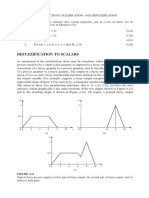
May 2021 Examination Diet School of Mathematics & Statistics MT4537
May 2021 Examination Diet School of Mathematics & Statistics MT4537
Download as pdf or txt
You might also like
- COMP1680 Coursework 1Document14 pagesCOMP1680 Coursework 1Tev WallaceNo ratings yet
- May 2021 Examination Diet School of Mathematics & Statistics ID5059Document6 pagesMay 2021 Examination Diet School of Mathematics & Statistics ID5059Tev WallaceNo ratings yet
- ContractDocument3 pagesContractIsak BerkovitzNo ratings yet
- Masks Common MovesDocument3 pagesMasks Common MovesTev WallaceNo ratings yet
- COMP1680 Coursework 1Document14 pagesCOMP1680 Coursework 1Tev WallaceNo ratings yet
- G10RS Example Exam Paper 2Document9 pagesG10RS Example Exam Paper 2Guluzada UlviNo ratings yet
- May2015 Examination Diet School of Mathematics & Statistics ID5059Document9 pagesMay2015 Examination Diet School of Mathematics & Statistics ID5059Tev WallaceNo ratings yet
- MT4614 ExamDocument13 pagesMT4614 ExamTev WallaceNo ratings yet
- Computer Graphics (ECS-504) 2011-12-2Document4 pagesComputer Graphics (ECS-504) 2011-12-2Ajay YadavNo ratings yet
- Object Class Segmentation Using Random ForestsDocument10 pagesObject Class Segmentation Using Random ForestsParagNo ratings yet
- Daa R16 Questions-2023Document2 pagesDaa R16 Questions-2023rajsing00004444No ratings yet
- Computer Science Tripos Part IDocument10 pagesComputer Science Tripos Part IHuxNo ratings yet
- Study Question FDS ModelDocument2 pagesStudy Question FDS ModelmancymithinNo ratings yet
- V1.3: A Toolbox For Geostatistical Modelling in Python: GstoolsDocument33 pagesV1.3: A Toolbox For Geostatistical Modelling in Python: GstoolsThyago OliveiraNo ratings yet
- 2023 June CST306-CDocument3 pages2023 June CST306-CktusemesterNo ratings yet
- Gis and Advance Remote Sensing Kce058Document2 pagesGis and Advance Remote Sensing Kce058HS EDITZNo ratings yet
- Adobe Scan Sep 27, 2024 (2)Document8 pagesAdobe Scan Sep 27, 2024 (2)vadapav111204No ratings yet
- Concrete Research XDocument6 pagesConcrete Research Xwilson20040209No ratings yet
- ENG4042 1 Control 4 201812-1Document7 pagesENG4042 1 Control 4 201812-1Armando Uriel LópezNo ratings yet
- An Accurate and Computationally Efficient ExplicitDocument9 pagesAn Accurate and Computationally Efficient ExplicitMarius AtanasiuNo ratings yet
- Time: 3 Hours Total Marks: 70Document2 pagesTime: 3 Hours Total Marks: 70ayush2021cs187No ratings yet
- MS 2 Que 2020Document3 pagesMS 2 Que 2020amarja.suyashNo ratings yet
- Un Modelo Geométrico de Matriz de Inclusión para El Análisis de Elementos Finitos Del Concreto A Múltiples EscalasDocument9 pagesUn Modelo Geométrico de Matriz de Inclusión para El Análisis de Elementos Finitos Del Concreto A Múltiples EscalasAaron Arango AyalaNo ratings yet
- Part A: Department of Computer Science and Engineering University of Rajshahi Sample QuestionDocument4 pagesPart A: Department of Computer Science and Engineering University of Rajshahi Sample QuestionHasibul HasanNo ratings yet
- DAA IA1 UpdatedDocument14 pagesDAA IA1 UpdatedR GAYATHRINo ratings yet
- ENG5022 1 Control M 201812Document7 pagesENG5022 1 Control M 201812Armando Uriel LópezNo ratings yet
- A Computational Framework For Boundary Representation of Solid SweepsDocument12 pagesA Computational Framework For Boundary Representation of Solid SweepsConkrang KajuNo ratings yet
- University of Edinburgh College of Science and Engineering School of InformaticsDocument5 pagesUniversity of Edinburgh College of Science and Engineering School of InformaticsfusionNo ratings yet
- Book 3 - Relations Functions Linear Relations Linear Systems 1Document47 pagesBook 3 - Relations Functions Linear Relations Linear Systems 1DaRealTruthNo ratings yet
- Ada Que BankDocument15 pagesAda Que BankJanvi GabaniNo ratings yet
- Metric and Topological SpacesDocument89 pagesMetric and Topological SpacesOrxan QasimovNo ratings yet
