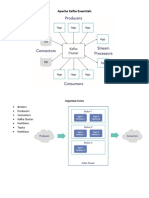
Getting To Know Kafka: Ola Is The First Course in The Series of Courses Covering All The Aspects of Kafka
Getting To Know Kafka: Ola Is The First Course in The Series of Courses Covering All The Aspects of Kafka
Download as docx, pdf, or txt
You might also like
- ReactJs HandsOnDocument5 pagesReactJs HandsOnMahesh VP60% (5)
- Linear Algebra Q & ADocument9 pagesLinear Algebra Q & AMahesh VP100% (1)
- Getting To Know JestDocument29 pagesGetting To Know JestMahesh VP100% (1)
- Reactjs - Interlace Your Interface Introduction To Reactjs: What Is Exciting Here?Document19 pagesReactjs - Interlace Your Interface Introduction To Reactjs: What Is Exciting Here?Mahesh VPNo ratings yet
- Kafka Low Level ArchitectureDocument52 pagesKafka Low Level Architecturemahesh kNo ratings yet
- Understanding Apache Kafka White PaperDocument7 pagesUnderstanding Apache Kafka White PaperВиталий ТуткевичNo ratings yet
- Apache KafkaDocument9 pagesApache KafkaYasir Mohsin KazmiNo ratings yet
- Handle Large Messages in Apache KafkaDocument59 pagesHandle Large Messages in Apache KafkaBùi Văn KiênNo ratings yet
- Machine Learning AxiomDocument3 pagesMachine Learning AxiomMahesh VP100% (2)
- Top Answers To Kafka Interview QuestionsDocument3 pagesTop Answers To Kafka Interview QuestionsEjaz AlamNo ratings yet
- Apache Kafka TutorialDocument6 pagesApache Kafka Tutorialvaram10No ratings yet
- Apache Kafka DescriptionDocument36 pagesApache Kafka DescriptionRoy AntoniusNo ratings yet
- Apache Kafka Key ConceptsDocument8 pagesApache Kafka Key Conceptssayhi2sudarshan100% (1)
- Apache Kafka 101Document25 pagesApache Kafka 101Satya Sworup NayakNo ratings yet
- Apache Kafka - IntroductionDocument2 pagesApache Kafka - Introductionmapa2509No ratings yet
- Kafka SparkstreamingDocument75 pagesKafka SparkstreamingDastagiri SahebNo ratings yet
- Apache Kafka Cookbook - Sample ChapterDocument14 pagesApache Kafka Cookbook - Sample ChapterPackt Publishing100% (1)
- Learning Apache Kafka - Second Edition - Sample ChapterDocument12 pagesLearning Apache Kafka - Second Edition - Sample ChapterPackt PublishingNo ratings yet
- Apache Kafka Interview QuestionsDocument5 pagesApache Kafka Interview QuestionsshubhamtechgeelNo ratings yet
- Integrating Apache Nifi and Apache KafkaDocument5 pagesIntegrating Apache Nifi and Apache KafkaMario SoaresNo ratings yet
- Interview QuestionDocument24 pagesInterview QuestionAnil YarlagaddaNo ratings yet
- KafkaDocument50 pagesKafkaEmanuele ParenteNo ratings yet
- Kafka Up and Running for Network DevOps: Set Your Network Data in MotionFrom EverandKafka Up and Running for Network DevOps: Set Your Network Data in MotionNo ratings yet
- Kafka Streams - Real-time Streams ProcessingFrom EverandKafka Streams - Real-time Streams ProcessingRating: 5 out of 5 stars5/5 (2)
- Kafka My Kafka Note v67Document55 pagesKafka My Kafka Note v67abhi gargNo ratings yet
- Apache Kafka - Basic OperationsDocument6 pagesApache Kafka - Basic Operationspradeep kothapallyNo ratings yet
- Kafka InternalsDocument30 pagesKafka InternalsDarshna GuptaNo ratings yet
- Kafka PDFDocument106 pagesKafka PDFsarim siddiquiNo ratings yet
- Kafka Cloudera DocumentationDocument175 pagesKafka Cloudera DocumentationVishakha Singh100% (1)
- Configuring Kafka For High ThroughputDocument11 pagesConfiguring Kafka For High Throughputnilesh86378No ratings yet
- AWS Practice QuestionsDocument17 pagesAWS Practice QuestionsSanjayNo ratings yet
- Apache Spark Streaming PresentationDocument28 pagesApache Spark Streaming PresentationSlavimirVesić100% (1)
- Stream Processing Using KafkaDocument46 pagesStream Processing Using Kafka1himaniaroraNo ratings yet
- Kafka and Spark StreamingDocument45 pagesKafka and Spark Streamingmanish_gupta22No ratings yet
- Top 10 Kafka ProblemsDocument3 pagesTop 10 Kafka Problemsgogula sivannarayanaNo ratings yet
- Kafka101training Public v2 140818033637 Phpapp01Document119 pagesKafka101training Public v2 140818033637 Phpapp01hotsync101No ratings yet
