
SVM-Based Fast CU Partition Decision Algorithm for VVC Intra Coding


Abstract
:1. Introduction
2. Related Works
2.1. Methods for HEVC
2.2. Methods for VVC
3. Proposed Algorithm
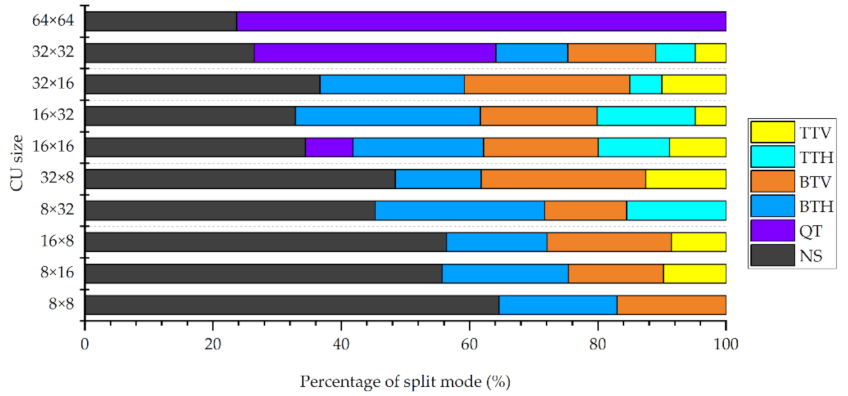
3.1. Statistical Analysis
- NS accounts for more than 20% of the partition mode in all CU sizes, and in 32 × 8, 8 × 32, 16 × 8, and 8 × 16 CUs, the proportion of NS is more than 40%. In addition, as the CU size decreases, the proportion of NS gradually increases. By predicting whether CU is partitioned early, VVC can skip the RDO process of QT and MTT partition, thereby reducing complexity.
- MTT split accounts for a relatively high proportion, especially for 32 × 16 and 16 × 32 CUs, which account for more than 60%, and the proportions of horizontal partition and vertical partition are almost the same. By predicting the direction of partition early, VVC can skip the MTT split in other directions, and reduce the cross calculation in the RDO process, thereby reducing coding complexity.
- The proportion of QT split is relatively low, the proportion of QT split in 16 × 16 CU does not exceed 10%. Therefore, the coding complexity that can be reduced by predicting QT split is limited, and unnecessary coding performance loss increases.
3.2. Fast CU Partition Decision Algorithm
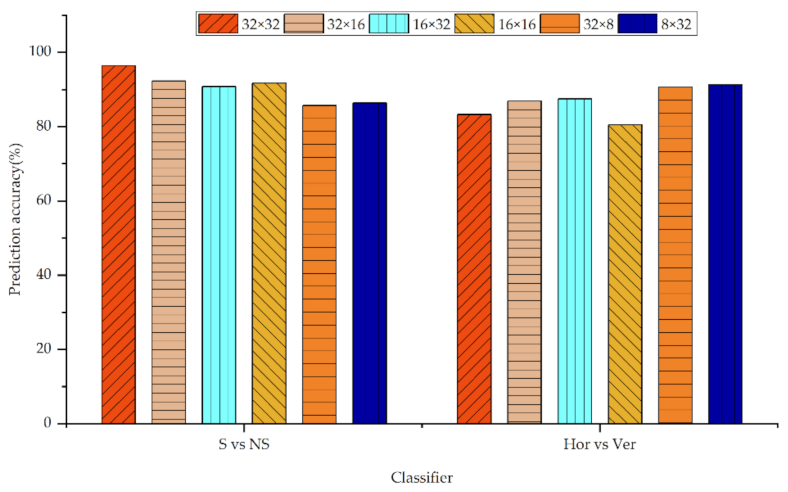
3.3. Feature Analysis and Selection
- 1.
