
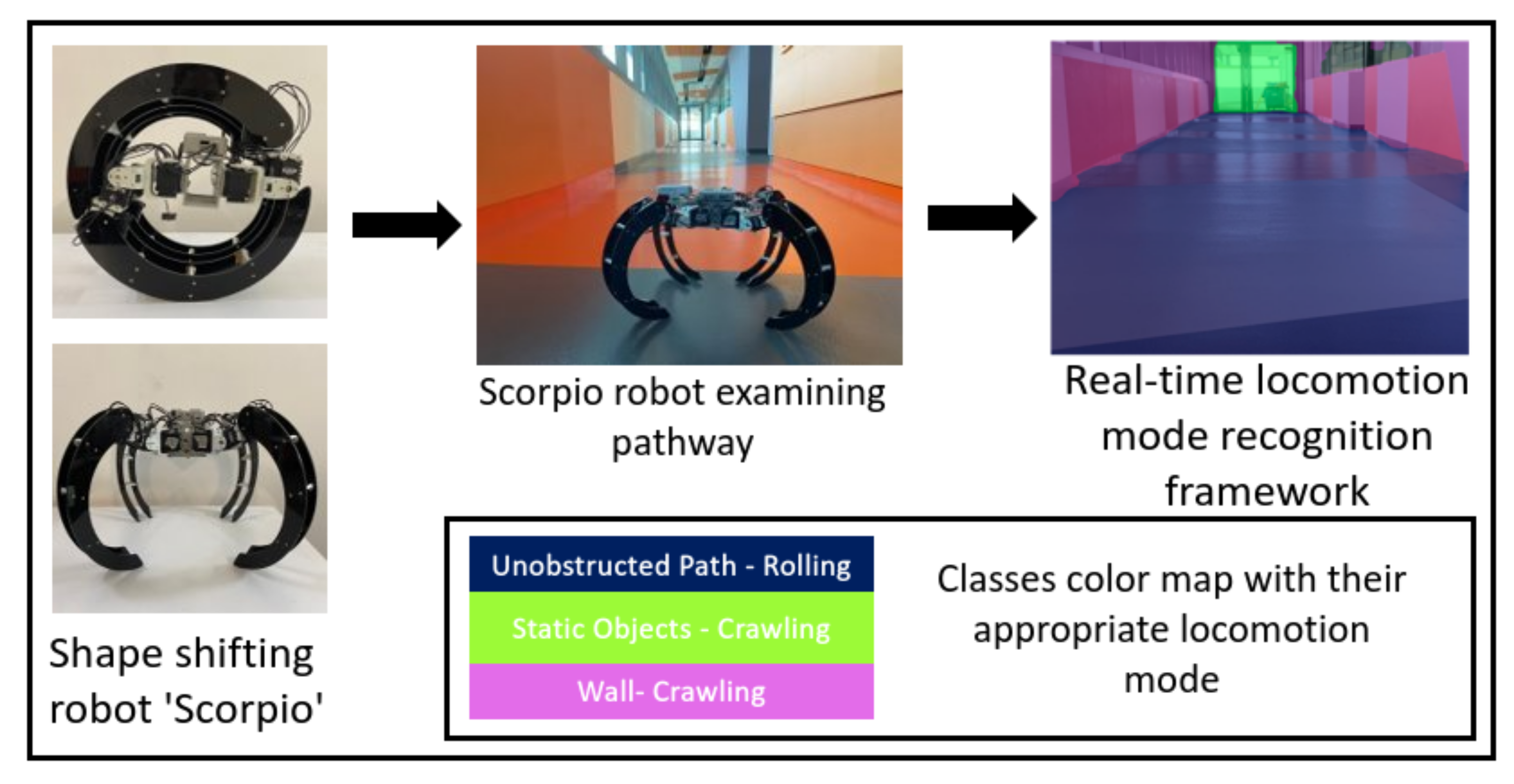
Object-of-Interest Perception in a Reconfigurable Rolling-Crawling Robot

 ,
,  , and
, and
Abstract
:1. Introduction
2. Related Work
3. Overview of the Proposed System
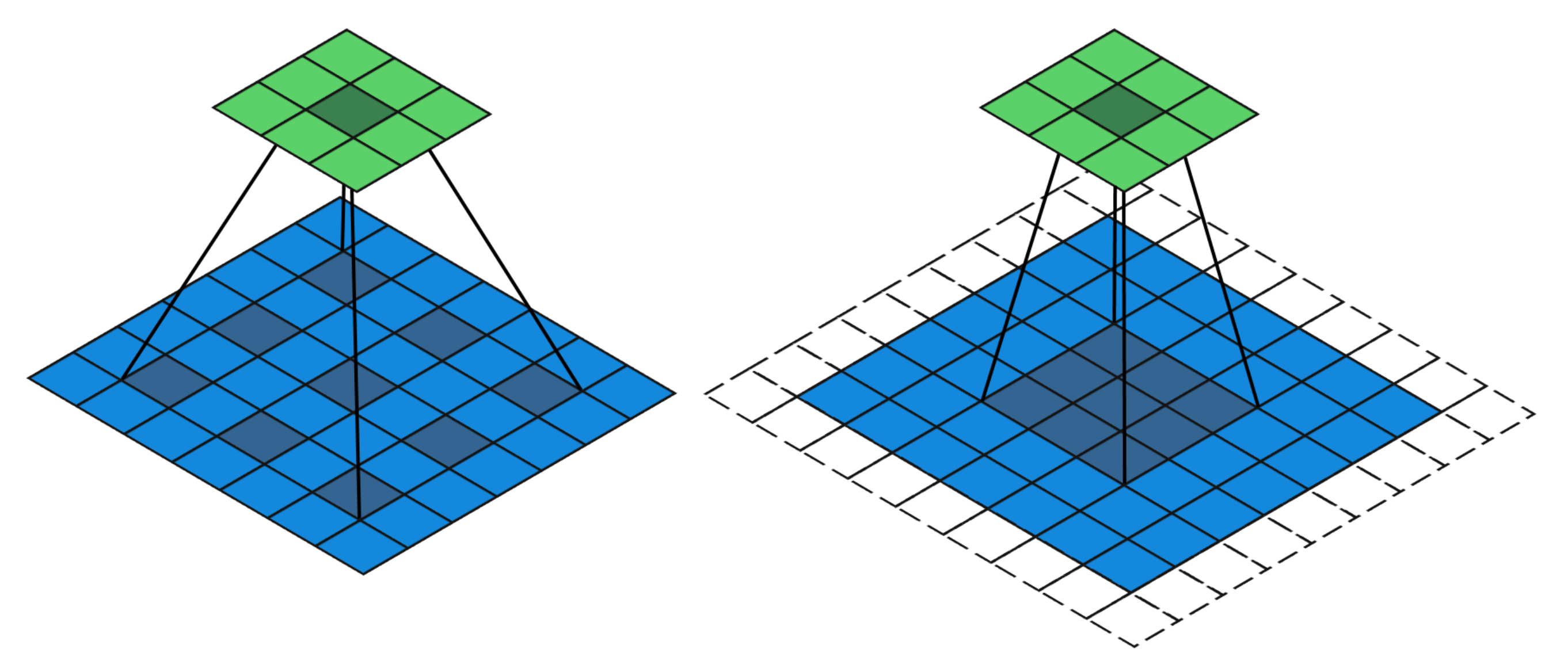
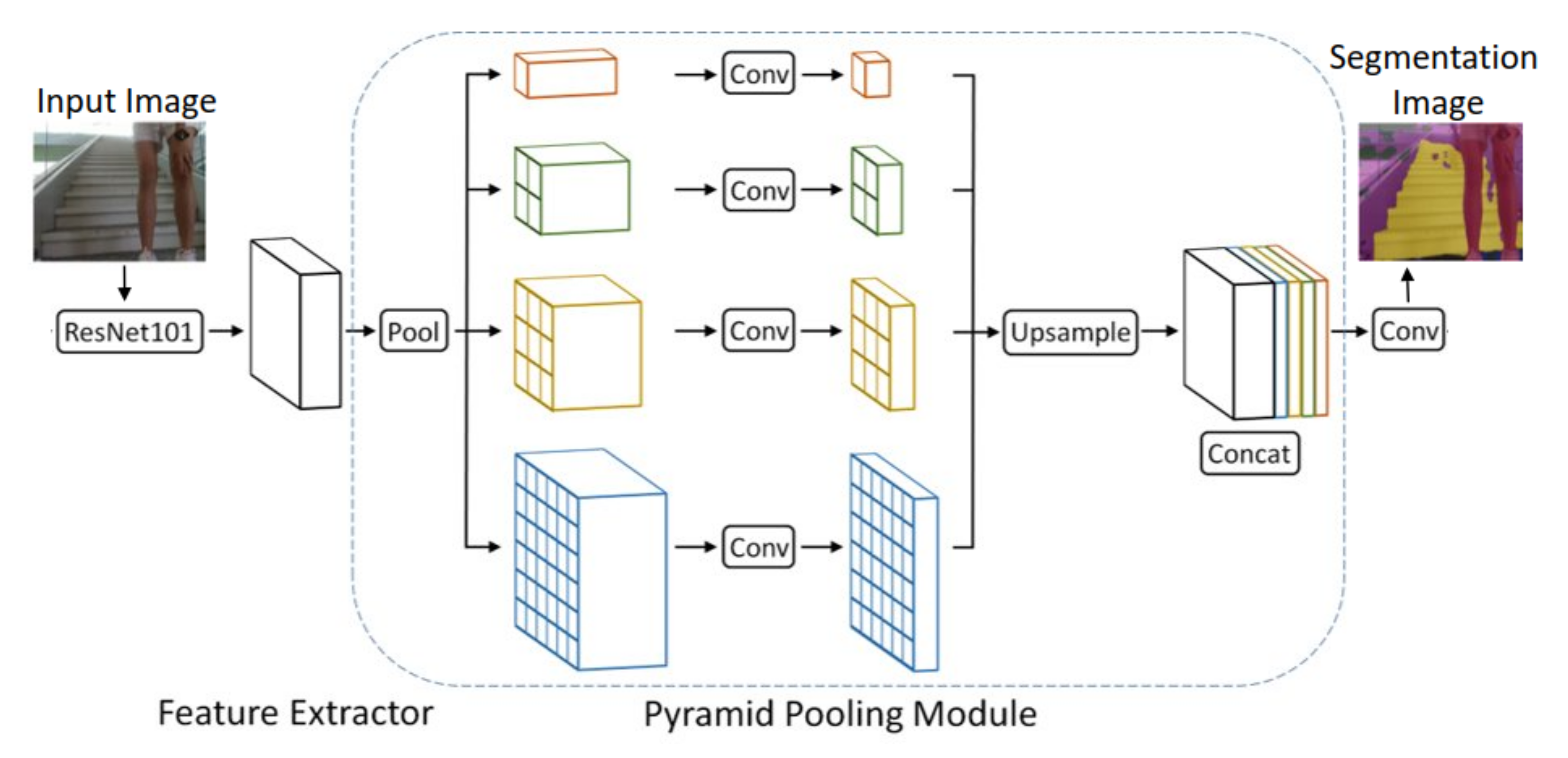
3.1. Semantic Segmentation Framework
3.2. Physical Layer
3.2.1. Locomotion Module
3.2.2. System Architecture
4. Experimental Setup & Results
4.1. Data-Set Preparation and Training
4.1.1. Training Hardware and Software Details
4.1.2. Evaluation Metrics
4.2. Offline Test
4.3. Real-Time Field Trial
4.3.1. Validation of Scorpio’s Performance
4.3.2. Real-Time Locomotion Mode Recognition Framework
5. Comparison and Validation
5.1. Comparison with Other Semantic Frameworks
5.2. Comparison with Other Existing Works
5.3. Validation in False-Ceiling Environment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hayat, A.A.; Elangovan, K.; Rajesh Elara, M.; Teja, M.S. Tarantula: Design, modeling, and kinematic identification of a quadruped wheeled robot. Appl. Sci. 2018, 9, 94. [Google Scholar] [CrossRef] [Green Version]
- Yi, L.; Anh Vu, L.; Hayat, A.; Borusu, C.; Mohan, R.E.; Nhan, N.; Kandasamy, P. Reconfiguration During Locomotion by Pavement Sweeping Robot With Feedback Control From Vision System. IEEE Access 2020, 8, 113355–113370. [Google Scholar] [CrossRef]
- Ilyas, M.; Yuyao, S.; Mohan, R.E.; Devarassu, M.; Kalimuthu, M. Design of sTetro: A modular, reconfigurable, and autonomous staircase cleaning robot. J. Sens. 2018, 2018, 8190802. [Google Scholar] [CrossRef]
