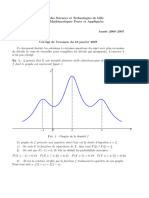
Correction TD4
Correction TD4
Télécharger au format pdf ou txt
Vous aimerez peut-être aussi
- 6ème DMn° AngeDocument1 page6ème DMn° AngejulienguiennePas encore d'évaluation
- Proba Va2Document17 pagesProba Va2Mohammed EL KHATTABIPas encore d'évaluation
- TP #1 CaloriemetriéDocument6 pagesTP #1 CaloriemetriéQudýmãt Áhmèd88% (17)
- Inégalité de TchebychevDocument4 pagesInégalité de TchebychevKarimaPas encore d'évaluation
- Examen TEI Janvier 2024 CorrectionDocument5 pagesExamen TEI Janvier 2024 CorrectionChahlaoui AzizPas encore d'évaluation
- Exos Probas Agreg14Document5 pagesExos Probas Agreg14ozelhesaptirbuPas encore d'évaluation
- Fiche Proba Loois UsuellesDocument2 pagesFiche Proba Loois UsuellesspartanarthemisPas encore d'évaluation
- Exercices de Révision Proba 22 23Document13 pagesExercices de Révision Proba 22 23Hadyle MeraouanePas encore d'évaluation
- Chapitre 1Document10 pagesChapitre 1ヤス ミンPas encore d'évaluation
- TD Proba-Stat Tronc Commun Polytech ClermontDocument2 pagesTD Proba-Stat Tronc Commun Polytech Clermonthamza dahbiPas encore d'évaluation
- Chap 1Document88 pagesChap 1Mohamed DramePas encore d'évaluation
- 09 Lois - SuiteDocument36 pages09 Lois - Suitejoe celainPas encore d'évaluation
- Chap Stat 3Document49 pagesChap Stat 3Amira GhazouaniPas encore d'évaluation
- ProbabilitéDocument7 pagesProbabilitéGuez YoPas encore d'évaluation
- Proba5 PDFDocument8 pagesProba5 PDFjrachek21490% (1)
- Correction TD 4Document2 pagesCorrection TD 4hani bouafiaPas encore d'évaluation
- Corrigé Partiel2018Document4 pagesCorrigé Partiel2018Fleur De LysPas encore d'évaluation
- Serie Proba 2Document2 pagesSerie Proba 2israalaya167Pas encore d'évaluation
- TD13densites UsuellesDocument2 pagesTD13densites UsuellesAntonio EscobarPas encore d'évaluation
- Estimation Ponctuelle Et Par Intervalle de Confiance: Feuille de TP N 6Document5 pagesEstimation Ponctuelle Et Par Intervalle de Confiance: Feuille de TP N 6Abdelhamid JenzriPas encore d'évaluation
- Rappel ProbabilitéDocument6 pagesRappel ProbabilitéBlgPas encore d'évaluation
- Variables AléatoiresDocument7 pagesVariables Aléatoirespauline gonzálezPas encore d'évaluation
- dm1 CorrDocument4 pagesdm1 CorrFatima GORINEPas encore d'évaluation
- Chap 2 2021Document13 pagesChap 2 2021ms hadjerPas encore d'évaluation
- TD Godichon-Baggioni L3Document24 pagesTD Godichon-Baggioni L3mathurinkopelgaPas encore d'évaluation
- Example CorrectionDocument4 pagesExample CorrectionzaynPas encore d'évaluation
- Resumé Ect2Document28 pagesResumé Ect2Abdelhak ElBakkaliPas encore d'évaluation
- Probabilité Loi UniformeDocument9 pagesProbabilité Loi UniformesirinePas encore d'évaluation
- T3 Exos CorrDocument10 pagesT3 Exos CorrJonathan AmatuPas encore d'évaluation
- Corr LU1MA002CC1 ScFo DC PeiP EAD 2023Document6 pagesCorr LU1MA002CC1 ScFo DC PeiP EAD 2023Wiem SmidaPas encore d'évaluation
- Math F 105séance11corrDocument4 pagesMath F 105séance11corrsoulaimane lafhalPas encore d'évaluation
- TD 09Document2 pagesTD 09poulnareffjeanPas encore d'évaluation
- Theoreme Central LimiteDocument3 pagesTheoreme Central LimiteAkpo ArmandPas encore d'évaluation
- l2 Examen Juin 2012 v1Document4 pagesl2 Examen Juin 2012 v1imranePas encore d'évaluation
- Statistiques - 4 IF: TD 2: Test D'hypoth' Ese Sur Un Param' EtreDocument2 pagesStatistiques - 4 IF: TD 2: Test D'hypoth' Ese Sur Un Param' EtreDaniel NguyễnPas encore d'évaluation
- ResumeVAetLois 10Document1 pageResumeVAetLois 10Wadii SGPas encore d'évaluation
