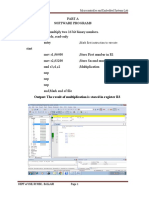
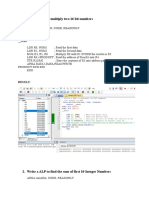
Arithmetic Instructions
Arithmetic Instructions
Download as pptx, pdf, or txt
You might also like
- QRC0001H RVCT v2.1 ThumbDocument4 pagesQRC0001H RVCT v2.1 ThumbhisriharibabuNo ratings yet
- 935 Robert Bosch Interview Questions in C A Micro Controllers PDFDocument2 pages935 Robert Bosch Interview Questions in C A Micro Controllers PDFdhapra0% (1)
- TCS Database QuestionsDocument23 pagesTCS Database QuestionsAmandeep Punia100% (1)
- ARM Instruction SetDocument75 pagesARM Instruction SetEragon ShadeSlayerNo ratings yet
- 02 - Data Processing InstructionsDocument42 pages02 - Data Processing InstructionsRiver AbodNo ratings yet
- MES Module 2Document13 pagesMES Module 2Radha Krishna - with youNo ratings yet
- 18CS44 Module2Document110 pages18CS44 Module2SharanKumarHuliNo ratings yet
- ARM Assembly Language Program ExamplesDocument18 pagesARM Assembly Language Program Examplessagar salankeNo ratings yet
- Lab 1 Using Visual Emulator: Download The Emulator Answer To Questions (Q)Document13 pagesLab 1 Using Visual Emulator: Download The Emulator Answer To Questions (Q)Alejandro Sanchez LopezNo ratings yet
- Q1 C Code: WhileDocument2 pagesQ1 C Code: WhileJyothi B.R.No ratings yet
- ARM Instruction SetDocument25 pagesARM Instruction SetShivam JainNo ratings yet
- MC Part A Programs-UpdatedDocument6 pagesMC Part A Programs-UpdatedM.A rajaNo ratings yet
- Mes Lab ProgramsDocument5 pagesMes Lab Programsnatty singhNo ratings yet
- Chapter 3: Arm Instruction Set: (Architecture Version: Armv4T)Document32 pagesChapter 3: Arm Instruction Set: (Architecture Version: Armv4T)sunilbhimuNo ratings yet
- Lec08 ARMisa 4upDocument24 pagesLec08 ARMisa 4upMuthu LinganNo ratings yet
- MCs Lab Programs - No ErrorsDocument15 pagesMCs Lab Programs - No Errorsgirishgoudapatil95No ratings yet
- All ARM ProgrammesDocument14 pagesAll ARM ProgrammesManu PrakashNo ratings yet
- Lecture 2 - ARM Instruction SetDocument42 pagesLecture 2 - ARM Instruction SetSuhaib AbugderaNo ratings yet
- 21bce2651 VL2023240505640 Ast05Document3 pages21bce2651 VL2023240505640 Ast05the.ayushomNo ratings yet
- Arm ExampleDocument4 pagesArm ExamplekamalNo ratings yet
- Mes Part-A Software ProgramsDocument9 pagesMes Part-A Software Programsrohtihr2611No ratings yet
- Microcontroller and Embedded Systems Laboratory Manual 18CSL48Document50 pagesMicrocontroller and Embedded Systems Laboratory Manual 18CSL48sarandevNo ratings yet
- Adobe Scan Aug 21, 2023Document11 pagesAdobe Scan Aug 21, 2023Kavana KnNo ratings yet
- AppendixD Assembly ArmDocument53 pagesAppendixD Assembly ArmBilelAmerNo ratings yet
- Topic 3 ARM Instruction Set Part - 1Document47 pagesTopic 3 ARM Instruction Set Part - 1Dev PatelNo ratings yet
- ARM Slides Part3Document33 pagesARM Slides Part3Asmitha G ee22b030No ratings yet
- MC ProgramsDocument4 pagesMC ProgramsVarun RavishankarNo ratings yet
- ARM Prog Model 3 ArithmeticDocument13 pagesARM Prog Model 3 ArithmeticArther TraverNo ratings yet
- Assignment 1 Model AnswersDocument5 pagesAssignment 1 Model Answers007wasrNo ratings yet
- Microcontroller Lab Software MANUALDocument17 pagesMicrocontroller Lab Software MANUALshivakeshichoupiriNo ratings yet
- Write A Program To Multiply Two 16 Bit Binary NumbersDocument10 pagesWrite A Program To Multiply Two 16 Bit Binary NumbersAkansha SinghNo ratings yet
