 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
CoMMIT: Coordinated Instruction Tuning for Multimodal Large Language Models
Jul 29, 2024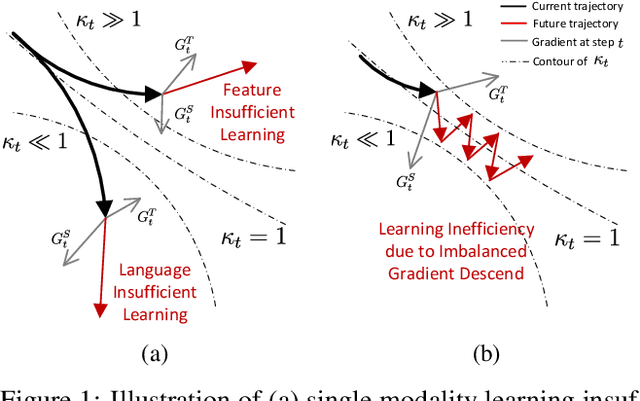
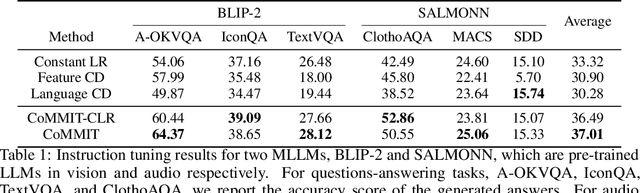
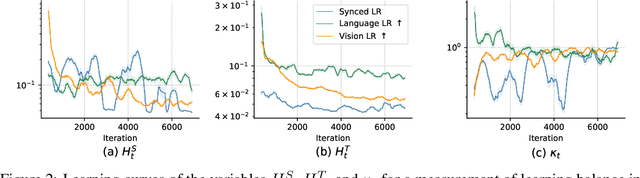
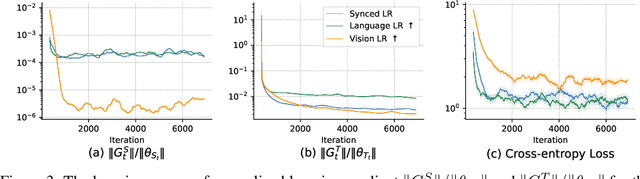
Instruction tuning in multimodal large language models (MLLMs) aims to smoothly integrate a backbone LLM with a pre-trained feature encoder for downstream tasks. The major challenge is how to efficiently find the synergy through cooperative learning where LLMs adapt their reasoning abilities in downstream tasks while feature encoders adjust their encoding to provide more relevant modal information. In this paper, we analyze the MLLM instruction tuning from both theoretical and empirical perspectives, where we find unbalanced learning between the two components, i.e., the feature encoder and the LLM, can cause diminishing learning gradients that slow the model convergence and often lead to sub-optimal results due to insufficient learning. Inspired by our findings, we propose a measurement to quantitatively evaluate the learning balance, based on which we further design a dynamic learning scheduler that better coordinates the learning. In addition, we introduce an auxiliary loss regularization method to promote updating of the generation distribution of MLLMs considering the learning state of each model component, which potentially prevents each component from gradient diminishing and enables a more accurate estimation of the learning balance coefficient. We conduct experiments with multiple LLM backbones and feature encoders, where our techniques are model-agnostic and can be generically integrated with various MLLM backbones. Experiment results on multiple downstream tasks and modalities in vision and audio, demonstrate the proposed method's better efficiency and effectiveness in MLLM instruction tuning.