- Vega-Heredia, M.; Mohan, R.E.; Wen, T.Y.; Siti’Aisyah, J.; Vengadesh, A.; Ghanta, S.; Vinu, S. Design and modelling of a modular window cleaning robot. Autom. Constr. 2019, 103, 268–278. [Google Scholar] [CrossRef]
- Jayaram, K.; Full, R.J. Cockroaches traverse crevices, crawl rapidly in confined spaces, and inspire a soft, legged robot. Proc. Natl. Acad. Sci. USA 2016, 113, E950–E957. [Google Scholar] [CrossRef] [Green Version]
- Peyer, K.E.; Zhang, L.; Nelson, B.J. Bio-inspired magnetic swimming microrobots for biomedical applications. Nanoscale 2013, 5, 1259–1272. [Google Scholar] [CrossRef]
- Shi, Z.; Pan, J.; Tian, J.; Huang, H.; Jiang, Y.; Zeng, S. An inchworm-inspired crawling robot. J. Bionic Eng. 2019, 16, 582–592. [Google Scholar] [CrossRef]
- Lin, H.T.; Leisk, G.G.; Trimmer, B. GoQBot: A caterpillar-inspired soft-bodied rolling robot. Bioinspir. Biomim. 2011, 6, 026007. [Google Scholar] [CrossRef]
- Jung, G.P.; Casarez, C.S.; Jung, S.P.; Fearing, R.S.; Cho, K.J. An integrated jumping-crawling robot using height-adjustable jumping module. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4680–4685. [Google Scholar]
- Ijspeert, A.J.; Crespi, A.; Ryczko, D.; Cabelguen, J.M. From swimming to walking with a salamander robot driven by a spinal cord model. Science 2007, 315, 1416–1420. [Google Scholar] [CrossRef] [Green Version]
- Tucker, M.R.; Olivier, J.; Pagel, A.; Bleuler, H.; Bouri, M.; Lambercy, O.; Millán, J.R.; Riener, R.; Vallery, H.; Gassert, R. Control strategies for active lower extremity prosthetics and orthotics: A review. J. Neuroeng. Rehabil. 2015, 12, 1. [Google Scholar] [CrossRef] [Green Version]