- Cours Statistiques InfDocument18 pagesCours Statistiques InfDimokrati HoussamPas encore d'évaluation
- Exercice N°2Document7 pagesExercice N°2EYA MHIRPas encore d'évaluation
- Solution STAT INFDocument6 pagesSolution STAT INFSalma SabwatPas encore d'évaluation
- Chap Stat 1Document63 pagesChap Stat 1Amira GhazouaniPas encore d'évaluation
- Chap Stat 3Document56 pagesChap Stat 3Ibidhi SanaPas encore d'évaluation
- Exos (6 16) TD 4Document9 pagesExos (6 16) TD 4mathurinkopelgaPas encore d'évaluation
- Exercices ConvergenceDocument2 pagesExercices ConvergencerakotonantenainanPas encore d'évaluation
- td12 DensiteDocument2 pagestd12 Densiteulrichtheyi1Pas encore d'évaluation
- TD5 2014Document2 pagesTD5 2014rokiahoumedsalehPas encore d'évaluation
- Chapitre4 2022Document26 pagesChapitre4 2022Dieng MamdiaraPas encore d'évaluation
- Correction TD2Document18 pagesCorrection TD2mathurinkopelgaPas encore d'évaluation
- ProbaDocument6 pagesProbaAmal BãPas encore d'évaluation
- Module de Statistique Inferentielle PDF 1Document120 pagesModule de Statistique Inferentielle PDF 1Olsaint TenelusPas encore d'évaluation
- Mathf 207 Seance 4Document2 pagesMathf 207 Seance 4soulaimane lafhalPas encore d'évaluation
- Mathf 207 Seance 3Document3 pagesMathf 207 Seance 3soulaimane lafhalPas encore d'évaluation
- ECT2-Cours Chapitre 5Document12 pagesECT2-Cours Chapitre 5Charles PeterPas encore d'évaluation
- Lois PmsDocument25 pagesLois Pmssimao_sabrosa7794Pas encore d'évaluation
- 14-Estimation PartDocument13 pages14-Estimation PartPierre PochetPas encore d'évaluation
- Mathf 207 Seance 5Document2 pagesMathf 207 Seance 5soulaimane lafhalPas encore d'évaluation
- ProbabilitésDocument23 pagesProbabilitésamalaitmanssour23Pas encore d'évaluation
- Exercice N°1Document10 pagesExercice N°1EYA MHIRPas encore d'évaluation
- Math F 105séance11Document2 pagesMath F 105séance11soulaimane lafhalPas encore d'évaluation
- Chap 5Document11 pagesChap 5warriormind001Pas encore d'évaluation
- Proba Chap 4Document17 pagesProba Chap 4Abdelghani AninichPas encore d'évaluation
- Statistique InductifDocument8 pagesStatistique Inductifmariama doucourePas encore d'évaluation
- Correction TD4Document5 pagesCorrection TD4CHAIMAE AFIFPas encore d'évaluation
- G Casa Anfa Com1Document23 pagesG Casa Anfa Com1hamza dahbiPas encore d'évaluation
- PRO POS Materialqualitaeten INDocument1 pagePRO POS Materialqualitaeten INhamza dahbi100% (1)
- DZ 1 QG BMC3 CDocument1 pageDZ 1 QG BMC3 Chamza dahbiPas encore d'évaluation
- Abes - Prod.pw Mtc.b360.f14822.ebsu006Document6 pagesAbes - Prod.pw Mtc.b360.f14822.ebsu006hamza dahbiPas encore d'évaluation
- Prof Ens M2 IrarchDocument3 pagesProf Ens M2 Irarchhamza dahbiPas encore d'évaluation
- Projet No. R.075573.001 Platelage en AcierDocument4 pagesProjet No. R.075573.001 Platelage en Acierhamza dahbiPas encore d'évaluation
- PP AbaqusDocument4 pagesPP Abaqushamza dahbiPas encore d'évaluation
- Fiche Spécialité INSA GCBDocument2 pagesFiche Spécialité INSA GCBhamza dahbiPas encore d'évaluation
- DAC List ODA Recipients2018to2020 Flows FRDocument1 pageDAC List ODA Recipients2018to2020 Flows FRhamza dahbiPas encore d'évaluation
- Longueur D - Ancrage Des ArmaturesDocument2 pagesLongueur D - Ancrage Des Armatureshamza dahbiPas encore d'évaluation
- TD3 2019Document5 pagesTD3 2019hamza dahbi100% (1)
- Cours Chapitre 3 Interpolation PolynomialeDocument5 pagesCours Chapitre 3 Interpolation Polynomialehamza dahbiPas encore d'évaluation
- A-Prestations Accordees Au Maroc: Pour Les Véhicules de Plus de 10 Ans Avec Franchise KilométriqueDocument1 pageA-Prestations Accordees Au Maroc: Pour Les Véhicules de Plus de 10 Ans Avec Franchise Kilométriquehamza dahbiPas encore d'évaluation