- The SD reflects the texture complexity of CU by calculating the dispersion between the luminance values in the CU and the luminance mean. A large SD indicates that the CU has a complex texture and tends to be divided into smaller CUs, and a small SD indicates that the CU has a smooth texture and tends not to be divided. The SD is expressed as:where W and H represent the width and height of the CU, respectively, f (i, j) is the luminance value with coordinates (i, j) in CU. is the luminance mean of CU. is expressed as:
- 2.
- The EPR reflects the texture complexity of CU by calculating the proportion of edge points in the CU. A high EPR means that the CU has a complex texture. The most common method to extract edges is the Sobel edge detection algorithm. Firstly, the Sobel operators in the four directions are convolved with the luminance matrix of CU to obtain the gradient in each direction. The purpose of using four Sobel operators is to improve the accuracy of computing edges and anti-noise ability and to detect weak edge information accurately. The gradient is expressed as:where A is the luminance matrix of CU. Then, the absolute values of the gradients in four directions are added to obtain the edge matrix (EM). The expression of EM is:
- 3.
- The gradient ratio (GR) can represent the difference between the horizontal gradient and the vertical gradient of the CU. It is expressed as:
- 4.
- The Rq is the maximum difference between features of the sub-CUs divided by QT, and the features include the SD and the EPR, a large Rq indicates that CU tends to be divided. It is expressed as:where ftl, ftr, fbl, and fbr are the sub-CUs of top-left, top-right, bottom-left, and bottom-right, respectively.
- 5.
- The RdirB is the ratio of the difference of features in the horizontal and vertical directions in BT split, and the features include the SD and the EPR. It is expressed as:where ft and fb are the features of the top and bottom sub-CUs divided by BTH, fl and fr are the features of the left and right sub-CUs divided by BTV.
- 6.
- The RdirT is the ratio of the difference of features in the horizontal and vertical directions in TT split, and the features include the SD and the EPR. It is expressed as:where ftt, fmh, and fbt are the feature values of the sub-CUs divided by TTH split, flt, fmv, and frt are the feature values of the sub-CUs divided by TTV split. Since CU of size 32 × 8 cannot be TTH split and CU of size 8 × 32 cannot be TTV split, we substitute the difference of sub-CUs divided by BT.
3.4. The Principle of SVM Algorithm and Training
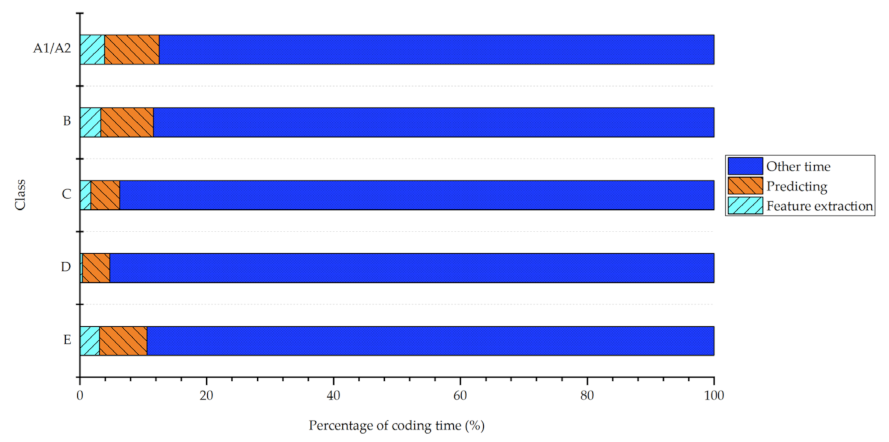
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bross, B.; Wang, Y.K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.R. Overview of the versatile video coding (VVC) standard and its applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.-R.; Han, W.-J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Versatile Video Coding Test Model (VTM) Reference Software of the JVET of ITU-T VCEG and ISO/IEC MPEG. Available online: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM (accessed on 13 June 2021).
