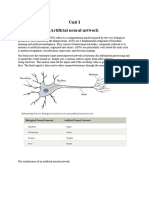
ML tushar assignment
ML tushar assignment
Download as pdf or txt
You might also like
- Unit 1 NNDLDocument8 pagesUnit 1 NNDLT. S kesavNo ratings yet
- Unit_2Document20 pagesUnit_2ISHU KUMARNo ratings yet
- Supervised LearningDocument14 pagesSupervised LearningSankari SoniNo ratings yet
- DL Question Bank AnswersDocument55 pagesDL Question Bank AnswersAnkit MahapatraNo ratings yet
- Artificial Neural NetworksDocument66 pagesArtificial Neural NetworkselakkadanNo ratings yet
- Unit 1Document19 pagesUnit 1Mohamed riyanNo ratings yet
- Neural Network: Throughout The Whole Network, Rather Than at Specific LocationsDocument8 pagesNeural Network: Throughout The Whole Network, Rather Than at Specific LocationsSrijal ManandharNo ratings yet
- ANN PG Module1Document75 pagesANN PG Module1Sreerag Kunnathu SugathanNo ratings yet
- Artificial Neural Network: Synapses Weight The Individual Parts of InformationDocument8 pagesArtificial Neural Network: Synapses Weight The Individual Parts of InformationMaryam FarisNo ratings yet
- Unit2 Soft ComputingDocument22 pagesUnit2 Soft ComputingRAPTER GAMINGNo ratings yet
- Lecture 2.1.2 Single Layer NetworkDocument4 pagesLecture 2.1.2 Single Layer NetworkMuskan GahlawatNo ratings yet
- 19 - Introduction To Neural NetworksDocument7 pages19 - Introduction To Neural NetworksRugalNo ratings yet
- Neural NetworksDocument27 pagesNeural Networksrandom98appNo ratings yet
- Artifical Neural NetworkDocument69 pagesArtifical Neural NetworkVikash YadavNo ratings yet
- Lecture-02: PGDDS 202Document15 pagesLecture-02: PGDDS 202Lony IslamNo ratings yet
- MainDocument25 pagesMainharipavanchoudampalliNo ratings yet
- Unit IIIDocument37 pagesUnit IIIajankit0712No ratings yet
- ch1 of artificial newral networkDocument20 pagesch1 of artificial newral networkDanish SharmaNo ratings yet
- NNunit 2Document25 pagesNNunit 2Shaik ReshmaNo ratings yet
- Unit - 4Document26 pagesUnit - 4UNISA SAKHANo ratings yet
- Ann MJJ-1Document64 pagesAnn MJJ-1RohitNo ratings yet
- UNIT_1_DLDocument18 pagesUNIT_1_DLssuresh.pecNo ratings yet
- SC - Unit 2Document50 pagesSC - Unit 2teacher2No ratings yet
- UNit 6 Machine LearningDocument23 pagesUNit 6 Machine LearningAyan ShaikhNo ratings yet
- Unit I - AfsDocument18 pagesUnit I - Afsbeelogger4321No ratings yet
- Back-Propagation Algorithm of CHBPN CodeDocument10 pagesBack-Propagation Algorithm of CHBPN Codesch203No ratings yet
- ML Unit-2Document141 pagesML Unit-26644 HaripriyaNo ratings yet
- Back Propagation AlgorithmDocument13 pagesBack Propagation AlgorithmHerald RufusNo ratings yet
- Ann Mid1: Artificial Neural Networks With Biological Neural Network - SimilarityDocument13 pagesAnn Mid1: Artificial Neural Networks With Biological Neural Network - SimilaritySirishaNo ratings yet
- Networks With Threshold Activation Functions: NavigationDocument6 pagesNetworks With Threshold Activation Functions: NavigationsandmancloseNo ratings yet
- Uni2 NNDLDocument21 pagesUni2 NNDLSONY P J 2248440No ratings yet