- ALP-Embedded LabDocument5 pagesALP-Embedded LabRuthvik ThumuluriNo ratings yet
- ATtiny13, ATtiny2313, Instruction SetDocument19 pagesATtiny13, ATtiny2313, Instruction SetMihai PaunNo ratings yet
- 5 Arithmetic and Logic v21Document20 pages5 Arithmetic and Logic v21PARIS CHAUNo ratings yet
- MES Lab ManualDocument7 pagesMES Lab ManualTanisha RaniNo ratings yet
- Unit 2 ErtsDocument93 pagesUnit 2 ErtsShivanth LenkalapallyNo ratings yet
- Computer Organization Hamacher Instructor Manual Solution - Chapter 3Document46 pagesComputer Organization Hamacher Instructor Manual Solution - Chapter 3beryl29No ratings yet
- LECTURE 8 - ECE521 Instruction SETS - Branching N LoopingDocument49 pagesLECTURE 8 - ECE521 Instruction SETS - Branching N LoopingAmar MursyidNo ratings yet
- Cao Unit-3Document14 pagesCao Unit-3Hemanth ZNo ratings yet
- SNUVM2 Reference ManualDocument9 pagesSNUVM2 Reference ManualJeongho NahNo ratings yet
- 3.2 Arm Addressing Mode and Instruction SetDocument32 pages3.2 Arm Addressing Mode and Instruction Set727721eumt082No ratings yet
- Arm Processor (17EIL77) : Visvesvaraya Technological University BELAGAVI - 590 010Document33 pagesArm Processor (17EIL77) : Visvesvaraya Technological University BELAGAVI - 590 010Girmit GirmitNo ratings yet
- ARM Prog Model 2 AddressingDocument28 pagesARM Prog Model 2 AddressingSachin RajputNo ratings yet
- Arm Assembly CodesDocument20 pagesArm Assembly CodesROHIT CHANDRASHEKHAR KUPPELURNo ratings yet
- MPS Midterm SolutionDocument4 pagesMPS Midterm SolutionMuhammad AbubakarNo ratings yet
- Module 2 PDFDocument114 pagesModule 2 PDFPRADEEP KUMAR YNo ratings yet
- Arm Lpc2148codesfinallllDocument129 pagesArm Lpc2148codesfinallllAbhishek Pratap Rana0% (1)
- 3 Arithmetic and Logic v22Document20 pages3 Arithmetic and Logic v22vokhacnam2k1No ratings yet
- ARM 16thumb InstructionSet PDFDocument3 pagesARM 16thumb InstructionSet PDFGabriel Rivera MoralesNo ratings yet
- Introduction To The ARM Instruction Set:: 1 Module - 2 - FullDocument77 pagesIntroduction To The ARM Instruction Set:: 1 Module - 2 - Fullgagan.kulal619No ratings yet
- Programs ARMDocument5 pagesPrograms ARMspiya7609No ratings yet
- Microcontroller PracticeDocument3 pagesMicrocontroller Practicedeepika seranNo ratings yet
- Arm ProcessorDocument9 pagesArm ProcessorRahul AgarwalNo ratings yet
- 16 32 r0 RTN Program Counter or PC: CPE 221 Test 1 Solution Spring 2019Document4 pages16 32 r0 RTN Program Counter or PC: CPE 221 Test 1 Solution Spring 2019Kyra LathonNo ratings yet
- SET - ARM - InstDocument4 pagesSET - ARM - InstFernandoAdriánNo ratings yet
- ARM ReviewDocument10 pagesARM Review01fe19bec139No ratings yet
- ARM Prog Model 6 Subroutines PDFDocument34 pagesARM Prog Model 6 Subroutines PDFnaveenNo ratings yet
- Stm32AssemblyMiniCookbookV1 2Document18 pagesStm32AssemblyMiniCookbookV1 2warjazzmanNo ratings yet
- Instr Set PDFDocument150 pagesInstr Set PDFvannybowoooNo ratings yet
- ROUTING INFORMATION PROTOCOL: RIP DYNAMIC ROUTING LAB CONFIGURATIONFrom EverandROUTING INFORMATION PROTOCOL: RIP DYNAMIC ROUTING LAB CONFIGURATIONNo ratings yet
- Arm RtosDocument24 pagesArm RtosdhapraNo ratings yet
- Robert Bosch Sample PaperDocument9 pagesRobert Bosch Sample PaperdhapraNo ratings yet
- ThumbDocument32 pagesThumbdhapraNo ratings yet