OfficeBench: Benchmarking Language Agents across Multiple Applications for Office Automation
Jul 26, 2024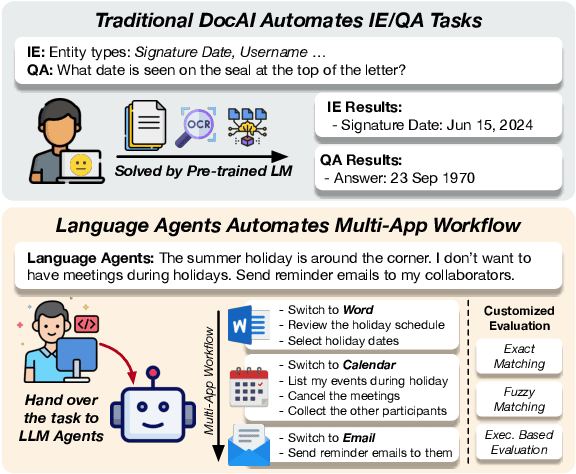

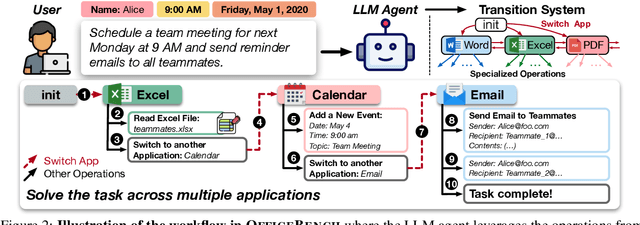
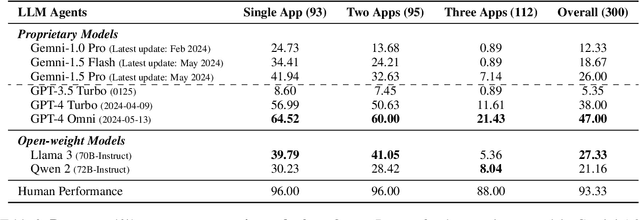
Office automation significantly enhances human productivity by automatically finishing routine tasks in the workflow. Beyond the basic information extraction studied in much of the prior document AI literature, the office automation research should be extended to more realistic office tasks which require to integrate various information sources in the office system and produce outputs through a series of decision-making processes. We introduce OfficeBench, one of the first office automation benchmarks for evaluating current LLM agents' capability to address office tasks in realistic office workflows. OfficeBench requires LLM agents to perform feasible long-horizon planning, proficiently switch between applications in a timely manner, and accurately ground their actions within a large combined action space, based on the contextual demands of the workflow. Applying our customized evaluation methods on each task, we find that GPT-4 Omni achieves the highest pass rate of 47.00%, demonstrating a decent performance in handling office tasks. However, this is still far below the human performance and accuracy standards required by real-world office workflows. We further observe that most issues are related to operation redundancy and hallucinations, as well as limitations in switching between multiple applications, which may provide valuable insights for developing effective agent frameworks for office automation.
Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
Jul 11, 2024Retrieval augmented generation (RAG) combines the generative abilities of large language models (LLMs) with external knowledge sources to provide more accurate and up-to-date responses. Recent RAG advancements focus on improving retrieval outcomes through iterative LLM refinement or self-critique capabilities acquired through additional instruction tuning of LLMs. In this work, we introduce Speculative RAG - a framework that leverages a larger generalist LM to efficiently verify multiple RAG drafts produced in parallel by a smaller, distilled specialist LM. Each draft is generated from a distinct subset of retrieved documents, offering diverse perspectives on the evidence while reducing input token counts per draft. This approach enhances comprehension of each subset and mitigates potential position bias over long context. Our method accelerates RAG by delegating drafting to the smaller specialist LM, with the larger generalist LM performing a single verification pass over the drafts. Extensive experiments demonstrate that Speculative RAG achieves state-of-the-art performance with reduced latency on TriviaQA, MuSiQue, PubHealth, and ARC-Challenge benchmarks. It notably enhances accuracy by up to 12.97% while reducing latency by 51% compared to conventional RAG systems on PubHealth.
Open-world Multi-label Text Classification with Extremely Weak Supervision
Jul 08, 2024We study open-world multi-label text classification under extremely weak supervision (XWS), where the user only provides a brief description for classification objectives without any labels or ground-truth label space. Similar single-label XWS settings have been explored recently, however, these methods cannot be easily adapted for multi-label. We observe that (1) most documents have a dominant class covering the majority of content and (2) long-tail labels would appear in some documents as a dominant class. Therefore, we first utilize the user description to prompt a large language model (LLM) for dominant keyphrases of a subset of raw documents, and then construct a (initial) label space via clustering. We further apply a zero-shot multi-label classifier to locate the documents with small top predicted scores, so we can revisit their dominant keyphrases for more long-tail labels. We iterate this process to discover a comprehensive label space and construct a multi-label classifier as a novel method, X-MLClass. X-MLClass exhibits a remarkable increase in ground-truth label space coverage on various datasets, for example, a 40% improvement on the AAPD dataset over topic modeling and keyword extraction methods. Moreover, X-MLClass achieves the best end-to-end multi-label classification accuracy.
