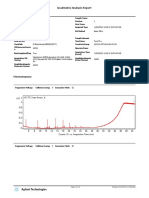
Technologyname Phase2
Technologyname Phase2
Download as docx, pdf, or txt
You might also like
- Predictive-Modelling-Project - Graded Project - Predictive Modeling - Business Report - PDF at Main Aadyatomar - Predictive-Modelling-Project GitHubDocument64 pagesPredictive-Modelling-Project - Graded Project - Predictive Modeling - Business Report - PDF at Main Aadyatomar - Predictive-Modelling-Project GitHubStocknEarn100% (8)
- Series4 - Renata Putri HenessaDocument12 pagesSeries4 - Renata Putri HenessaPerfect DarksideNo ratings yet
- Data Munging - Ipynb - Colaboratory - Yodhi Adhi SanjayaDocument4 pagesData Munging - Ipynb - Colaboratory - Yodhi Adhi SanjayaadhiNo ratings yet
- Retail Analysis WalmartDocument18 pagesRetail Analysis WalmartNavin MathadNo ratings yet
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- PembelajaranMesin - Ipynb - ColaboratoryDocument6 pagesPembelajaranMesin - Ipynb - ColaboratoryKhaerul RijalNo ratings yet
- Admn2607 SD2Document21 pagesAdmn2607 SD2Thomas-Jay DerbyshireNo ratings yet
- Walmart - Sales: Pandas PD Seaborn Sns Numpy NP Matplotlib - Pyplot PLT Matplotlib DatetimeDocument26 pagesWalmart - Sales: Pandas PD Seaborn Sns Numpy NP Matplotlib - Pyplot PLT Matplotlib DatetimeRamaseshu Machepalli100% (1)
- Pca Implementation NotebookDocument4 pagesPca Implementation NotebookWalid SassiNo ratings yet
- BCG Virtual Experience Task 3 Feature Engineering1Document12 pagesBCG Virtual Experience Task 3 Feature Engineering1yomolojaNo ratings yet
- Bài tập buổi 9Document50 pagesBài tập buổi 9Văng Ngọc Quỳnh NhưNo ratings yet
- Decision Science: Sales (INR 000s)Document17 pagesDecision Science: Sales (INR 000s)Sparsh GargNo ratings yet
- Credit Default Practice PDFDocument27 pagesCredit Default Practice PDFSravan100% (1)
- Competitive Bidding StrategyDocument38 pagesCompetitive Bidding StrategyKen WongNo ratings yet
- Assessment 2Document11 pagesAssessment 2Researchpro GlobalNo ratings yet
- ALTHEA MAE AMIL Final ExamDocument15 pagesALTHEA MAE AMIL Final ExamKaren MagsayoNo ratings yet
- Agile Hype Cycle - Zaina AbuAbedDocument10 pagesAgile Hype Cycle - Zaina AbuAbedZaina ShtaiwiNo ratings yet
- Controller Servlet 1Document1 pageController Servlet 1bootstrap24No ratings yet
- Case: Winter Park Hotel (Current System) : Queuing Model M/M/s (Exponential Service Times)Document35 pagesCase: Winter Park Hotel (Current System) : Queuing Model M/M/s (Exponential Service Times)Gajendra SinghNo ratings yet
- KMeans Clustering Bidimensional Daniel Ames CamayoDocument15 pagesKMeans Clustering Bidimensional Daniel Ames CamayoEl RusnderNo ratings yet
- Maruti and HyundaiDocument22 pagesMaruti and HyundaiKunal Matani0% (1)
- Applied Numerical Methods (SME 3023) : Ua Uaha Deaha Deaha AyhayDocument24 pagesApplied Numerical Methods (SME 3023) : Ua Uaha Deaha Deaha AyhayYahya Ahmed AlduqriNo ratings yet
- Facebook's ProphetDocument10 pagesFacebook's ProphetKyle MurphyNo ratings yet
- Soal MultivariatDocument6 pagesSoal MultivariatHana Sekar Ayu EpNo ratings yet
- Aerasi - AnalysisReportWithMFGResultsDocument13 pagesAerasi - AnalysisReportWithMFGResultseti apriyantiNo ratings yet
- Minimos Cuadrados: K AÑO Oferta Xy X 2 Y (Y-Y)Document12 pagesMinimos Cuadrados: K AÑO Oferta Xy X 2 Y (Y-Y)EvilLordMuMexNo ratings yet
- Amazon Stocks PriceDocument16 pagesAmazon Stocks PriceDineshkumar VhananavarNo ratings yet