- Group B (Short Answer Type Questions)Document2 pagesGroup B (Short Answer Type Questions)SaYani SamaDdarNo ratings yet
- 2007 MPhil 1Document10 pages2007 MPhil 1Deri Andika BangunNo ratings yet
- DAA - SET 1 May 2016Document2 pagesDAA - SET 1 May 2016Anurag PatnaikuniNo ratings yet
- Sem 5 Put 2022-23Document8 pagesSem 5 Put 2022-23Jatin ChoudharyNo ratings yet
- CS222 1Document2 pagesCS222 1Riyaz ShaikNo ratings yet
- AprilMay 2023Document2 pagesAprilMay 2023Vaishali ThatiNo ratings yet
- JNTUH - B Tech - 2019 - 3 2 - May - R18 - ECE - 136BD DIP Digital Image ProcessingDocument2 pagesJNTUH - B Tech - 2019 - 3 2 - May - R18 - ECE - 136BD DIP Digital Image ProcessingSri KrishnaNo ratings yet
- Dec 2023Document4 pagesDec 2023nehagm253No ratings yet
- May - 2019Document2 pagesMay - 2019Srinivas Kumar PalvadiNo ratings yet
- L-2/T-Licse Date: 08/08/2017: - 'Ds (Jia)Document22 pagesL-2/T-Licse Date: 08/08/2017: - 'Ds (Jia)Na ThakaNo ratings yet
- EDA MODELDocument3 pagesEDA MODELK.VENKATESHNo ratings yet
- Nov Dec 2023Document3 pagesNov Dec 2023svvaishnavyNo ratings yet
- CS2910 SampleQsDocument5 pagesCS2910 SampleQsarun vilwanathanNo ratings yet
- DS7201 Advanced Digital Image Processing University Question Paper Nov Dec 2017Document2 pagesDS7201 Advanced Digital Image Processing University Question Paper Nov Dec 2017kamalanathan100% (1)
- Rbi Grade B (Depr) - Test-13Document3 pagesRbi Grade B (Depr) - Test-13avinash ranjanNo ratings yet
- 33 CFD-paper2Document5 pages33 CFD-paper2Nipun JamesNo ratings yet
- Btech Cs 5 Sem Design and Analysis of Algorithm Rcs502 2022Document1 pageBtech Cs 5 Sem Design and Analysis of Algorithm Rcs502 2022YASH GARGNo ratings yet
- KTU S6 Computer Science and EngineDocument4 pagesKTU S6 Computer Science and Enginei.net.twitteroneNo ratings yet
- Stat 401B HomeworkDocument9 pagesStat 401B HomeworkjuanEs2374pNo ratings yet
- Mathematical Foundation of Computer Science Oct-Nov 2019Document8 pagesMathematical Foundation of Computer Science Oct-Nov 2019Prasanna kumar MsNo ratings yet
- daa prevDocument7 pagesdaa prevShiva CharanNo ratings yet
- AprilMay-2023Document2 pagesAprilMay-2023sharmavenkatesh054No ratings yet
- Defuzzification To ScalarsDocument13 pagesDefuzzification To ScalarsJoel Edgar Fuertes MelendezNo ratings yet
- COS3751-202 2013 2 B PDFDocument6 pagesCOS3751-202 2013 2 B PDFFreePDFsNo ratings yet
- Fods Unit 3 Ict QPDocument3 pagesFods Unit 3 Ict QPSRIVARSHIKA SudhakarNo ratings yet
- The Figure in The Margin Indicate Full Marks Candidates Are Required To Give Their Answers in Their Own Words As Far As PracticableDocument2 pagesThe Figure in The Margin Indicate Full Marks Candidates Are Required To Give Their Answers in Their Own Words As Far As PracticableLn Amitav BiswasNo ratings yet
- AIML-CSBS 3rd Semester 2023Document33 pagesAIML-CSBS 3rd Semester 2023Menhazul AbdinNo ratings yet
- Comp Insem Apr22Document22 pagesComp Insem Apr22rohannso14No ratings yet
- WWW Manaresults Co inDocument5 pagesWWW Manaresults Co insathiya rajNo ratings yet
- Ipcv Midsem Btech III-march 2017 1Document2 pagesIpcv Midsem Btech III-march 2017 1Shrijeet Jain100% (1)
- SCT 3160619 Nov-2021Document2 pagesSCT 3160619 Nov-2021Harsh DarjiNo ratings yet
- (2022-23) NLP (KCS-072)Document2 pages(2022-23) NLP (KCS-072)chitrav274No ratings yet
- 2019-20 University PaperDocument2 pages2019-20 University PaperKhushi PachauriNo ratings yet
- Time Series Econometrics TSE48M1 Assignment: Due 25 June 2021 100 MARKSDocument3 pagesTime Series Econometrics TSE48M1 Assignment: Due 25 June 2021 100 MARKSluyandaNo ratings yet
- Calculus and Vectors - Chapter 1Document6 pagesCalculus and Vectors - Chapter 1myobNo ratings yet
- Log-Linear Models, Extensions, and ApplicationsFrom EverandLog-Linear Models, Extensions, and ApplicationsAleksandr AravkinNo ratings yet
- Cloud Computing CourseworkDocument4 pagesCloud Computing CourseworkTev WallaceNo ratings yet