- Young, A.J.; Ferris, D.P. State of the art and future directions for lower limb robotic exoskeletons. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 171–182. [Google Scholar] [CrossRef] [PubMed]
- Ghoshal, R.; Roy, A.; Bhowmik, T.K.; Parui, S.K. Decision tree based recognition of Bangla text from outdoor scene images. In Proceedings of the International Conference on Neural Information Processing, Shanghai, China, 13–17 November 2011; pp. 538–546. [Google Scholar]
- Rokach, L.; Maimon, O. Decision trees. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005; pp. 165–192. [Google Scholar]
- Massalin, Y.; Abdrakhmanova, M.; Varol, H.A. User-independent intent recognition for lower limb prostheses using depth sensing. IEEE Trans. Biomed. Eng. 2017, 65, 1759–1770. [Google Scholar] [PubMed]
- Varol, H.A.; Massalin, Y. A feasibility study of depth image based intent recognition for lower limb prostheses. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 5055–5058. [Google Scholar]
- Krausz, N.E.; Hargrove, L.J. Recognition of ascending stairs from 2D images for control of powered lower limb prostheses. In Proceedings of the 2015 7th International IEEE/EMBS Conference on Neural Engineering (NER), Montpellier, France, 22–24 April 2015; pp. 615–618. [Google Scholar]
- Khademi, G.; Simon, D. Convolutional neural networks for environmentally aware locomotion mode recognition of lower-limb amputees. In Proceedings of the Dynamic Systems and Control Conference. American Society of Mechanical Engineers, Park City, UT, USA, 8–11 October 2019; Volume 59148, p. V001T07A005. [Google Scholar]
