DS Unit 3 Part 1
DS Unit 3 Part 1
Download as pdf or txt
You might also like
- NumPy NotesDocument13 pagesNumPy Notessiddhant bhandariNo ratings yet
- FDS Unit 4Document66 pagesFDS Unit 4shaliniboddu521No ratings yet
- Unit III - Data Manipulation Using PythonDocument16 pagesUnit III - Data Manipulation Using PythonSARAVANANNo ratings yet
- NumpyDocument10 pagesNumpyXY ZWNo ratings yet
- Cs3353 Fds Unit 4 Notes EduenggDocument44 pagesCs3353 Fds Unit 4 Notes EduenggGanesh KumarNo ratings yet
- 3 IntroToPython-PythonLibrariesDocument36 pages3 IntroToPython-PythonLibrariesHermine KouéNo ratings yet
- Data Science Handwritten Notes - 3Document26 pagesData Science Handwritten Notes - 3smartyanurag2803No ratings yet
- 2 - Numpy - Tutorial - Ipynb - ColaboratoryDocument10 pages2 - Numpy - Tutorial - Ipynb - ColaboratoryTayyab KhalilNo ratings yet
- Unit - IiiDocument79 pagesUnit - Iiirp402948No ratings yet
- Topic - 2 - The Basics of NumPy Arrays 1Document10 pagesTopic - 2 - The Basics of NumPy Arrays 1sobaba6180No ratings yet
- Numpy Day7Document12 pagesNumpy Day7Walid SassiNo ratings yet
- Lab Sheet 05 - Numpy and MatplotlibDocument12 pagesLab Sheet 05 - Numpy and MatplotlibSasmitha KalharaNo ratings yet
- Introduction To Numpy Pandas and MatplotlibDocument2 pagesIntroduction To Numpy Pandas and Matplotlibrk73462002No ratings yet
- NumpyDocument4 pagesNumpysumitpython.41No ratings yet
- The NumPy Array - A Structure For Efficient Numerical ComputationDocument9 pagesThe NumPy Array - A Structure For Efficient Numerical ComputationDaniel Camarena PerezNo ratings yet
- Unit 7 Python Libraries For Data ScienceDocument34 pagesUnit 7 Python Libraries For Data Scienceutsavsutariya066No ratings yet
- Unit 5Document75 pagesUnit 5bunny030505No ratings yet
- NumpyDocument71 pagesNumpyNaiwrit KarmodakNo ratings yet
- Unit - VDocument75 pagesUnit - Vgokul100% (1)
- Numpy Complete NotesDocument64 pagesNumpy Complete NotesAydan KazimzadeNo ratings yet
- Num PyDocument21 pagesNum PyRedmi 11t 5gNo ratings yet
- NumPy Library and FunctionDocument129 pagesNumPy Library and FunctiongargishankarNo ratings yet
- Machine Learning NotesDocument52 pagesMachine Learning NotesBhagyashri RaneNo ratings yet
- Unit 3 NumpyDocument23 pagesUnit 3 Numpyrp402948No ratings yet
- CS229 Section: Python Tutorial: Maya SrikanthDocument39 pagesCS229 Section: Python Tutorial: Maya SrikanthTrần Thành LongNo ratings yet
- Fundamentals of Data Science Lab ManualDocument34 pagesFundamentals of Data Science Lab ManualragunathNo ratings yet
- A Selection of Useful Numpy Core Functions: Greg Von WinckelDocument14 pagesA Selection of Useful Numpy Core Functions: Greg Von WinckelFredrick MutungaNo ratings yet
- Numpy 1721963082Document68 pagesNumpy 1721963082Nilakhya ChawrokNo ratings yet
- Numpy Pyhton TutorialDocument28 pagesNumpy Pyhton TutorialskreddyvgstNo ratings yet
- python-notes-BCC-302 (Unit - 05)Document25 pagespython-notes-BCC-302 (Unit - 05)lokeshkumarrathore9696No ratings yet
- 10 NumpyDocument39 pages10 NumpyOguljan NuryyevaNo ratings yet
- Unit 5Document60 pagesUnit 5daraboinaharisupriyaNo ratings yet