- High Efficiency Video Coding Test Model (HM) Reference Software of the JCT-VC of ITU-T VCEG and ISO/IEC MPEG. Available online: https://hevc.hhi.fraunhofer.de/svn/svn_HEVCSoftware/ (accessed on 13 June 2021).
- Tissier, A.; Mercat, A.; Amestoy, T.; Hamidouche, W.; Vanne, J.; Menard, D. Complexity Reduction Opportunities in the Future VVC Intra Encoder. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Xu, M.; Tang, R.; Chen, Y.; Xing, Q. DeepQTMT: A Deep Learning Approach for Fast QTMT-Based CU Partition of Intra-Mode VVC. IEEE Trans. Image Process. 2021, 30, 5377–5390. [Google Scholar] [CrossRef] [PubMed]
- Chen, F.; Ren, Y.; Peng, Z.; Jiang, G.; Cui, X. A fast CU size decision algorithm for VVC intra prediction based on support vector machine. Multimed. Tools Appl. 2020, 79, 27923–27939. [Google Scholar] [CrossRef]
- Min, B.; Cheung, R.C.C. A Fast CU Size Decision Algorithm for the HEVC Intra Encoder. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 892–896. [Google Scholar] [CrossRef]
- Shen, L.; Zhang, Z.; Liu, Z. Effective CU Size Decision for HEVC Intracoding. IEEE Trans. Image Process. 2014, 23, 4232–4241. [Google Scholar] [CrossRef] [PubMed]
- Cho, S.; Kim, M. Fast CU Splitting and Pruning for Suboptimal CU Partitioning in HEVC Intra Coding. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1555–1564. [Google Scholar] [CrossRef]
- Zhang, M.; Lai, D.; Liu, Z.; An, C. A novel adaptive fast partition algorithm based on CU complexity analysis in HEVC. Multimed. Tools Appl. 2019, 78, 1035–1051. [Google Scholar] [CrossRef]
- Grellert, M.; Bampi, S.; Correa, G.; Zatt, B.; da Silva Cruz, L.A. Learning-Based Complexity Reduction and Scaling for HEVC Encoders. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1208–1212. [Google Scholar] [CrossRef]
- Correa, G.; Dall’Oglio, P.; Palomino, D.; Agostini, L. Fast Block Size Decision for HEVC Encoders with On-the-Fly Trained Classifiers. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021; pp. 540–544. [Google Scholar] [CrossRef]
- Sun, C.; Fan, X.; Zhao, D. A Fast Intra Cu Size Decision Algorithm Based on Canny Operator and SVM Classifier. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1787–1791. [Google Scholar] [CrossRef]
- Yin, J.; Yang, X.; Lin, J.; Chen, Y.; Fang, R. A Fast Block Partitioning Algorithm Based on SVM for HEVC Intra Coding. In Proceedings of the 2018 2nd International Conference on Video and Image Processing (ICVIP 2018), Hong Kong, China, 29–31 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 176–181. [Google Scholar] [CrossRef]
- Erabadda, B.; Mallikarachchi, T.; Kulupana, G.; Fernando, A. iCUS: Intelligent CU Size Selection for HEVC Inter Prediction. IEEE Access 2020, 8, 141143–141158. [Google Scholar] [CrossRef]
- Shen, X.; Yu, L. CU splitting early termination based on weighted SVM. EURASIP J. Image Video Process. 2013, 2013, 4. [Google Scholar] [CrossRef]
- Bouaafia, S.; Khemiri, R.; Sayadi, F.E.; Atri, M. Fast CU partition-based machine learning approach for reducing HEVC complexity. J. Real-Time Image Process. 2020, 17, 185–196. [Google Scholar] [CrossRef]