- Knowledge Discovery and Data Mining: Lecture 11 - Tree Methods - IntroductionDocument49 pagesKnowledge Discovery and Data Mining: Lecture 11 - Tree Methods - IntroductionTev WallaceNo ratings yet
- Lecture20 SlidesDocument35 pagesLecture20 SlidesTev WallaceNo ratings yet
- May 2021 Examination Diet School of Mathematics & Statistics MT4614Document6 pagesMay 2021 Examination Diet School of Mathematics & Statistics MT4614Tev WallaceNo ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- Lecture 22Document64 pagesLecture 22Tev WallaceNo ratings yet
- 1.1 ID5059 1.2 Tom Kelsey - Jan 2021: February 15, 2021Document43 pages1.1 ID5059 1.2 Tom Kelsey - Jan 2021: February 15, 2021Tev WallaceNo ratings yet
- Two Way Slab RF CalculationDocument3 pagesTwo Way Slab RF CalculationJulfikar KhanNo ratings yet
- Kenmore 385.17630 Sewing Machine Instruction ManualDocument109 pagesKenmore 385.17630 Sewing Machine Instruction ManualiliiexpugnansNo ratings yet
- 2 QP + MSDocument34 pages2 QP + MSgsarjunaaNo ratings yet
- Cover Letter For Civil Engineer ResumeDocument7 pagesCover Letter For Civil Engineer Resumeaflkvapnf100% (1)
- Ec130-T2 05-22-00 24M-600FH InspectionDocument19 pagesEc130-T2 05-22-00 24M-600FH InspectionLatest RumorNo ratings yet
- Sika Carbodur: Product Data SheetDocument8 pagesSika Carbodur: Product Data SheetGoranPerovicNo ratings yet
- Red Flags in Financial Statements 1717394085Document17 pagesRed Flags in Financial Statements 1717394085Youssef MecherfiNo ratings yet
- Guidelines For Produced Water InjectionDocument28 pagesGuidelines For Produced Water InjectionleopumpkingNo ratings yet
- Management ReviewerDocument2 pagesManagement ReviewerRey Mark BarandaNo ratings yet
- FWD Pavement Surveys: Falling Weight Deflectometer SurveysDocument2 pagesFWD Pavement Surveys: Falling Weight Deflectometer SurveysyasNo ratings yet
- Alexis Thomas Aitken Curriculum Vitae: Personal InformationDocument9 pagesAlexis Thomas Aitken Curriculum Vitae: Personal InformationaaitkenNo ratings yet
- MRT Pick-Up LocationsDocument45 pagesMRT Pick-Up LocationsLeonardNo ratings yet
- How To Enable SMB 1Document6 pagesHow To Enable SMB 1it.rsudjatipadangNo ratings yet
- Proposal HMG-350JM SXKH Die Spotting PressDocument9 pagesProposal HMG-350JM SXKH Die Spotting Press846213No ratings yet
- SCDL Business Law Paper - 3Document7 pagesSCDL Business Law Paper - 3Kattey Spares100% (1)
- A Reference Architecture For Service Oriented Architecture (SOA)Document58 pagesA Reference Architecture For Service Oriented Architecture (SOA)Pravitha FlockhartNo ratings yet
- Solon Standard EnglishDocument30 pagesSolon Standard EnglishPuri PurwantariNo ratings yet
- GM Ngi 2.0 Nam Installation GuideDocument6 pagesGM Ngi 2.0 Nam Installation GuidepapirelliNo ratings yet
- Case Cacharel Corrected Colour Only WDocument22 pagesCase Cacharel Corrected Colour Only WDeta Detade0% (1)
- Registration Guidelines For Government Supplier Registration (GSR)Document17 pagesRegistration Guidelines For Government Supplier Registration (GSR)Tee SweesiNo ratings yet
- PDF Api 570 Awareness Coursepdf DDDocument23 pagesPDF Api 570 Awareness Coursepdf DDkareemNo ratings yet
- Multiple Choice QuestionsDocument19 pagesMultiple Choice QuestionsLizalyn DalaodaoNo ratings yet
- CHAPTER 25 Statement of Financial Position (Concept Map)Document1 pageCHAPTER 25 Statement of Financial Position (Concept Map)kateyy99No ratings yet
- 2015-07-28 General Alert - Escalator IncidentDocument3 pages2015-07-28 General Alert - Escalator IncidentTon marquesNo ratings yet
- Effectiveness of Training and Development ProgrammesDocument72 pagesEffectiveness of Training and Development ProgrammesAdharshNo ratings yet
- A Presentation On: ABC AnalysisDocument40 pagesA Presentation On: ABC AnalysisbansishrishtiNo ratings yet
- Reliance Jio Infocomm Ltd. - ResultDocument1 pageReliance Jio Infocomm Ltd. - ResultRajesh SinghNo ratings yet
- Operational Risk: An Overview: Dr. Richa Verma BajajDocument37 pagesOperational Risk: An Overview: Dr. Richa Verma BajajJoydeep Dutta100% (1)