When is the consistent prediction likely to be a correct prediction?
Jul 08, 2024Self-consistency (Wang et al., 2023) suggests that the most consistent answer obtained through large language models (LLMs) is more likely to be correct. In this paper, we challenge this argument and propose a nuanced correction. Our observations indicate that consistent answers derived through more computation i.e. longer reasoning texts, rather than simply the most consistent answer across all outputs, are more likely to be correct. This is predominantly because we demonstrate that LLMs can autonomously produce chain-of-thought (CoT) style reasoning with no custom prompts merely while generating longer responses, which lead to consistent predictions that are more accurate. In the zero-shot setting, by sampling Mixtral-8x7B model multiple times and considering longer responses, we achieve 86% of its self-consistency performance obtained through zero-shot CoT prompting on the GSM8K and MultiArith datasets. Finally, we demonstrate that the probability of LLMs generating a longer response is quite low, highlighting the need for decoding strategies conditioned on output length.
AI-native Memory: A Pathway from LLMs Towards AGI
Jun 26, 2024
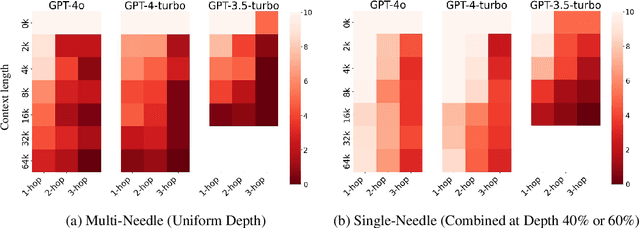

Large language models (LLMs) have demonstrated the world with the sparks of artificial general intelligence (AGI). One opinion, especially from some startups working on LLMs, argues that an LLM with nearly unlimited context length can realize AGI. However, they might be too optimistic about the long-context capability of (existing) LLMs -- (1) Recent literature has shown that their effective context length is significantly smaller than their claimed context length; and (2) Our reasoning-in-a-haystack experiments further demonstrate that simultaneously finding the relevant information from a long context and conducting (simple) reasoning is nearly impossible. In this paper, we envision a pathway from LLMs to AGI through the integration of \emph{memory}. We believe that AGI should be a system where LLMs serve as core processors. In