Nucleic Acids)Document30 pagesBCH 305 (Chemistry & Metabolism of Nucleic Acids)ihebunnaogochukwu24No ratings yet
- Replikasi DNA Dan Sintesis Protein (Gabungan)Document62 pagesReplikasi DNA Dan Sintesis Protein (Gabungan)adinda tyasprabandariNo ratings yet
- The Replication of DNA in Prokaryo1tesDocument7 pagesThe Replication of DNA in Prokaryo1teshgkutjutNo ratings yet
- Prokaryotic and Eukaryotic DNA ReplicationDocument11 pagesProkaryotic and Eukaryotic DNA ReplicationSarmistha NayakNo ratings yet
- DNA ReplicationDocument13 pagesDNA ReplicationLisha AnbanNo ratings yet
- Genes and Protein SynthesisDocument7 pagesGenes and Protein SynthesisbrayonosoroNo ratings yet
- Replication Transcription and TranslationDocument16 pagesReplication Transcription and TranslationBalangat Regine L.No ratings yet
- Individual Assignment 1 PPH 226Document3 pagesIndividual Assignment 1 PPH 226Benjamin Aluoch OnyangoNo ratings yet
- BCH 401 Note 1 - KWASUDocument35 pagesBCH 401 Note 1 - KWASUidriscognitoleadsNo ratings yet
- Nucleotides, Nucleic Acids and Gene StructureDocument4 pagesNucleotides, Nucleic Acids and Gene StructureRobert RourkeNo ratings yet
- José A. Cardé-Serrano, PHD Universidad Adventista de Las Antillas Biol 223 - Genética Agosto 2010Document56 pagesJosé A. Cardé-Serrano, PHD Universidad Adventista de Las Antillas Biol 223 - Genética Agosto 2010dopeswagNo ratings yet
- All DNADocument69 pagesAll DNAkeerthiNo ratings yet
- The Growing Point Paradox and Discontinuous DNA SynthesisDocument5 pagesThe Growing Point Paradox and Discontinuous DNA Synthesisintan yunandaNo ratings yet
- Chapter 4A: DNA Replication & Protein SynthesisDocument34 pagesChapter 4A: DNA Replication & Protein SynthesisPikuNo ratings yet
- 14.4 DNA Replication in ProkaryotesDocument3 pages14.4 DNA Replication in ProkaryotesAyushi MauryaNo ratings yet
- GENETICSDocument37 pagesGENETICSJohn KennedyNo ratings yet
- 2 - Nucleic Acid Replication, Transcription & Translation - ModuleDocument15 pages2 - Nucleic Acid Replication, Transcription & Translation - ModuleMichaella CabanaNo ratings yet
- 56404332dna ReplicationDocument4 pages56404332dna ReplicationKaranNo ratings yet
- DNA - The Molecular Basis of InheritanceDocument38 pagesDNA - The Molecular Basis of InheritanceEgi JhonoNo ratings yet
- Lab 2 Degenerate PCR - BackgroundDocument18 pagesLab 2 Degenerate PCR - BackgroundTitania ERSNo ratings yet
- Central Dogma of Molecular BiologyDocument34 pagesCentral Dogma of Molecular BiologyGretz AnticamaraNo ratings yet
- DNA ReplicationDocument5 pagesDNA ReplicationNikki SStarkNo ratings yet
- DNA Replication and RepairDocument7 pagesDNA Replication and RepairJhun Lerry TayanNo ratings yet
- Analysis and Approaches HL - Calculator Guide - TI-nspireDocument34 pagesAnalysis and Approaches HL - Calculator Guide - TI-nspireMostafa ElSanousiNo ratings yet
- Notes - M1 Unit 5Document7 pagesNotes - M1 Unit 5Aniket AgvaneNo ratings yet
- CIDB MyCESMM Library of Standard DescriptionsDocument173 pagesCIDB MyCESMM Library of Standard Descriptionskiet eelNo ratings yet