- Laschowski, B.; McNally, W.; Wong, A.; McPhee, J. Preliminary design of an environment recognition system for controlling robotic lower-limb prostheses and exoskeletons. In Proceedings of the 2019 IEEE 16th international conference on rehabilitation robotics (ICORR), Toronto, ON, Canada, 24–28 June 2019; pp. 868–873. [Google Scholar]
- Novo-Torres, L.; Ramirez-Paredes, J.P.; Villarreal, D.J. Obstacle recognition using computer vision and convolutional neural networks for powered prosthetic leg applications. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 3360–3363. [Google Scholar]
- Sharkawy, A.N. Principle of neural network and its main types. J. Adv. Appl. Comput. Math. 2020, 7, 8–19. [Google Scholar] [CrossRef]
- Suryamurthy, V.; Raghavan, V.S.; Laurenzi, A.; Tsagarakis, N.G.; Kanoulas, D. Terrain Segmentation and Roughness Estimation using RGB Data: Path Planning Application on the CENTAURO Robot. In Proceedings of the 2019 IEEE-RAS 19th International Conference on Humanoid Robots (Humanoids), Toronto, ON, Canada, 15–17 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Aslan, S.N.; Uçar, A.; Güzeliş, C. Development of Deep Learning Algorithm for Humanoid Robots to Walk to the Target Using Semantic Segmentation and Deep Q Network. In Proceedings of the 2020 Innovations in Intelligent Systems and Applications Conference (ASYU), Istanbul, Turkey, 15–17 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Doan, V.V.; Nguyen, D.H.; Tran, Q.L.; Nguyen, D.V.; Le, T.H. Real-time Image Semantic Segmentation Networks with Residual Depth-wise Separable Blocks. In Proceedings of the 2018 Joint 10th International Conference on Soft Computing and Intelligent Systems (SCIS) and 19th International Symposium on Advanced Intelligent Systems (ISIS), Toyama, Japan, 5–8 December 2018; pp. 174–179. [Google Scholar]