- Chen, Z.; Shi, J.; Li, W. Learned Fast HEVC Intra Coding. IEEE Trans. Image Process. 2020, 29, 5431–5446. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, Z.; Liu, P.; Jia, K.; Duan, K. HEVC Fast Intra Coding Based CTU Depth Range Prediction. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 551–555. [Google Scholar] [CrossRef]
- Xu, M.; Li, T.; Wang, Z.; Deng, X.; Yang, R.; Guan, Z. Reducing Complexity of HEVC: A Deep Learning Approach. IEEE Trans. Image Process. 2018, 27, 5044–5059. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, Y.; Chen, J.; Sun, H.; Katto, J.; Jing, M. A Fast QTMT Partition Decision Strategy for VVC Intra Prediction. IEEE Access 2020, 8, 107900–107911. [Google Scholar] [CrossRef]
- Park, S.-H.; Kang, J.-W. Context-Based Ternary Tree Decision Method in Versatile Video Coding for Fast Intra Coding. IEEE Access 2019, 7, 172597–172605. [Google Scholar] [CrossRef]
- Cui, J.; Zhang, T.; Gu, C.; Zhang, X.; Ma, S. Gradient-Based Early Termination of CU Partition in VVC Intra Coding. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; pp. 103–112. [Google Scholar] [CrossRef]
- Amestoy, T.; Mercat, A.; Hamidouche, W.; Menard, D.; Bergeron, C. Tunable VVC Frame Partitioning Based on Lightweight Machine Learning. IEEE Trans. Image Process. 2020, 29, 1313–1328. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Wang, Y.; Huang, L.; Jiang, B. Fast CU Partition and Intra Mode Decision Method for H.266/VVC. IEEE Access 2020, 8, 117539–117550. [Google Scholar] [CrossRef]
- Yang, H.; Shen, L.; Dong, X.; Ding, Q.; An, P.; Jiang, G. Low-Complexity CTU Partition Structure Decision and Fast Intra Mode Decision for Versatile Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1668–1682. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Zhang, J.; Wang, S.; Ma, S. Effective Quadtree Plus Binary Tree Block Partition Decision for Future Video Coding. In Proceedings of the 2017 Data Compression Conference (DCC), Snowbird, UT, USA, 4–7 April 2017; pp. 23–32. [Google Scholar] [CrossRef]
- Wu, G.; Huang, Y.; Zhu, C.; Song, L.; Zhang, W. SVM Based Fast CU Partitioning Algorithm for VVC Intra Coding. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, 22–28 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, Y.; Zhang, Q. Adaptive CU Split Decision Based on Deep Learning and Multifeature Fusion for H.266/VVC. Sci. Program. 2020, 2020, 8883214. [Google Scholar] [CrossRef]
- Tissier, A.; Hamidouche, W.; Vanne, J.; Galpin, F.; Menard, D. CNN Oriented Complexity Reduction of VVC Intra Encoder. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 3139–3143. [Google Scholar] [CrossRef]
- Park, S.-H.; Kang, J. Fast Multi-type Tree Partitioning for Versatile Video Coding Using a Lightweight Neural Network. IEEE Trans. Multimed. 2020, 23, 4388–4399. [Google Scholar] [CrossRef]