- Numpy NotesDocument170 pagesNumpy NotesCayden James100% (1)
- Numpy - Tutorial - Ipynb - ColaboratoryDocument9 pagesNumpy - Tutorial - Ipynb - ColaboratoryAtul Kumar UttamNo ratings yet
- Lecture 2 - NumPy IDocument12 pagesLecture 2 - NumPy IAnkit SinghNo ratings yet
- Introduction To Numpy - Ipynb - ColaboratoryDocument11 pagesIntroduction To Numpy - Ipynb - ColaboratoryVincent GiangNo ratings yet
- IP Class-XI Chapter-9 NOTESDocument14 pagesIP Class-XI Chapter-9 NOTESRituNagpal IpisNo ratings yet
- PrintDocument296 pagesPrintMohammed ZameerNo ratings yet
- Unit Iii Using NumpyDocument23 pagesUnit Iii Using NumpyMohanNo ratings yet
- Informatics Practices: Numpy - ArrayDocument28 pagesInformatics Practices: Numpy - ArrayAmit Kumar100% (1)
- Lecture+Notes Python+for+DS PDFDocument48 pagesLecture+Notes Python+for+DS PDFRohit AsthanaNo ratings yet
- AI LabfileDocument29 pagesAI Labfilevirgulatiit21a1068No ratings yet
- Numpy in PandasDocument30 pagesNumpy in PandasKiran KumarNo ratings yet
- Numpy - ArrayDocument21 pagesNumpy - ArrayDEPT BCA RABIATHUL BASIRIYANo ratings yet
- Ch-2 Python Libraries For MLDocument70 pagesCh-2 Python Libraries For MLyashbhimani24082004No ratings yet
- HUAWEI - 04 Third-Party LibrariesDocument59 pagesHUAWEI - 04 Third-Party LibrariesPierpaolo VergatiNo ratings yet
- Unit 4Document19 pagesUnit 4arjunNo ratings yet
- Numpy - Basics - Jupyter NotebookDocument9 pagesNumpy - Basics - Jupyter Notebookhuzaifa khawarNo ratings yet
- Numpy Array11Document23 pagesNumpy Array11satyajitsethy2301No ratings yet
- Module3 Advance PythonlibrariesDocument53 pagesModule3 Advance Pythonlibrariesshubhangc6No ratings yet
- Python Chapter-10,11,12,13Document31 pagesPython Chapter-10,11,12,13Mubeena NasirNo ratings yet
- II CSE CS3352 FDS QB Unit4Document6 pagesII CSE CS3352 FDS QB Unit4ucebittrichy2020100% (1)
- NumPY ArrayDocument8 pagesNumPY ArrayerivaldomnNo ratings yet
- CodesDocument7 pagesCodesManeesh DarisiNo ratings yet
- Num PyDocument13 pagesNum PyHarib KhanNo ratings yet
- 3rd UnitDocument75 pages3rd UnitDharma Teja Sunkara100% (1)
- Program No.08 Ipmlement Various in Built Functions of NumPy LibraryDocument13 pagesProgram No.08 Ipmlement Various in Built Functions of NumPy Librarykpraj447No ratings yet
- FDS Lab 1 Manuel .1..1newDocument38 pagesFDS Lab 1 Manuel .1..1newbaisurasNo ratings yet
- Week 9Document27 pagesWeek 9Betül ÖztürkNo ratings yet
- Quality Control by Taguchi Method: Presented By: Pankaj Raj 1002009 Amit Kumar Sharma 1002010Document24 pagesQuality Control by Taguchi Method: Presented By: Pankaj Raj 1002009 Amit Kumar Sharma 1002010Amit Kumar SharmaNo ratings yet
- GSLFDocument2 pagesGSLFRaul Marihuan GonzálezNo ratings yet
- Data Science SpecializationsDocument164 pagesData Science SpecializationsAhmed AliNo ratings yet
- Composite Design and TheoryDocument203 pagesComposite Design and Theoryapi-3700351100% (6)
- Jee Main 2021: Crash Course DPP Matrices & DeterminantsDocument70 pagesJee Main 2021: Crash Course DPP Matrices & DeterminantsShubham MaheshwariNo ratings yet