- Kowalewski, S.; Maurin, A.L.; Andersen, J.C. Semantic mapping and object detection for indoor mobile robots. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Wuhan, China, 10–12 October 2019; Volume 517, p. 012012. [Google Scholar]
- Bersan, D.; Martins, R.; Campos, M.; Nascimento, E.R. Semantic Map Augmentation for Robot Navigation: A Learning Approach Based on Visual and Depth Data. In Proceedings of the 2018 Latin American Robotic Symposium, 2018 Brazilian Symposium on Robotics (SBR) and 2018 Workshop on Robotics in Education (WRE), João Pessoa, Brazil, 6–10 November 2018. [Google Scholar] [CrossRef]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. Blitznet: A real-time deep network for scene understanding. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4154–4162. [Google Scholar]
- Ganyu, D.; Jianwen, L.; Caiming, S.; Dongwei, P.; Longyao, P.; Ning, D.; Aidong, Z. Vision-based Navigation for a Small-scale Quadruped Robot Pegasus-Mini. arXiv 2021, arXiv:2110.04426. [Google Scholar]
- Belter, D.; Wietrzykowski, J.; Skrzypczyński, P. Employing natural terrain semantics in motion planning for a multi-legged robot. J. Intell. Robot. Syst. 2019, 93, 723–743. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yanagida, T.; Elara Mohan, R.; Pathmakumar, T.; Elangovan, K.; Iwase, M. Design and implementation of a shape shifting rolling–crawling–wall-climbing robot. Appl. Sci. 2017, 7, 342. [Google Scholar] [CrossRef] [Green Version]
- Powerful and Efficient Computer Vision Annotation Tool (CVAT). Available online: https://github.com/openvinotoolkit/cvat (accessed on 11 April 2022).