- Neural Networks and CNNDocument25 pagesNeural Networks and CNNcn8q8nvnd5No ratings yet
- Perceptron: Single Layer Neural NetworkDocument14 pagesPerceptron: Single Layer Neural NetworkGayuNo ratings yet
- Fundamentals of Artificial Neural NetworksDocument27 pagesFundamentals of Artificial Neural Networksbhaskar rao mNo ratings yet
- 20200428135045cfbc718e2c (1)Document30 pages20200428135045cfbc718e2c (1)159997111005No ratings yet
- IT 701 Soft Computing Unit II - 1722317891Document13 pagesIT 701 Soft Computing Unit II - 1722317891Mohit ShindeNo ratings yet
- Learning Law in Neural NetworksDocument19 pagesLearning Law in Neural NetworksMani Singh100% (2)
- Session 1Document8 pagesSession 1Ramu ThommandruNo ratings yet
- Chapters 1-4Document6 pagesChapters 1-4bebo fayezNo ratings yet
- Module 5 AIML NotesDocument77 pagesModule 5 AIML Notesbabureddybn262003No ratings yet
- IML5Document21 pagesIML5lakshmirandhawa143No ratings yet
- ANNDocument3 pagesANNmuhammadhamzaansari06No ratings yet
- Institute For Advanced Management Systems Research Department of Information Technologies Abo Akademi UniversityDocument41 pagesInstitute For Advanced Management Systems Research Department of Information Technologies Abo Akademi UniversityKarthikeyanNo ratings yet
- A Presentation On: By: EdutechlearnersDocument33 pagesA Presentation On: By: EdutechlearnersshardapatelNo ratings yet
- Unit 2 - Soft Computing - WWW - Rgpvnotes.inDocument17 pagesUnit 2 - Soft Computing - WWW - Rgpvnotes.inhimanshu yadavNo ratings yet
- Unit 5Document77 pagesUnit 5rahuljssstuNo ratings yet
- Unit 2 Deep LearningDocument19 pagesUnit 2 Deep Learningsahil.utube2003No ratings yet
- Soft Computing Perceptron Neural Network in MATLABDocument8 pagesSoft Computing Perceptron Neural Network in MATLABSainath ParkarNo ratings yet
- Uni2 NN 2023Document52 pagesUni2 NN 2023SONY P J 2248440No ratings yet
- Unit 4Document9 pagesUnit 4akkiketchumNo ratings yet
- Unit - 2Document24 pagesUnit - 2vvvcxzzz3754No ratings yet
- ML Unit-IvDocument19 pagesML Unit-IvYadavilli VinayNo ratings yet
- Neural Networks NotesDocument22 pagesNeural Networks NoteszomukozaNo ratings yet
- Unit 2 - Soft ComputingDocument49 pagesUnit 2 - Soft ComputingNitesh NemaNo ratings yet
- Unit-5 AIDocument19 pagesUnit-5 AIJagathdhathri KRNo ratings yet
- Deep Learning Unit 2Document30 pagesDeep Learning Unit 2Aditya Pratap SinghNo ratings yet
- NNFL Unit III For ECE & EEEDocument29 pagesNNFL Unit III For ECE & EEEPraneeth MNo ratings yet
- MLP 2Document12 pagesMLP 2KALYANpwnNo ratings yet
- Advances in DIP: (Fuzzy, Artificial Neural Networks, Expert System and Image Segmentation)Document67 pagesAdvances in DIP: (Fuzzy, Artificial Neural Networks, Expert System and Image Segmentation)Farid_ZGNo ratings yet
- Competitive Learning: Fundamentals and Applications for Reinforcement Learning through CompetitionFrom EverandCompetitive Learning: Fundamentals and Applications for Reinforcement Learning through CompetitionNo ratings yet