- Practice Final ExamDocument3 pagesPractice Final ExamRaman SinghNo ratings yet
- Face Recognization Using OpenCv - ReportDocument37 pagesFace Recognization Using OpenCv - ReportRamaadyuti BattabyalNo ratings yet
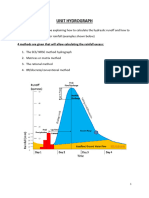
- Unit Hydrograph New Spring 22Document10 pagesUnit Hydrograph New Spring 22Majid YassineNo ratings yet
- Mte 02 e (2016)Document5 pagesMte 02 e (2016)Alok ThakkarNo ratings yet
- Linear Algebra Midterm ExamDocument3 pagesLinear Algebra Midterm Examhufana.dishelleanneNo ratings yet
- Chapter 5. Regression Models: 1 A Simple ModelDocument49 pagesChapter 5. Regression Models: 1 A Simple ModelPiNo ratings yet
- B Tech EEE R2023Document57 pagesB Tech EEE R2023hariNo ratings yet
- LabExam Huzaifa Karbalai 18591Document3 pagesLabExam Huzaifa Karbalai 18591HuzaifaNo ratings yet
- Me RoboticsDocument17 pagesMe RoboticsmohanmzcetNo ratings yet
- Quiz MathematicsDocument8 pagesQuiz MathematicsumaNo ratings yet
- 6 - Discrete Markov ChainsDocument34 pages6 - Discrete Markov ChainsA Hasib ChowdhuryNo ratings yet
- 2013 Matrices Multiple Choice RevisionDocument22 pages2013 Matrices Multiple Choice Revisionbanking kida all hereNo ratings yet
- Finite Fields and Error-Correcting Codes: Lecture Notes in MathematicsDocument54 pagesFinite Fields and Error-Correcting Codes: Lecture Notes in MathematicsyashbhardwajNo ratings yet
- Welcome To The Project Presentation On Number PlateDocument21 pagesWelcome To The Project Presentation On Number Plateapi-3696125100% (1)
- Linear Algebra For Business AnalyticsDocument27 pagesLinear Algebra For Business AnalyticsBom VillatuyaNo ratings yet
- A Student's Guide To Geophysical Equations (W. Lowrie 2011) PDFDocument296 pagesA Student's Guide To Geophysical Equations (W. Lowrie 2011) PDFFabian Martinez100% (8)
- AE6601 - Finite Element Method Two MarksDocument5 pagesAE6601 - Finite Element Method Two MarksAravind Phoenix100% (2)
- Dont Copy It Is On Turnitin LolDocument11 pagesDont Copy It Is On Turnitin LolMaan PatelNo ratings yet
- Multivariable Mathematics With Maple - Linear Algebra, Vector Calculus and Differential - Carlson & JohnsonDocument40 pagesMultivariable Mathematics With Maple - Linear Algebra, Vector Calculus and Differential - Carlson & JohnsonGlauber Marques100% (1)
- Introduction To MatricesDocument40 pagesIntroduction To MatricesAbd Rahman IbrahimNo ratings yet
- MIT18 065S18PSetsDocument36 pagesMIT18 065S18PSetsCarlos Enciso OjedaNo ratings yet
- Solutions Xii Maths Sample Paper 13Document16 pagesSolutions Xii Maths Sample Paper 13haarithali123321No ratings yet
- Maths XII Periodic Test-1 Sample Paper 01 2019Document2 pagesMaths XII Periodic Test-1 Sample Paper 01 2019darkmarkNo ratings yet
- The Fractional Fourier Transform: Theory, Implementation and Error AnalysisDocument11 pagesThe Fractional Fourier Transform: Theory, Implementation and Error AnalysisrajachakrabortyNo ratings yet
- Brauers&Weber - A New Method of Scenario Analysis For Strategic PlanningDocument18 pagesBrauers&Weber - A New Method of Scenario Analysis For Strategic Planningi970001No ratings yet