0% found this document useful (0 votes)
239 viewsApache Kafka Description
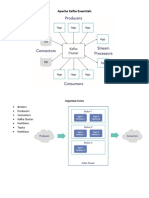
Apache Kafka is a distributed publish-subscribe messaging system that can be used for building real-time data pipelines and streaming applications. It is designed to be fast, scalable, and durable. Kafka maintains feeds of messages in categories called topics that can be published to by producers and consumed from by subscribers. It uses a distributed commit log that provides ordering and replication to ensure reliability.
Uploaded by
Roy AntoniusCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
239 viewsApache Kafka Description
Apache Kafka is a distributed publish-subscribe messaging system that can be used for building real-time data pipelines and streaming applications. It is designed to be fast, scalable, and durable. Kafka maintains feeds of messages in categories called topics that can be published to by producers and consumed from by subscribers. It uses a distributed commit log that provides ordering and replication to ensure reliability.
Uploaded by
Roy AntoniusCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 36