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sens. 2020, 13, 71. [Google Scholar] [CrossRef]
- Rafique, A.A.; Jalal, A.; Kim, K. Statistical multi-objects segmentation for indoor/outdoor scene detection and classification via depth images. In Proceedings of the 2020 17th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 14–18 January 2020; pp. 271–276. [Google Scholar]
- López-Cifuentes, A.; Escudero-Viñolo, M.; Bescós, J.; García-Martín, Á. Semantic-aware scene recognition. Pattern Recognit. 2020, 102, 107256. [Google Scholar] [CrossRef] [Green Version]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor semantic segmentation using depth information. arXiv 2013, arXiv:1301.3572. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Specification |
|---|---|
| Dimension (Crawling) | 46 cm × 46 cm × 27 cm |
| Dimension (Rolling) | 29.5 cm diameter |
| Weight (including battery) | 1.3 kg |
| Full Body Material | Acrylic |
| Smart Actuators | Dynamixel AX-12A (12 no’s) |
| Working Voltage | 7.4 V |
| Maximum Obstacle Height | 0.3 cm |
| Operational Duration | 45 min |
| Battery | 11.1 V |
| Camera | Realsense D435i |
| Augmentation Type | Augmentation Setting |
|---|---|
| Scaling | 0.5× to 1.5× |
| Rotation | from −45 degree to +45 degree |
| Horizontal flip | flip the image horizontally |
| Color enhancing | contrast (from 0.5× to 1.5×) |
| Blurring | Gaussian Blur (from sigma 1.0× to 3.0×) |
| Brightness | from 0.5× to 1.5× |
| Shear | x axis (−30 to 30) y aixs (−30 to 30) |
| Cutout | 1 to 3 squares up to 35% of pixel size |
| Mosaic | random crop and combination of 4 images |
| Category | Class | Pixel Accuracy | IoU | mIoU |
|---|---|---|---|---|
| Unobstructed Path (Rolling) | Floor | 92.5 | 86.2 | |
| Person | 93.4 | 89.6 | ||
| Railing | 82.9 | 64.5 | 72.28 | |
| Obstructed Path (Crawling) | Stairs | 88.6 | 71.3 | |
| Static object | 83.6 | 62.8 | ||
| Walls | 83.1 | 59.3 |
| Category | Class | Pixel Accuracy (%) | IoU | mIOU |
|---|---|---|---|---|
| Unobstructed Path (Rolling) | Floor | 91.9 | 84.6 | |
| Person | 92.5 | 87.6 | ||
| Railing | 82.2 | 62.6 | 70.63 | |
| Obstructed Path (Crawling) | Stairs | 87.8 | 70.1 | |
| Static object | 82.9 | 61.1 | ||
| Walls | 81.8 | 57.8 |
| Semantic Framework | Pixel Accuracy (%) | mIOU | Speed (ms) |
|---|---|---|---|
| PSPNet (Proposed framework) | 87.35 | 72.28 | 96.59 |
| HRNet | 78.1 | 64.17 | 158.59 |
| Deeplabv3 | 84.5 | 69.89 | 98.53 |
| Case Studies | Classification Type | Algorithm | Classes | mIOU |
|---|---|---|---|---|
| Rafique et al. [36] | Offline | Linear SVM | 11 | 72.2 |
| Lopez et al. [37] | Offline | Two-branched CNN and Attention Module | 61 | 74.04 |
| Couprie et al. [38] | Offline | Multiscale Convolutional Network | 14 | 52.4 |
| Proposed framework | Real-time with Scorpio | PSPNet | 6 | 70.63 |
| Category | Class | Pixel Accuracy (%) | IoU | mIOU |
|---|---|---|---|---|
| Unobstructed Path (Rolling) | Floor | 89.2 | 83.2 | |
| Rails | 88.5 | 79.3 | 67.36 | |
| Walls | 81.1 | 60.1 | ||
| Obstructed Path (Crawling) | Wires | 85.2 | 55.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Semwal, A.; Lee, M.M.J.; Sanchez, D.; Teo, S.L.; Wang, B.; Mohan, R.E. Object-of-Interest Perception in a Reconfigurable Rolling-Crawling Robot. Sensors 2022, 22, 5214. https://doi.org/10.3390/s22145214
Semwal A, Lee MMJ, Sanchez D, Teo SL, Wang B, Mohan RE. Object-of-Interest Perception in a Reconfigurable Rolling-Crawling Robot. Sensors. 2022; 22(14):5214. https://doi.org/10.3390/s22145214
Chicago/Turabian StyleSemwal, Archana, Melvin Ming Jun Lee, Daniela Sanchez, Sui Leng Teo, Bo Wang, and Rajesh Elara Mohan. 2022. "Object-of-Interest Perception in a Reconfigurable Rolling-Crawling Robot" Sensors 22, no. 14: 5214. https://doi.org/10.3390/s22145214