- Bossen, F.; Boyce, J.; Suehring, K.; Li, X.; Seregin, V. JVET common test conditions and software reference configurations for SDR video JVET-N1010-v1. In Proceedings of the 14th Meeting of the Joint Video Exploration Team (JVET), Geneva, Switzerland, 19–27 March 2019; pp. 1–6. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Test Sequence | Proposed (VTM7.0) | |
|---|---|---|---|
| BDBR (%) | TS (%) | ||
| A1 | Tango2 | 1.74 | 51.43 |
| FoodMarket4 | 1.24 | 47.32 | |
| Campfire | 1.37 | 56.37 | |
| A2 | CatRobot | 2.04 | 51.94 |
| DaylightRoad2 | 1.42 | 58.61 | |
| ParkRunning3 | 1.07 | 55.93 | |
| B | Kimono | 1.31 | 54.68 |
| ParkScene | 1.45 | 58.73 | |
| Cactus | 2.07 | 51.37 | |
| BasketballDrive | 1.76 | 53.34 | |
| BQTerrace | 1.23 | 55.37 | |
| C | BasketballDrill | 1.60 | 53.92 |
| PartyScene | 0.87 | 52.74 | |
| RaceHorsesC | 1.25 | 51.07 | |
| BQMall | 1.87 | 53.39 | |
| D | BasketballPass | 1.53 | 53.96 |
| BQSquare | 0.93 | 54.78 | |
| BlowingBubbles | 1.57 | 51.33 | |
| RaceHorses | 1.14 | 55.79 | |
| E | FourPeople | 2.19 | 55.21 |
| Johnny | 2.37 | 56.43 | |
| KristenAndSara | 1.88 | 55.46 | |
| Average | 1.54 | 54.05 | |
| Class | Test Sequence | Wu [29] (VTM10.0) | Zhao [30] (VTM7.0) | Fan [22] (VTM7.0) | Proposed (VTM7.0) | ||||
|---|---|---|---|---|---|---|---|---|---|
| BDBR (%) | TS (%) | BDBR (%) | TS (%) | BDBR (%) | TS (%) | BDBR (%) | TS (%) | ||
| B | BasketballDrive | 2.38 | 67.81 | - | - | 3.28 | 59.35 | 1.76 | 53.34 |
| Cactus | 2.78 | 66.61 | - | - | 1.84 | 52.44 | 2.07 | 51.37 | |
| Kimono | - | - | 0.78 | 37.51 | 1.93 | 59.51 | 1.31 | 54.68 | |
| ParkScene | - | - | 0.61 | 39.56 | 1.26 | 51.84 | 1.45 | 58.73 | |
| BQTerrace | 2.43 | 64.25 | 0.76 | 41.79 | 1.08 | 45.30 | 1.23 | 55.37 | |
| C | BasketballDrill | 5.39 | 65.29 | 1.25 | 39.21 | 1.82 | 48.48 | 1.60 | 53.92 |
| PartyScene | 1.40 | 58.77 | 0.37 | 36.73 | 0.26 | 38.62 | 0.87 | 52.74 | |
| RaceHorsesC | 2.00 | 62.10 | 0.24 | 30.68 | 0.88 | 49.05 | 1.25 | 51.07 | |
| D | BQSquare | 1.68 | 59.98 | 0.58 | 36.67 | 0.19 | 31.95 | 0.93 | 54.78 |
| BlowingBubbles | 2.24 | 59.94 | 0.83 | 40.87 | 0.47 | 40.35 | 1.57 | 51.33 | |
| RaceHorses | 1.69 | 58.98 | 0.56 | 36.51 | 0.54 | 41.69 | 1.14 | 55.79 | |
| E | FourPeople | 4.36 | 67.14 | 1.34 | 46.51 | 2.70 | 57.57 | 2.19 | 55.21 |
| Johnny | 4.34 | 67.01 | 1.56 | 43.78 | 3.22 | 56.88 | 2.37 | 56.43 | |
| KristenAndSara | 3.56 | 66.21 | 1.57 | 40.85 | 2.78 | 55.11 | 1.88 | 55.46 | |
| Average | 2.85 | 63.67 | 0.87 | 39.22 | 1.59 | 49.15 | 1.54 | 54.30 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Wu, A.; Zhang, Q. SVM-Based Fast CU Partition Decision Algorithm for VVC Intra Coding. Electronics 2022, 11, 2147. https://doi.org/10.3390/electronics11142147
Zhao J, Wu A, Zhang Q. SVM-Based Fast CU Partition Decision Algorithm for VVC Intra Coding. Electronics. 2022; 11(14):2147. https://doi.org/10.3390/electronics11142147
Chicago/Turabian StyleZhao, Jinchao, Aobo Wu, and Qiuwen Zhang. 2022. "SVM-Based Fast CU Partition Decision Algorithm for VVC Intra Coding" Electronics 11, no. 14: 2147. https://doi.org/10.3390/electronics11142147