- Apache KafkaDocument6 pagesApache KafkaJason GomezNo ratings yet
- Apache Camel - Enterprise Integration PatternsDocument146 pagesApache Camel - Enterprise Integration PatternsalessandrosalvadoNo ratings yet
- Apache KafkaDocument37 pagesApache KafkaThomas VargheseNo ratings yet
- Spark Kafkaintegration PDFDocument71 pagesSpark Kafkaintegration PDFehenry100% (1)
- Apache KafkaDocument245 pagesApache KafkaKunwar_23No ratings yet
- Apache Kafka TutorialDocument3 pagesApache Kafka TutorialMario SoaresNo ratings yet
- Cloudera Developer TrainingDocument483 pagesCloudera Developer Trainingequest7916100% (1)
- Research On AWS GlueDocument5 pagesResearch On AWS GlueJack Kenneth Bondoc-CutiongcoNo ratings yet
- Kafka Producer Internals: Find Answers On The Fly, or Master Something New. Subscribe TodayDocument1 pageKafka Producer Internals: Find Answers On The Fly, or Master Something New. Subscribe TodayDallas GuyNo ratings yet
- A Visual Introduction To Apache Kafka PDFDocument84 pagesA Visual Introduction To Apache Kafka PDFtim2421No ratings yet
- Apache Kafka Tutorial PDFDocument13 pagesApache Kafka Tutorial PDFMahmoud NaserNo ratings yet
- Spark InterviewDocument17 pagesSpark InterviewDastagiri SahebNo ratings yet
- Key Features: General-Purpose Fast Cluster Computing PlatformDocument16 pagesKey Features: General-Purpose Fast Cluster Computing PlatformMahesh VPNo ratings yet
- Mahesh - Big Data EngineerDocument5 pagesMahesh - Big Data EngineerNoor Ayesha IqbalNo ratings yet
- Apache KafkaDocument33 pagesApache Kafkadharmareddyr100% (1)
- Apache KafkaDocument130 pagesApache KafkatejpremiumNo ratings yet
- Microservices PDFDocument6 pagesMicroservices PDFMahendar SNo ratings yet
- Aws Interview QuestionsDocument8 pagesAws Interview QuestionsDsm Darshan0% (1)
- Cloudurable Kafka Tutorial v1 PDFDocument79 pagesCloudurable Kafka Tutorial v1 PDFakash bNo ratings yet
- Hadoop Overview Training MaterialDocument44 pagesHadoop Overview Training MaterialsrinidkNo ratings yet
- AWS Database Migration Service Best PracticesDocument17 pagesAWS Database Migration Service Best PracticesWarwick81100% (1)
- AWS White PaperDocument88 pagesAWS White Paperiam_ritehereNo ratings yet
- Aslam, Mohammad Email: Phone: Big Data/Cloud DeveloperDocument6 pagesAslam, Mohammad Email: Phone: Big Data/Cloud DeveloperMadhav GarikapatiNo ratings yet
- AWS ClassBook Lesson1Document10 pagesAWS ClassBook Lesson1SAINo ratings yet
- Hadoop, Hbase, and HiveDocument25 pagesHadoop, Hbase, and HiveHarvinder SainiNo ratings yet
- Introduction To IonicDocument12 pagesIntroduction To IonicMahesh VPNo ratings yet
- ScalaNew MalayDocument4 pagesScalaNew MalayMahesh VPNo ratings yet
- Onsen Ui DumpDocument3 pagesOnsen Ui DumpMahesh VPNo ratings yet
- R Basic and Data Mining Methods BasicsDocument2 pagesR Basic and Data Mining Methods BasicsMahesh VPNo ratings yet
- Python 3 ProgrammingDocument6 pagesPython 3 ProgrammingMahesh VPNo ratings yet
- Spark Streaming - MalayDocument1 pageSpark Streaming - MalayMahesh VP100% (1)
- Native ScriptDocument23 pagesNative ScriptMahesh VPNo ratings yet
- Hybrid Apps IntroductionDocument9 pagesHybrid Apps IntroductionMahesh VPNo ratings yet
- Deep Learning - Tools and ApplicationsDocument1 pageDeep Learning - Tools and ApplicationsMahesh VPNo ratings yet
- Ngnix The BasicsDocument17 pagesNgnix The BasicsMahesh VPNo ratings yet
- Kibana Course OverviewDocument18 pagesKibana Course OverviewMahesh VPNo ratings yet
- Onsen UI - Course IntroductionDocument19 pagesOnsen UI - Course IntroductionMahesh VPNo ratings yet
- IaC DumpDocument3 pagesIaC DumpMahesh VP50% (2)
- Python 3 - Functions and OOPs - MalayDocument4 pagesPython 3 - Functions and OOPs - MalayMahesh VP0% (1)
- Azure ContinuumDocument4 pagesAzure ContinuumMahesh VPNo ratings yet
- API GatewaysDocument13 pagesAPI GatewaysMahesh VP100% (1)
- Gradle Hello or Gradle - Q HelloDocument3 pagesGradle Hello or Gradle - Q HelloECE ANo ratings yet
- Inndigo Interview QuestionsDocument1 pageInndigo Interview QuestionsToughmastermind100% (1)