addition to raw data, the memory in this system would store a large number of important conclusions derived from reasoning processes. Compared with retrieval-augmented generation (RAG) that merely processing raw data, this approach not only connects semantically related information closer, but also simplifies complex inferences at the time of querying. As an intermediate stage, the memory will likely be in the form of natural language descriptions, which can be directly consumed by users too. Ultimately, every agent/person should have its own large personal model, a deep neural network model (thus \emph{AI-native}) that parameterizes and compresses all types of memory, even the ones cannot be described by natural languages. Finally, we discuss the significant potential of AI-native memory as the transformative infrastructure for (proactive) engagement, personalization, distribution, and social in the AGI era, as well as the incurred privacy and security challenges with preliminary solutions.
Data Contamination Can Cross Language Barriers
Jun 19, 2024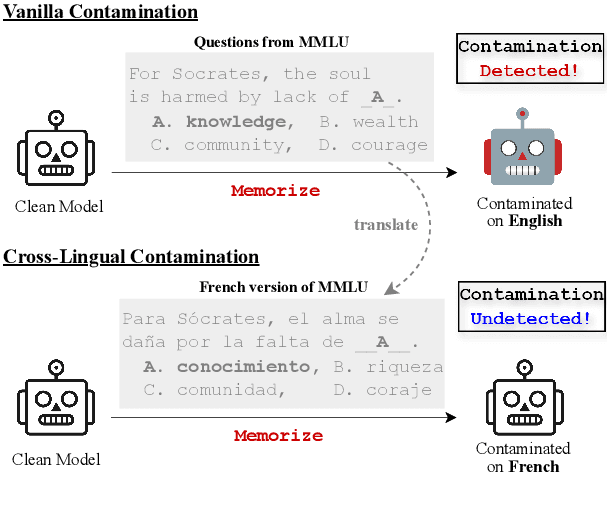
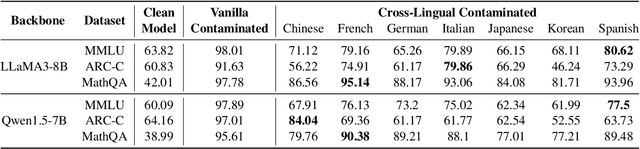
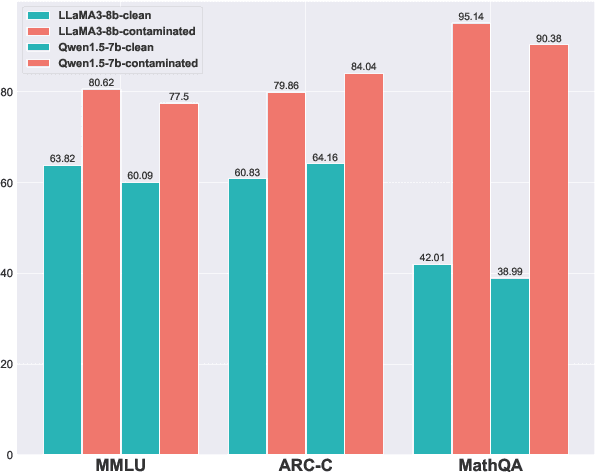
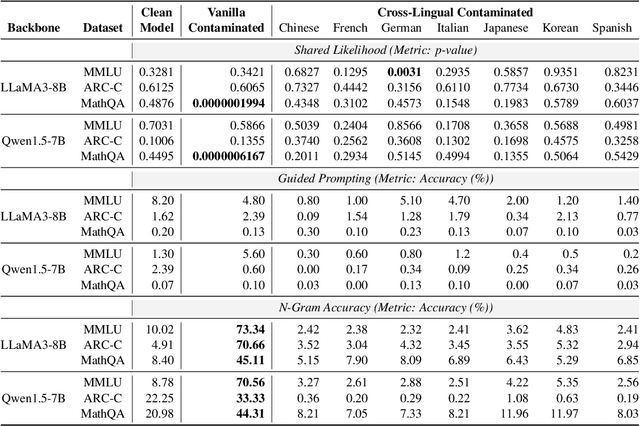
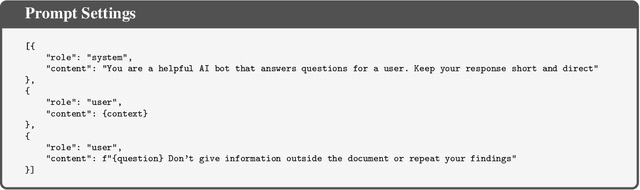
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be \emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from \url{https://github.com/ShangDataLab/Deep-Contam}.
Text Grafting: Near-Distribution Weak Supervision for Minority Classes in Text Classification
Jun 17, 2024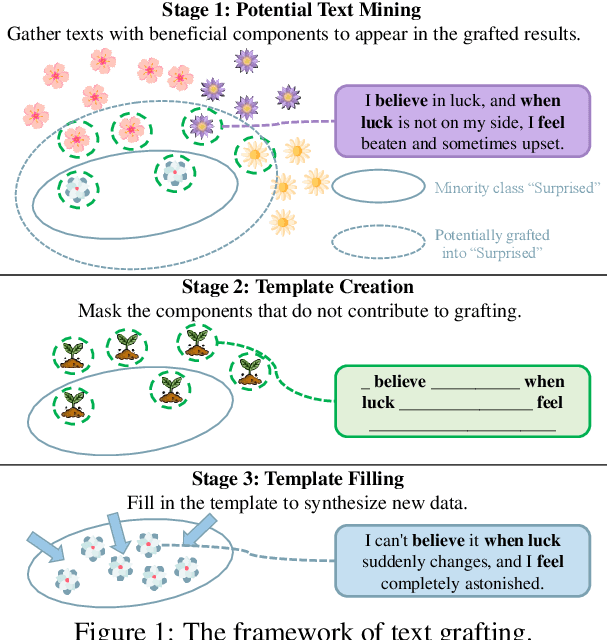
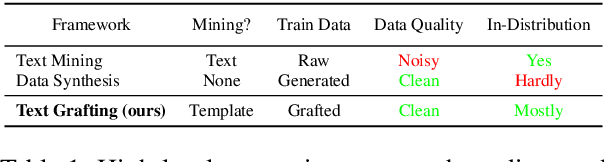
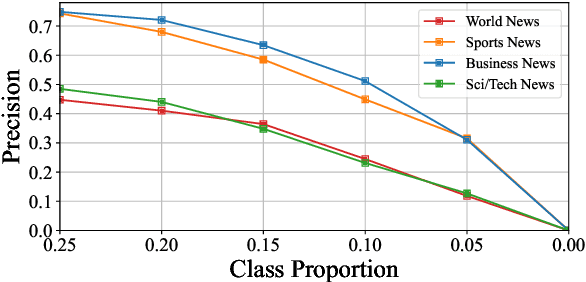

For extremely weak-supervised text classification, pioneer research generates pseudo labels by mining texts similar to the class names from the raw corpus, which may end up with very limited or even no samples for the minority classes. Recent works have started to generate the relevant texts by prompting LLMs using the class names or definitions; however, there is a high risk that LLMs cannot generate in-distribution (i.e., similar to the corpus