- Additions Viva Questions CGDocument19 pagesAdditions Viva Questions CGTUSHAR AHUJANo ratings yet
- diabeties minor-36Document1 pagediabeties minor-36TUSHAR AHUJANo ratings yet
- Cloud_Computing_Question_Bank_Unit_3_and_4Document1 pageCloud_Computing_Question_Bank_Unit_3_and_4TUSHAR AHUJANo ratings yet
- Cloud_Computing_Architecture_Unit_2_NotesDocument5 pagesCloud_Computing_Architecture_Unit_2_NotesTUSHAR AHUJANo ratings yet
- UNIT 3Document46 pagesUNIT 3TUSHAR AHUJANo ratings yet
- Cloud_Computing_Overview_Brief_notes(Unit_1)Document5 pagesCloud_Computing_Overview_Brief_notes(Unit_1)TUSHAR AHUJANo ratings yet
- diabeties minor-35Document1 pagediabeties minor-35TUSHAR AHUJANo ratings yet
- diabeties minor-39Document1 pagediabeties minor-39TUSHAR AHUJANo ratings yet
- diabeties minor-33Document1 pagediabeties minor-33TUSHAR AHUJANo ratings yet
- diabeties minor-31Document1 pagediabeties minor-31TUSHAR AHUJANo ratings yet
- Diabeties Minor 25Document1 pageDiabeties Minor 25TUSHAR AHUJANo ratings yet
- diabeties minor-37Document1 pagediabeties minor-37TUSHAR AHUJANo ratings yet
- diabeties minor-24Document1 pagediabeties minor-24TUSHAR AHUJANo ratings yet
- Diabeties Minor 34Document1 pageDiabeties Minor 34TUSHAR AHUJANo ratings yet
- diabeties minor-29Document1 pagediabeties minor-29TUSHAR AHUJANo ratings yet
- diabeties minor-35Document1 pagediabeties minor-35TUSHAR AHUJANo ratings yet
- diabeties minor-37Document1 pagediabeties minor-37TUSHAR AHUJANo ratings yet
- diabeties minor-28Document1 pagediabeties minor-28TUSHAR AHUJANo ratings yet
- diabeties minor-26Document1 pagediabeties minor-26TUSHAR AHUJANo ratings yet
- diabeties minor-40Document1 pagediabeties minor-40TUSHAR AHUJANo ratings yet
- diabeties minor-4Document1 pagediabeties minor-4TUSHAR AHUJANo ratings yet
- diabeties minor-36Document1 pagediabeties minor-36TUSHAR AHUJANo ratings yet
- diabeties minor-22Document1 pagediabeties minor-22TUSHAR AHUJANo ratings yet
- diabeties minor-23Document1 pagediabeties minor-23TUSHAR AHUJANo ratings yet
- Diabeties Minor 37Document1 pageDiabeties Minor 37TUSHAR AHUJANo ratings yet
- CG 2024Document71 pagesCG 2024TUSHAR AHUJANo ratings yet
- Tushar MLDocument52 pagesTushar MLTUSHAR AHUJANo ratings yet
- diabeties minorDocument48 pagesdiabeties minorTUSHAR AHUJANo ratings yet
- CG 2023Document68 pagesCG 2023TUSHAR AHUJANo ratings yet
- CG 2019Document58 pagesCG 2019TUSHAR AHUJANo ratings yet
- Super Teacher Worksheets in The ClassroomDocument4 pagesSuper Teacher Worksheets in The Classroomarius33No ratings yet
- Valiant Sayer Campus JournDocument10 pagesValiant Sayer Campus JournRichster John Macaballug ISUCNo ratings yet
- ENGG105 Guide To Report Writing and PresentingDocument69 pagesENGG105 Guide To Report Writing and PresentingAsfin HaqueNo ratings yet
- Course Outline Dfn50343 Ent Network - Sesi220232024Document4 pagesCourse Outline Dfn50343 Ent Network - Sesi220232024Sarvinderkumar MuthukkumarNo ratings yet