- Linear Trend Line Forecast: Year Printers Forecas T Error 1 2 3 4 5 6 7 8 9 10 11Document4 pagesLinear Trend Line Forecast: Year Printers Forecas T Error 1 2 3 4 5 6 7 8 9 10 11SURAJ GAVITNo ratings yet
- Q2-Decision Science-FinalDocument4 pagesQ2-Decision Science-Finalsuhasini authuNo ratings yet
- MLR-handson - Jupyter NotebookDocument5 pagesMLR-handson - Jupyter NotebookAnzal MalikNo ratings yet
- The Banker Database Sample Data 2023Document38 pagesThe Banker Database Sample Data 20232001 HeyaDarjiNo ratings yet
- Course Wise ReportDocument2 pagesCourse Wise Reportsoumya.riseitNo ratings yet
- A CMG F M: Dvanced LOW OdellingDocument65 pagesA CMG F M: Dvanced LOW OdellingwasayrazaNo ratings yet
- Data Preprocessing ML LabDocument6 pagesData Preprocessing ML Labmohan kukrejaNo ratings yet
- Joel1 OriginalDocument6 pagesJoel1 OriginalPedro PomezNo ratings yet
- Uts Lab Pengujian StrukturDocument11 pagesUts Lab Pengujian StrukturriangruslanNo ratings yet
- ES Calculator vs1f (Special Cases)Document40 pagesES Calculator vs1f (Special Cases)Jonnathan Jessus CqNo ratings yet
- TALLER 6 ProbabilidadDocument16 pagesTALLER 6 ProbabilidadNoemy RomeroNo ratings yet
- Practice Problems Correlation Regression Aug 3 2024Document3 pagesPractice Problems Correlation Regression Aug 3 2024Romer EnajeNo ratings yet
- Lecture7appendixa 12thsep2009Document31 pagesLecture7appendixa 12thsep2009Richa ShekharNo ratings yet
- Pronosticos - Ipynb - ColaboratoryDocument13 pagesPronosticos - Ipynb - ColaboratoryFrancisco Javier RESTREPO GRANOBLESNo ratings yet
- Book 2Document4 pagesBook 2jesus castilloNo ratings yet
- Ecotric ProjectDocument3 pagesEcotric Projectaadolf2004No ratings yet
- MACD Calculation For Yahoo Finance BTC-USD - Jupyter NotebookDocument7 pagesMACD Calculation For Yahoo Finance BTC-USD - Jupyter NotebookSree Lakshmi DeeviNo ratings yet
- Decision Science 5tknniDocument17 pagesDecision Science 5tknnikarunakar vNo ratings yet
- LAB14Document12 pagesLAB14Yuvraj WaleNo ratings yet
- Raport SaschizDocument7 pagesRaport SaschizCatalinNo ratings yet
- 优秀科技创新人才培养(优秀青年基础研究)项目申请书 2Document19 pages优秀科技创新人才培养(优秀青年基础研究)项目申请书 2cherishcqxNo ratings yet
- Excel Practice Assignment 1Document5 pagesExcel Practice Assignment 1singhshekar230No ratings yet
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- US - Growth Accounts - Problem - SetDocument321 pagesUS - Growth Accounts - Problem - Setfwm949fwxrNo ratings yet
- AcasestudyonkodakdownfallDocument8 pagesAcasestudyonkodakdownfallJonnaline AlfonNo ratings yet
- Name: Ngoc Anh Nguyen (Jenny) CEG: 08119210 What Effect Does The GDP Have On The Inflation? Between Australia and GermanyDocument25 pagesName: Ngoc Anh Nguyen (Jenny) CEG: 08119210 What Effect Does The GDP Have On The Inflation? Between Australia and GermanyAnh Nguyen NgocNo ratings yet
- DLL 7 Harsh Kabir 2203254Document6 pagesDLL 7 Harsh Kabir 2203254Darshil RajNo ratings yet
- Overview-Trend-2024-07-12t12 - 01 - 02Z - PipedriveDocument4 pagesOverview-Trend-2024-07-12t12 - 01 - 02Z - Pipedriverickmga10No ratings yet
- 5th Girder Normal TrafficDocument33 pages5th Girder Normal TrafficRenxiang LuNo ratings yet
- Accountancy JoanDocument6 pagesAccountancy Joansalimsaihan6No ratings yet
- How To Perform Common Excel Commands in Python: Reading The DataDocument3 pagesHow To Perform Common Excel Commands in Python: Reading The DataBenjamin Cabalona Jr.No ratings yet
- BS SRR-3Document20 pagesBS SRR-3anveshvarma365No ratings yet