where the text classifier will be applied) data, leading to ungeneralizable classifiers. In this paper, we combine the advantages of these two approaches and propose to bridge the gap via a novel framework, \emph{text grafting}, which aims to obtain clean and near-distribution weak supervision for minority classes. Specifically, we first use LLM-based logits to mine masked templates from the raw corpus, which have a high potential for data synthesis into the target minority class. Then, the templates are filled by state-of-the-art LLMs to synthesize near-distribution texts falling into minority classes. Text grafting shows significant improvement over direct mining or synthesis on minority classes. We also use analysis and case studies to comprehend the property of text grafting.
Evaluating the Smooth Control of Attribute Intensity in Text Generation with LLMs
Jun 06, 2024
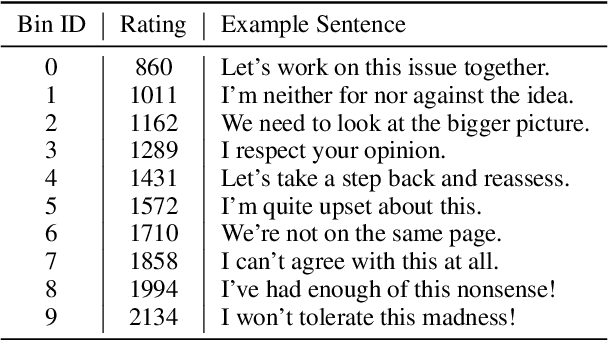
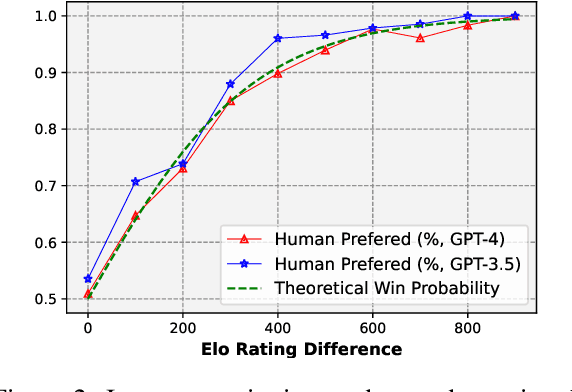
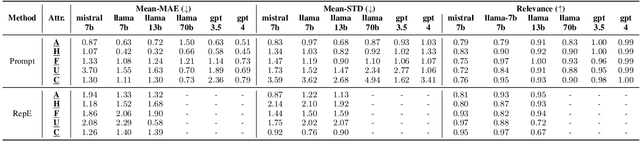
Controlling the attribute intensity of text generation is crucial across scenarios (e.g., writing conciseness, chatting emotion, and explanation clarity). The remarkable capabilities of large language models (LLMs) have revolutionized text generation, prompting us to explore such \emph{smooth control} of LLM generation. Specifically, we propose metrics to assess the range, calibration, and consistency of the generated text's attribute intensity in response to varying control values, as well as its relevance to the intended context. To quantify the attribute intensity and context relevance, we propose an effective evaluation framework leveraging the Elo rating system and GPT4, both renowned for their robust alignment with human judgment. We look into two viable training-free methods for achieving smooth control of LLMs: (1) Prompting with semantic shifters, and (2) Modifying internal model representations. The evaluations of these two methods are conducted on $5$ different attributes with various models. Our code and dataset can be obtained from \url{https://github.com/ShangDataLab/Smooth-Control}.