- Data Visualization Using RDocument3 pagesData Visualization Using RMahesh VPNo ratings yet
- Gradle Q & A - V0 1Document4 pagesGradle Q & A - V0 1Mahesh VPNo ratings yet
- Key Features: General-Purpose Fast Cluster Computing PlatformDocument16 pagesKey Features: General-Purpose Fast Cluster Computing PlatformMahesh VPNo ratings yet
- Robot Operating SystemDocument11 pagesRobot Operating SystemPravin PrajapatiNo ratings yet
- IoT AssignmentDocument3 pagesIoT AssignmentminichelNo ratings yet
- Instant download Web Technology Theory and Practice 1st Edition Akshi Kumar (Author) pdf all chapterDocument63 pagesInstant download Web Technology Theory and Practice 1st Edition Akshi Kumar (Author) pdf all chaptercalonscirecp100% (3)
- Device Upgrade Procedure v6 0Document16 pagesDevice Upgrade Procedure v6 0زكيعباديNo ratings yet
- Data AnalyticsDocument67 pagesData AnalyticsOussèma SouissiNo ratings yet
- Maximum Number of Correct Answers To Be Considered For ResultsDocument2 pagesMaximum Number of Correct Answers To Be Considered For ResultsPradeepNo ratings yet
- Building Management SystemDocument13 pagesBuilding Management SystemSumedha GuptaNo ratings yet
- BLS Manual ENDocument28 pagesBLS Manual ENLuana Mari NodaNo ratings yet
- Stefan ShortDocument1 pageStefan ShortHOSAM HUSSEINNo ratings yet
- Synopsis - Secure Mail SystemDocument8 pagesSynopsis - Secure Mail SystemAamir RasheedNo ratings yet
- Motherboard Manual Ga-Q35m-S2 eDocument100 pagesMotherboard Manual Ga-Q35m-S2 eClemente GuerraNo ratings yet
- GPS Tracking System Using ARDUINODocument15 pagesGPS Tracking System Using ARDUINORenu PeriketiNo ratings yet
- System Adoption: Socio-Technical IntegrationDocument13 pagesSystem Adoption: Socio-Technical IntegrationThe IjbmtNo ratings yet
- Power Quality Performance of A Grid-Tie Photovoltaic System in ColombiaDocument7 pagesPower Quality Performance of A Grid-Tie Photovoltaic System in ColombiaMauro LozNo ratings yet
- TCS Sample QuestionsDocument5 pagesTCS Sample QuestionsAshokNo ratings yet
- Download Full Cyber Forensics From Data to Digital Evidence 1st Edition Albert J. Marcella Jr. PDF All ChaptersDocument60 pagesDownload Full Cyber Forensics From Data to Digital Evidence 1st Edition Albert J. Marcella Jr. PDF All Chapterslauffaivaoas100% (6)
- Powerdesigner - BPM Getting StartedDocument140 pagesPowerdesigner - BPM Getting StartedairaceNo ratings yet
- Eaton 93E 15-80 Kva Datasheet LRDocument2 pagesEaton 93E 15-80 Kva Datasheet LRAmarjitNo ratings yet
- SupplyChainManagement LuSwaminathan 2015Document17 pagesSupplyChainManagement LuSwaminathan 2015Warner LlaveNo ratings yet
- The Design and Implementation of FFT Algorithm Based On The Xilinx FPGA IP CoreDocument3 pagesThe Design and Implementation of FFT Algorithm Based On The Xilinx FPGA IP CoreĐông HưngNo ratings yet
- 2011 Webber-A Programmatic Introduction To Neo4jDocument66 pages2011 Webber-A Programmatic Introduction To Neo4jar15t0tleNo ratings yet
- Gmail - Order Confirmation Email For Metrobank Math Challenge 2020 - Form 1Document2 pagesGmail - Order Confirmation Email For Metrobank Math Challenge 2020 - Form 1Jayson TV100% (1)
- Time Sheet: Company NameDocument3 pagesTime Sheet: Company NameSwapnil SahuNo ratings yet
- Online Gas Booking and Agency Management SystemDocument39 pagesOnline Gas Booking and Agency Management Systemcrescent100% (1)
- Cad Details ReportDocument62 pagesCad Details ReportNurin MansoorNo ratings yet
- Simulation Mold FlowDocument10 pagesSimulation Mold FlowElvis Rivera AñaguariNo ratings yet
- DVCon Europe 2015 T13 PresentationDocument69 pagesDVCon Europe 2015 T13 PresentationJon DCNo ratings yet
- No.F.3 (101-2) - DHE/CASH/2019 Dated, Agartala, The - 2019Document4 pagesNo.F.3 (101-2) - DHE/CASH/2019 Dated, Agartala, The - 2019Anonymous vbqOOxOqNo ratings yet
- Pratixaben MeghaniDocument3 pagesPratixaben MeghaniKritika ShuklaNo ratings yet
- ICCSAP SizingConfigurationHA GuideDocument17 pagesICCSAP SizingConfigurationHA GuideMostafa AbuelkhairNo ratings yet