- Elg4152 Modern Control Engineering Textbook Modern 59ce3e8c1723dd6dc1b864beDocument1 pageElg4152 Modern Control Engineering Textbook Modern 59ce3e8c1723dd6dc1b864bedhapraNo ratings yet
- Preferred CollegesDocument12 pagesPreferred CollegesdhapraNo ratings yet
- LIC Webinar1 Learning ResourcesDocument2 pagesLIC Webinar1 Learning ResourcesdhapraNo ratings yet
- WRF Hydro User Guide v3.0 CLEANDocument123 pagesWRF Hydro User Guide v3.0 CLEANisraelmpNo ratings yet
- BCS402 MC M2 NotesDocument21 pagesBCS402 MC M2 Notesmohammedsadiq4850No ratings yet
- Full Stack DevelopmentDocument1 pageFull Stack DevelopmentVigneshwaranNo ratings yet
- UGRD-CS6209 Software Engineering 1 FINAL EXAMDocument35 pagesUGRD-CS6209 Software Engineering 1 FINAL EXAMpatricia geminaNo ratings yet
- FullyDocument2,314 pagesFullyGopi StyzzNo ratings yet
- Data Contracts For Schema Registry - Confluent DocumentationDocument22 pagesData Contracts For Schema Registry - Confluent Documentationsahmed450No ratings yet
- HCL Question Paper: AptitudeDocument19 pagesHCL Question Paper: AptitudeVignesh WaranNo ratings yet
- Manual Checks - 2319491Document8 pagesManual Checks - 2319491F HASSANNo ratings yet
- C PROGRAMMING Interview QuestionsDocument10 pagesC PROGRAMMING Interview QuestionsGaurav GuptaNo ratings yet
- Concurrent Kernel in OpenCLDocument1 pageConcurrent Kernel in OpenCLsdancer75No ratings yet
- A Document Preparation System Latex: Ko-Hsuan ChenDocument20 pagesA Document Preparation System Latex: Ko-Hsuan ChenahzamshadabNo ratings yet
- CC 104 - Data Structures and Algorithms Final RequirementDocument3 pagesCC 104 - Data Structures and Algorithms Final RequirementMatthew John Sino CruzNo ratings yet
- Recursion ProblemsDocument7 pagesRecursion ProblemsZulqarnaynNo ratings yet
- Digital Logic Design Lab 02 ReportDocument12 pagesDigital Logic Design Lab 02 ReportUmer huzaifaNo ratings yet
- List of SQL CommandsDocument5 pagesList of SQL CommandsNeleRS100% (1)
- OOADDocument41 pagesOOADRobin80% (5)
- Web Tracker Integration GuideDocument12 pagesWeb Tracker Integration GuideEmmanuel Peña FloresNo ratings yet
- Python For Data Science, AI & Development - IBM - Course Info - CourseraDocument1 pagePython For Data Science, AI & Development - IBM - Course Info - CourseraMNo ratings yet
- Esp 30Document10 pagesEsp 30cjalanisNo ratings yet
- Architecture of MessagePackDocument26 pagesArchitecture of MessagePackMax ChiuNo ratings yet
- HOMM5 A2 Script FunctionsDocument109 pagesHOMM5 A2 Script FunctionsКостя БузенкоNo ratings yet
- CS2106 Laboratory 2: C Pointers and Memory ManagementDocument3 pagesCS2106 Laboratory 2: C Pointers and Memory ManagementweitsangNo ratings yet
- MATLAB CommandsDocument5 pagesMATLAB CommandsRaj Mehta100% (1)
- CMPG111: Leereenheid 2 / Study Unit 2Document34 pagesCMPG111: Leereenheid 2 / Study Unit 2Tshepo OscarNo ratings yet
- Yii2 by Example - Sample ChapterDocument59 pagesYii2 by Example - Sample ChapterPackt PublishingNo ratings yet
- File Watcher For Control-MDocument12 pagesFile Watcher For Control-MSaurabh TandonNo ratings yet
- NO.1 A. B. C. D. E.: AnswerDocument4 pagesNO.1 A. B. C. D. E.: AnswerGourab BanikNo ratings yet
- Principles of Programming Languages: Eliezer A. AlbaceaDocument68 pagesPrinciples of Programming Languages: Eliezer A. AlbaceaFebwin VillaceranNo ratings yet
- Spring Certification NotesDocument40 pagesSpring Certification Notesbabith100% (1)