- Lesson Plan Writing: Ccss - Ela-Literacy.W.4.2Document10 pagesLesson Plan Writing: Ccss - Ela-Literacy.W.4.2api-528470094No ratings yet
- KOPI ROBUSTA (Coffea Canephora), KOPI ARABIKA (Coffea Metode Spektrofotometri Uv-VisDocument7 pagesKOPI ROBUSTA (Coffea Canephora), KOPI ARABIKA (Coffea Metode Spektrofotometri Uv-VisINDAH KUSUMA NINGRUM 1No ratings yet
- NAPLAN Yr 3 Numeracy Test-2Document11 pagesNAPLAN Yr 3 Numeracy Test-2newsmanauNo ratings yet
- Professional Development Project Plan PDPP - Group 6 Organisational Behaviour Term 1Document12 pagesProfessional Development Project Plan PDPP - Group 6 Organisational Behaviour Term 1Aritra DasNo ratings yet
- 0625 Magnetism Electromag Only s16Document10 pages0625 Magnetism Electromag Only s16Ishtiyaq AhmedNo ratings yet
- Bus FeeDocument1 pageBus FeeHimaswetha SnNo ratings yet
- Making A Poster Rubric 1Document1 pageMaking A Poster Rubric 1Jamaica Malunes ManuelNo ratings yet
- Summit Learning RubricDocument11 pagesSummit Learning Rubricapi-253497489No ratings yet
- MR. AND MS. INTRAMURALS 2021 FlowDocument5 pagesMR. AND MS. INTRAMURALS 2021 Flownas.eirikajoyguiamNo ratings yet
- Group Assignment 6Document3 pagesGroup Assignment 6P Q Thu AnhNo ratings yet
- Application FormDocument5 pagesApplication FormMagak OdhiamboNo ratings yet
- DLL October 10 14 2022. SteDocument5 pagesDLL October 10 14 2022. SteJoeric CarinanNo ratings yet
- API CalculatorDocument5 pagesAPI Calculatorkameswara rao PorankiNo ratings yet
- Cevas Theorem Written by Sir Abdul BasitDocument3 pagesCevas Theorem Written by Sir Abdul BasitSHK-NiaziNo ratings yet
- Lecture 3 Communication SkillsDocument35 pagesLecture 3 Communication SkillsKalule CyprianNo ratings yet
- EDL 101 Management Function BehaviorDocument12 pagesEDL 101 Management Function Behaviorakash deepNo ratings yet
- PracticalDocument5 pagesPracticalMarjorrie C. BritalNo ratings yet
- VSEPR Paper GillespieDocument11 pagesVSEPR Paper GillespieRicardo J. Fernández-TeránNo ratings yet
- MUET Paper 4 Writing Question 2 Extended Writing 1Document2 pagesMUET Paper 4 Writing Question 2 Extended Writing 1Seara ZhaoNo ratings yet
- CO1-Lesson PlanDocument8 pagesCO1-Lesson PlanYongco MarloNo ratings yet
- Stagizine 2018Document45 pagesStagizine 2018zoibaNo ratings yet
- Achievement TestDocument4 pagesAchievement TestAbhiNo ratings yet
- CytologyDocument4 pagesCytologysubashzerstorer5No ratings yet
- Career Planning - Industrial View (Noon, Rolls Royce, 2011)Document19 pagesCareer Planning - Industrial View (Noon, Rolls Royce, 2011)arnauNo ratings yet
- The Perceptions Towards Teenage Pregnancy in The Philippines of The Senior High School Students of The Laguna Belair Science SchoolDocument28 pagesThe Perceptions Towards Teenage Pregnancy in The Philippines of The Senior High School Students of The Laguna Belair Science SchoolAngelina Julia I. BautistaNo ratings yet
- MidTerm POM 106201 (Ahmar Iqbal 10713)Document6 pagesMidTerm POM 106201 (Ahmar Iqbal 10713)Ahsan IqbalNo ratings yet