- Ingénierie InformatiqueDocument1 pageIngénierie Informatiquehamza dahbiPas encore d'évaluation
- TD 7Document2 pagesTD 7hamza dahbiPas encore d'évaluation
- TD4 Obligatoirexo SyntheseDocument2 pagesTD4 Obligatoirexo Synthesehamza dahbiPas encore d'évaluation
- Oiseau BuveurDocument12 pagesOiseau BuveurhierinfomationPas encore d'évaluation
- Onduleur EastDocument3 pagesOnduleur EastPICO MEGA SENEGALPas encore d'évaluation
- Cours - Méthodologie de La Préparation Du Mémoire PDFDocument20 pagesCours - Méthodologie de La Préparation Du Mémoire PDFTaha Can100% (2)
- Copie de Copie de Exercices Regression Lineaire SimpleDocument13 pagesCopie de Copie de Exercices Regression Lineaire SimpleMaryem MaryPas encore d'évaluation
- Statistique Descriptive - SMCS4 - Chap IDocument45 pagesStatistique Descriptive - SMCS4 - Chap Ihakimfanhoubi6Pas encore d'évaluation
- Specialite Genie Climatique Et EnergetiqDocument50 pagesSpecialite Genie Climatique Et Energetiqchouaib kennichePas encore d'évaluation
- Introduction À La DynamiqueDocument7 pagesIntroduction À La Dynamiqueprosnick.bakembaPas encore d'évaluation
- Validation Des Méthodes Analytique Selon La Norme Française NF T90-210 - Mohamed AMZADDocument65 pagesValidation Des Méthodes Analytique Selon La Norme Française NF T90-210 - Mohamed AMZADhamza miskPas encore d'évaluation
- Chapitre 2Document64 pagesChapitre 2Adam BihiPas encore d'évaluation
- Devoir de Synthèse N°2 2012 2013 (Trabelsi) (Taib Mhiri Sfaxi)Document6 pagesDevoir de Synthèse N°2 2012 2013 (Trabelsi) (Taib Mhiri Sfaxi)Fatma ZghabPas encore d'évaluation
- Cor Ass Non Vie TD3Document3 pagesCor Ass Non Vie TD3mdmraberhnhPas encore d'évaluation
- Cours Maths Fi 3Document4 pagesCours Maths Fi 3Aksel MedlalPas encore d'évaluation
- Depliant Master Modelisation Hybride Avancee Calcul Scientifique 165x325mm VFDocument2 pagesDepliant Master Modelisation Hybride Avancee Calcul Scientifique 165x325mm VFMohamed MoudinePas encore d'évaluation
- Exo Nat - SE & SGC - Suites NumeriquesDocument5 pagesExo Nat - SE & SGC - Suites Numeriques3ONSORY FFPas encore d'évaluation
- Tampons de JaugeDocument1 pageTampons de JaugemechkourPas encore d'évaluation
- ECR3035EDocument2 pagesECR3035EFari AliPas encore d'évaluation
- TD Complet Reseau2 Schema 1617Document41 pagesTD Complet Reseau2 Schema 1617lara2005100% (1)
- AU CTC: Avis Technique 2/2016-14Document26 pagesAU CTC: Avis Technique 2/2016-14amelPas encore d'évaluation
- Mécanique 2 - Préparation Aux Exams 1 (1)Document6 pagesMécanique 2 - Préparation Aux Exams 1 (1)hiddanerim16Pas encore d'évaluation
- TD-1-analyse Des RéseauxDocument2 pagesTD-1-analyse Des RéseauxFatiha LAOUFIPas encore d'évaluation
- AnnalesExamensTI EES 4ADocument29 pagesAnnalesExamensTI EES 4AMymy SuityPas encore d'évaluation
- Serie p3 1ere s1 Ltye 2017 2018Document2 pagesSerie p3 1ere s1 Ltye 2017 2018senebassirou693Pas encore d'évaluation
- Devoir Maison 1 SC MathDocument4 pagesDevoir Maison 1 SC MathNaim BeethoPas encore d'évaluation
- RA02-champ LibreDocument54 pagesRA02-champ LibreLarbi BTPas encore d'évaluation
- Outils Mathematiques SIIDocument10 pagesOutils Mathematiques SIIAbdelali YacoubiPas encore d'évaluation
- Goniometrie ArticulaireDocument5 pagesGoniometrie ArticulairemadjibeybPas encore d'évaluation
- Tp-ENZYMO 1578422272Document7 pagesTp-ENZYMO 1578422272liliPas encore d'évaluation
- M204 Controleurs 2020 2021Document114 pagesM204 Controleurs 2020 2021Azzeddine EL-OhnPas encore d'évaluation