0% found this document useful (0 votes)
15 viewsFuzzy Set
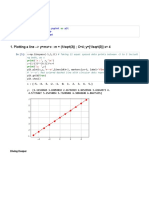
The document discusses fuzzy set theory and fuzzy logic concepts. It defines fuzzy sets, takes user input to assign membership values to fuzzy sets, and performs operations like union and intersection on the fuzzy sets. It then implements triangular, trapezoidal, and Gaussian membership functions and takes user input to evaluate membership values. Genetic algorithm concepts like encoding, crossover, and evaluation are also demonstrated for optimization problems.
Uploaded by
Mohshin KhanCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
15 viewsFuzzy Set
The document discusses fuzzy set theory and fuzzy logic concepts. It defines fuzzy sets, takes user input to assign membership values to fuzzy sets, and performs operations like union and intersection on the fuzzy sets. It then implements triangular, trapezoidal, and Gaussian membership functions and takes user input to evaluate membership values. Genetic algorithm concepts like encoding, crossover, and evaluation are also demonstrated for optimization problems.
Uploaded by
Mohshin KhanCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 20