- SFR Motorcycle Chain ENDocument7 pagesSFR Motorcycle Chain ENjavierhonda69gmail.comNo ratings yet
- Strategic Service VisionDocument44 pagesStrategic Service VisionKannan RangaswamiNo ratings yet
- Hospital BriefDocument8 pagesHospital Briefvignesh rulzNo ratings yet
- Iot Unit 3 DecodeDocument5 pagesIot Unit 3 DecodeGanesh reddy NarmalaNo ratings yet
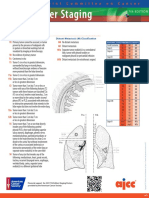
- Lung Cancer Staging Poster UpdatedDocument2 pagesLung Cancer Staging Poster UpdatedCarlos Eduardo Avila100% (1)
- Gaurav Pawar: Project SkillsDocument1 pageGaurav Pawar: Project SkillsGaurav PawarNo ratings yet
- Pethapur Jignesh R Luhariya PanchalDocument2 pagesPethapur Jignesh R Luhariya PanchalmanijigneshNo ratings yet
- Bruce E. Depalma: N-Machine: Extraction of Electrical Energy Directly From Space: The N-MachineDocument7 pagesBruce E. Depalma: N-Machine: Extraction of Electrical Energy Directly From Space: The N-MachinebanzailoicNo ratings yet
- Teaching Language SkillsDocument5 pagesTeaching Language SkillsRocioNo ratings yet
- Objective First3 Upper Intermediate Paper4 Listening PDFDocument5 pagesObjective First3 Upper Intermediate Paper4 Listening PDFAndrea Lopez CastilloNo ratings yet
- APACPH2013Document428 pagesAPACPH2013Shoki MakhanNo ratings yet
- Life in Medieval TownsDocument30 pagesLife in Medieval TownsAmirul Aizad Bin KamaruzamanNo ratings yet
- EPSON WF-C20590 Service Manual - Page1201-1242Document42 pagesEPSON WF-C20590 Service Manual - Page1201-1242Ion IonutNo ratings yet
- 2 Puc Neet 19 11biological ClassificationDocument8 pages2 Puc Neet 19 11biological ClassificationRajesh PrasadNo ratings yet
- CAT LRDI 11 Arrangement-1Document40 pagesCAT LRDI 11 Arrangement-1shivam sharmaNo ratings yet
- Material List: Produced On 23/11/2021 With Xpress Selection V9.6.1 - Database DIL 16.6.4Document13 pagesMaterial List: Produced On 23/11/2021 With Xpress Selection V9.6.1 - Database DIL 16.6.4Sicologo CimeNo ratings yet
- 3323 Part B DCHB TheniDocument232 pages3323 Part B DCHB TheniJack DeshNo ratings yet
- Module #6 Simple Past: Irregular Verbs, Weather, Seasons: Universidad Tecnologica de HondurasDocument8 pagesModule #6 Simple Past: Irregular Verbs, Weather, Seasons: Universidad Tecnologica de HondurasWilfredo RiveraNo ratings yet
- ESIADocument55 pagesESIA1mmahoneyNo ratings yet
- Smarter Phonic : Book 2: A Big Pig or Mig Props For Book 2 Story - Wig, MusicDocument1 pageSmarter Phonic : Book 2: A Big Pig or Mig Props For Book 2 Story - Wig, MusicKing GilgameshNo ratings yet
- Module 14 - Working With Files in C#Document49 pagesModule 14 - Working With Files in C#api-19796528No ratings yet
- Talent Acquisition ReportDocument2 pagesTalent Acquisition ReportRashi BansalNo ratings yet
- DLP-July 16Document2 pagesDLP-July 16Igorota Sheanne0% (1)
- 14 Bernardo Soustruhy deDocument40 pages14 Bernardo Soustruhy deTanase Constantin0% (1)
- Nalbindning: Fru Cristina Stolte (Anna Gustafsson) Research PaperDocument13 pagesNalbindning: Fru Cristina Stolte (Anna Gustafsson) Research PaperFlorencia100% (2)
- AVEVABocad Installation2 2 enDocument20 pagesAVEVABocad Installation2 2 encristhianNo ratings yet